

OpenCell: Endogenous tagging for the cartography of human cellular organization
- PMID: 35271311
- PMCID: PMC9119736
- DOI: 10.1126/science.abi6983
OpenCell: Endogenous tagging for the cartography of human cellular organization
Abstract
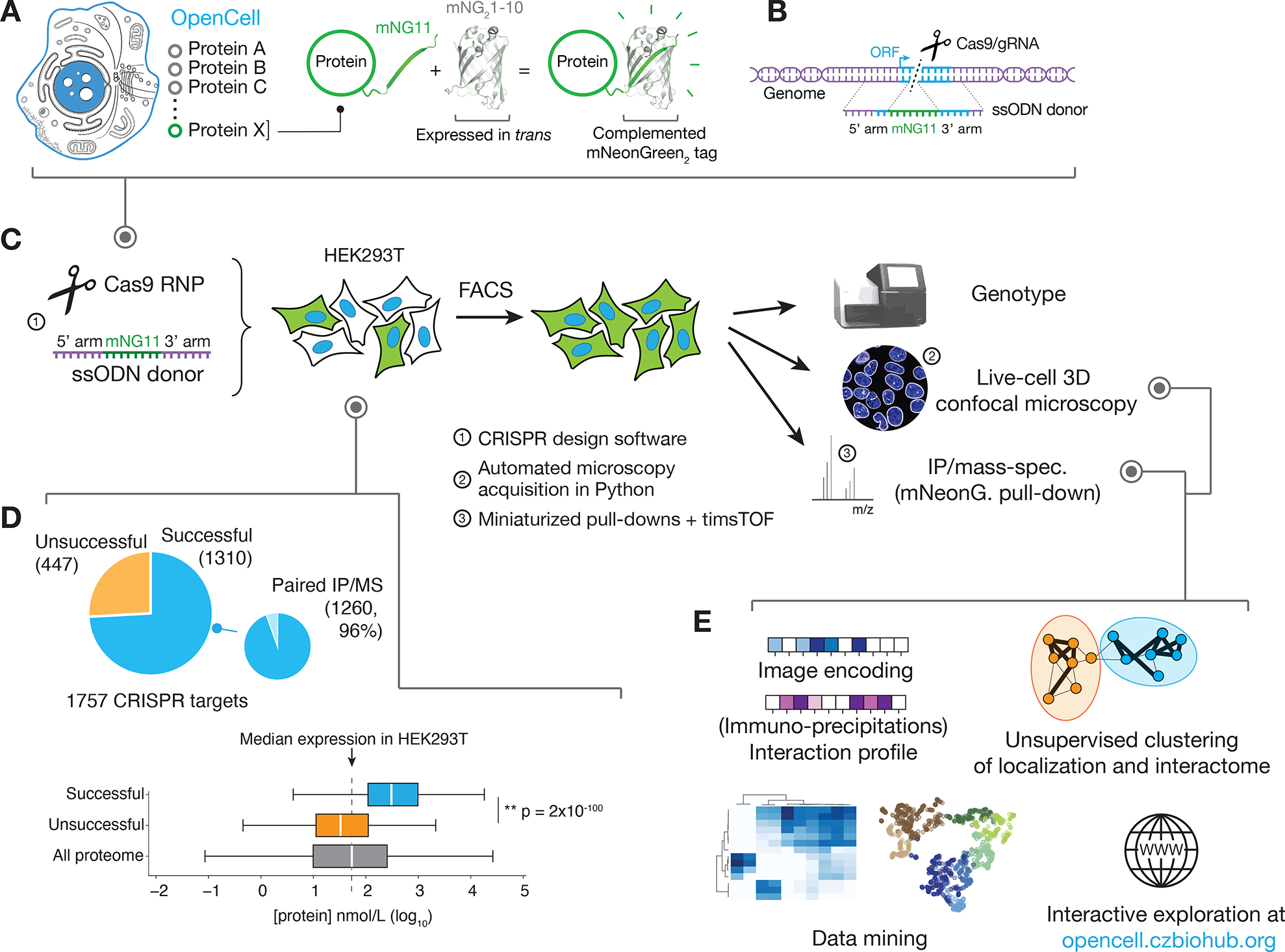
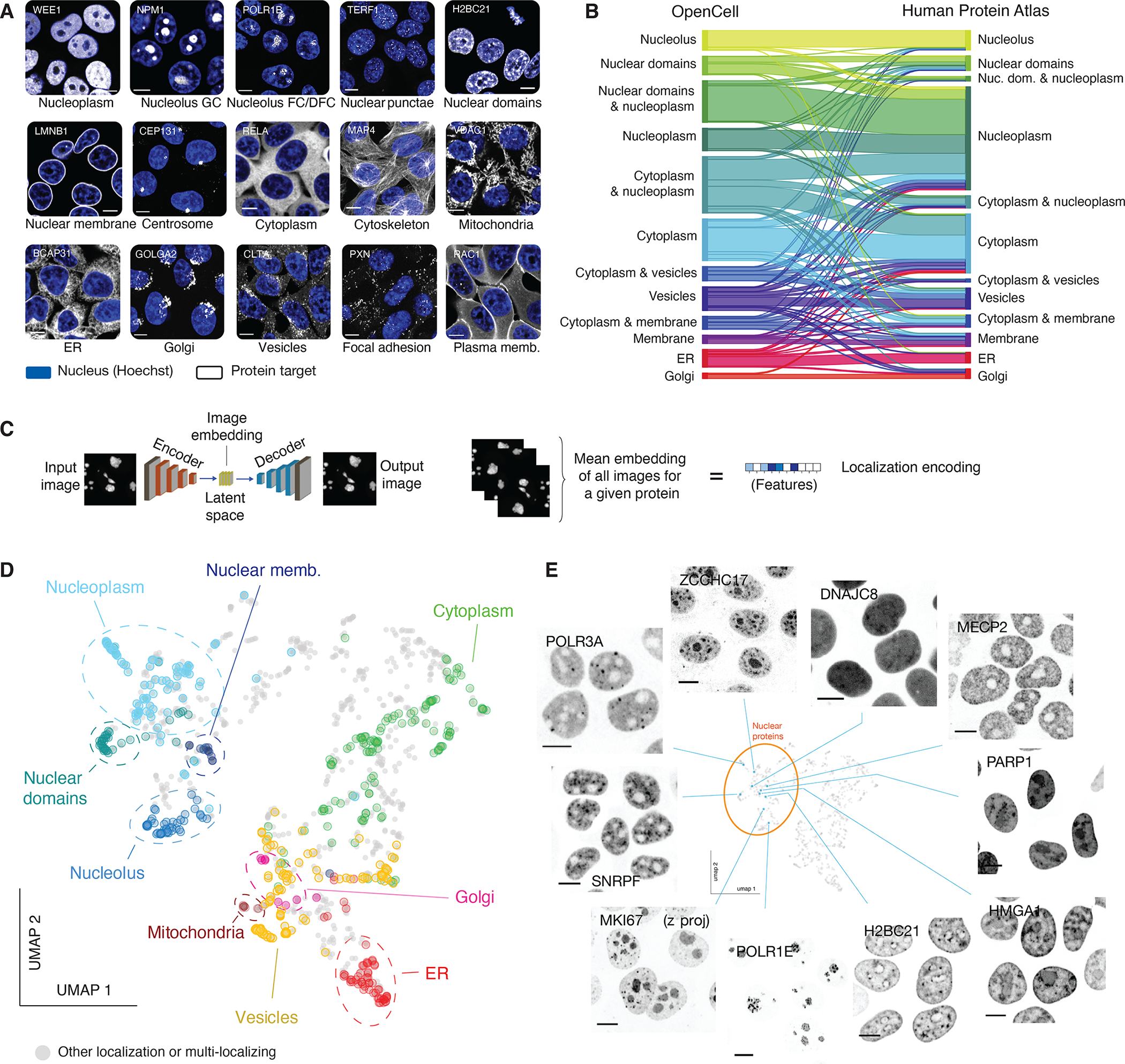
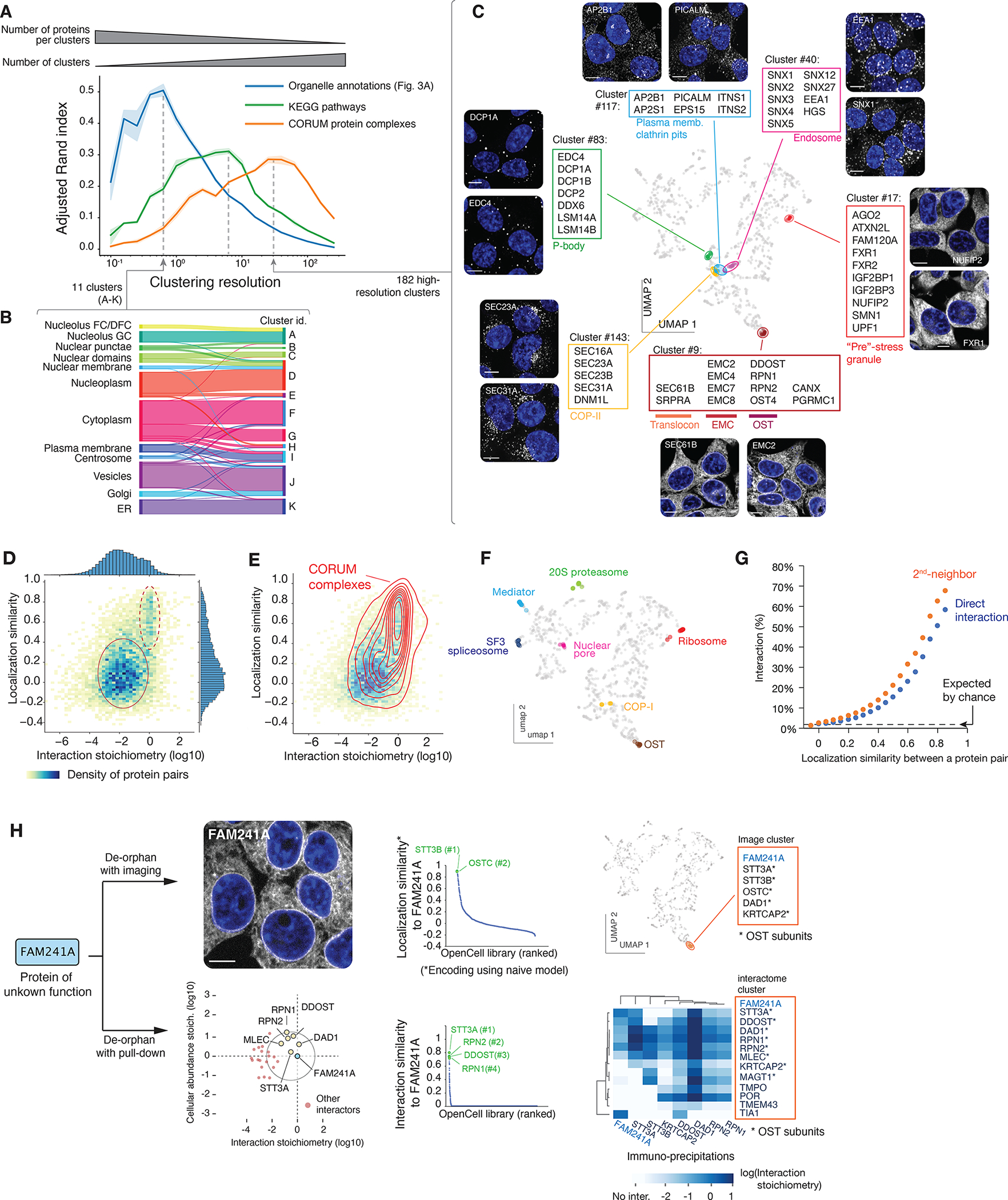
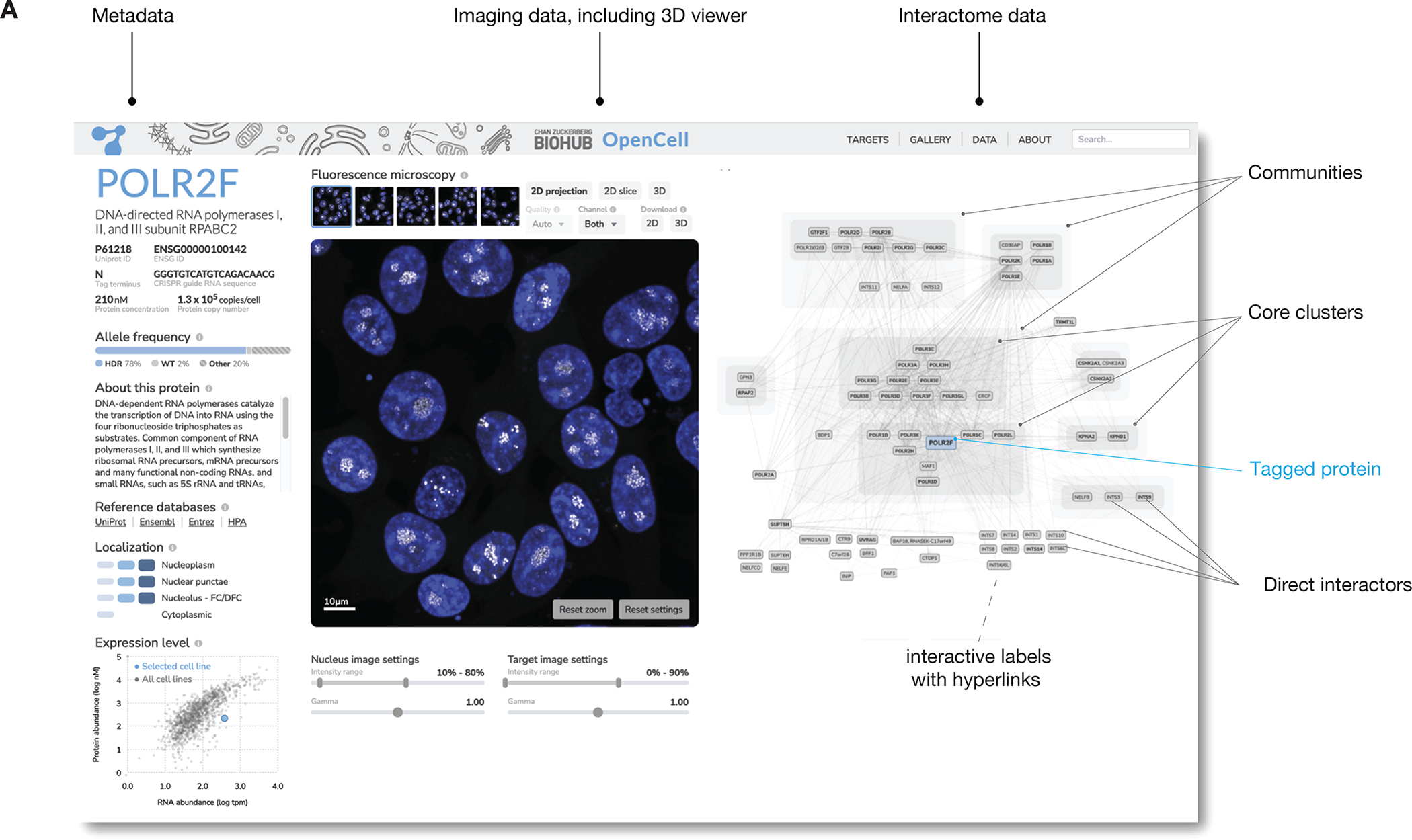
Elucidating the wiring diagram of the human cell is a central goal of the postgenomic era. We