

Building Models of Functional Interactions Among Brain Domains that Encode Varying Information Complexity: A Schizophrenia Case Study
- PMID: 35267145
- PMCID: PMC9463406
- DOI: 10.1007/s12021-022-09563-w
Building Models of Functional Interactions Among Brain Domains that Encode Varying Information Complexity: A Schizophrenia Case Study
Abstract
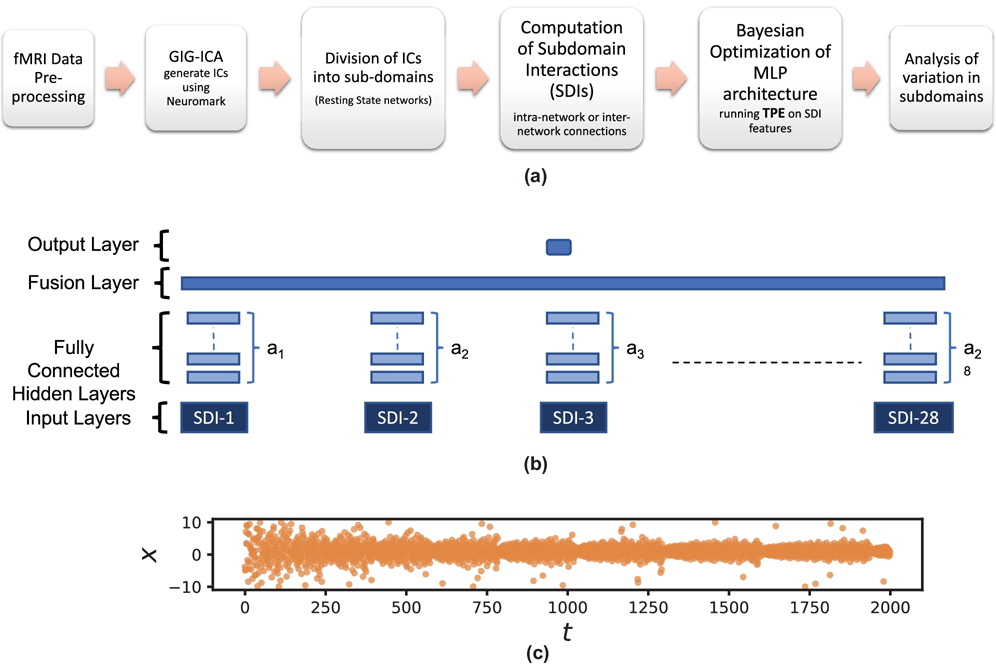
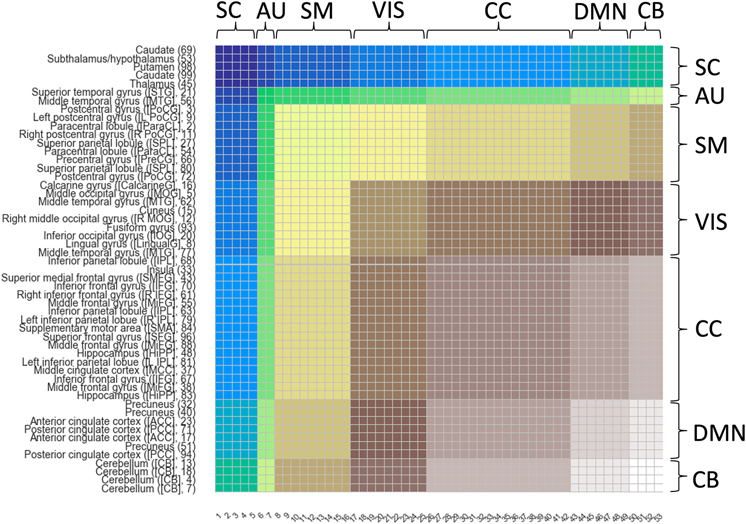
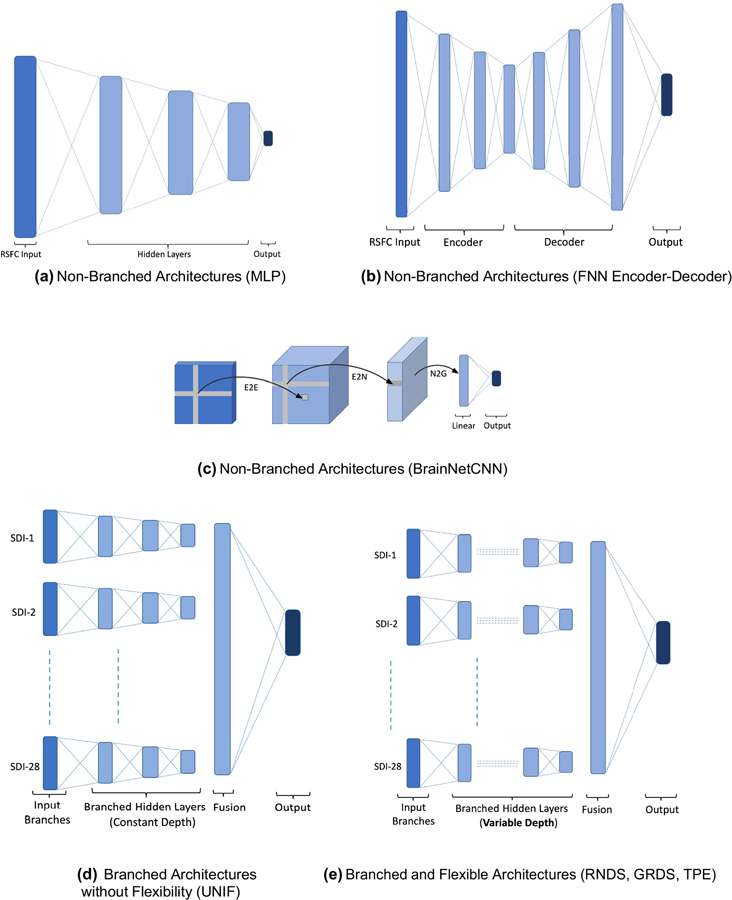
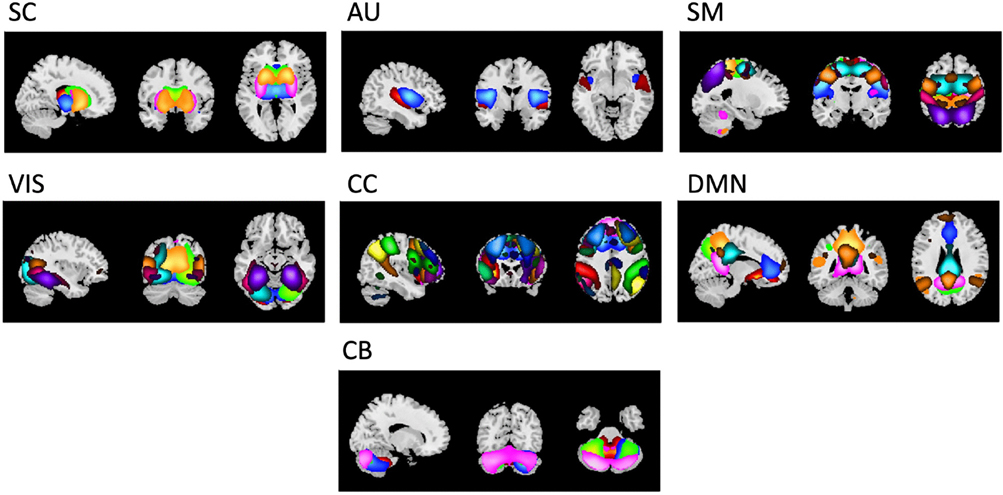
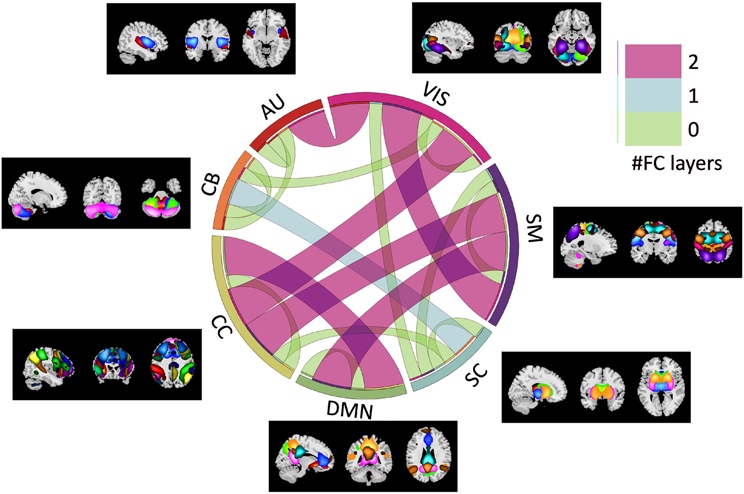
Revealing associations among various structural and functional patterns of the brain can yield highly informative results about the healthy and disordered brain. Studies using neuroimaging data have more recently begun to utilize the information within as well as across various functional and anatomical domains (i.e., groups of brain networks). However, most whole-brain approaches assume similar complexity of interactions throughout the brain. Here we investigate the hypothesis that interactions between brain networks capture varying amounts of complexity, and that we can better capture this information by varying the complexity of the model subspace structure based on available training data. To do this, we employ a Bayesian optimization-based framework known as the Tree Parzen Estimator (TPE) to identify, exploit and analyze patterns of variation in the information