combined genome engineering, confocal live-cell imaging, mass spectrometry, and data science to systematically map the localization and interactions of human proteins. Our approach provides a data-driven description of the molecular and spatial networks that organize the proteome. Unsupervised clustering of these networks delineates functional communities that facilitate biological discovery. We found that remarkably precise functional information can be derived from protein localization patterns, which often contain enough information to identify molecular interactions, and that RNA binding proteins form a specific subgroup defined by unique interaction and localization properties. Paired with a fully interactive website (opencell.czbiohub.org), our work constitutes a resource for the quantitative cartography of human cellular organization.
Conflict of interest statement
Figures


Comment in
-
The modular cell gets connected.Science. 2022 Mar 11;375(6585):1093-1094. doi: 10.1126/science.abo2360. Epub 2022 Mar 10. Science. 2022. PMID: 35271323
References
-
- Consortium IHGS, Finishing the euchromatic sequence of the human genome. Nature. 431, 931–945 (2004). - PubMed
-
- Nurse P, Hayles J, The Cell in an Era of Systems Biology. Cell. 144, 850–854 (2011). - PubMed
-
- Lundberg E, Borner GHH, Spatial proteomics: a powerful discovery tool for cell biology. Nature Reviews Molecular Cell Biology. 20, 285–302 (2019). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