encoded by temporal information extracted from functional magnetic resonance imaging (fMRI) subdomains of the brain. Using a repeated cross-validation procedure on a schizophrenia classification task, we demonstrate evidence that interactions between specific functional subdomains are better characterized by more sophisticated model architectures compared to less complicated ones required by the others for optimally contributing towards classification and understanding the brain's functional interactions. We show that functional subdomains known to be involved in schizophrenia require more complex architectures to optimally unravel discriminatory information about the disorder. Our study points to the need for adaptive, hierarchical learning frameworks that cater differently to the features from different subdomains, not only for a better prediction but also for enabling the identification of features predicting the outcome of interest.
Keywords: Bayesian optimization; Functional connectivity; Hyperparameter optimization; Multilayer perceptron; Schizophrenia; Subdomain analysis; fMRI.
© 2022. The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature.
Figures
Similar articles
-
Multi-model order spatially constrained ICA reveals highly replicable group differences and consistent predictive results from resting data: A large N fMRI schizophrenia study.Neuroimage Clin. 2023;38:103434. doi: 10.1016/j.nicl.2023.103434. Epub 2023 May 17. Neuroimage Clin. 2023. PMID: 37209635 Free PMC article.
-
Predicting individual brain functional connectivity using a Bayesian hierarchical model.Neuroimage. 2017 Feb 15;147:772-787. doi: 10.1016/j.neuroimage.2016.11.048. Epub 2016 Dec 1. Neuroimage. 2017. PMID: 27915121 Free PMC article.
-
Examining resting-state functional connectivity in first-episode schizophrenia with 7T fMRI and MEG.Neuroimage Clin. 2019;24:101959. doi: 10.1016/j.nicl.2019.101959. Epub 2019 Jul 23. Neuroimage Clin. 2019. PMID: 31377556 Free PMC article.
-
Schizophrenia, neuroimaging and connectomics.Neuroimage. 2012 Oct 1;62(4):2296-314. doi: 10.1016/j.neuroimage.2011.12.090. Epub 2012 Feb 24. Neuroimage. 2012. PMID: 22387165 Review.
-
A meta-analysis and systematic review of single vs. multimodal neuroimaging techniques in the classification of psychosis.Mol Psychiatry. 2023 Aug;28(8):3278-3292. doi: 10.1038/s41380-023-02195-9. Epub 2023 Aug 10. Mol Psychiatry. 2023. PMID: 37563277 Free PMC article.
References
-
- Bergstra J, Yamins D, and Cox DD (2013a). Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in science conference, pages 13–20. Citeseer.
-
- Bergstra J, Yamins D, and Cox DD (2013b). Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In International Conference on Machine Learning.
-
- Bergstra JS, Bardenet R, Bengio Y, and Kegl B (2011). Algorithms for hyper-parameter optimization. pages 2546–2554.
