

Progress and challenges for the machine learning-based design of fit-for-purpose monoclonal antibodies
- PMID: 35293269
- PMCID: PMC8928824
- DOI: 10.1080/19420862.2021.2008790
Progress and challenges for the machine learning-based design of fit-for-purpose monoclonal antibodies
Abstract
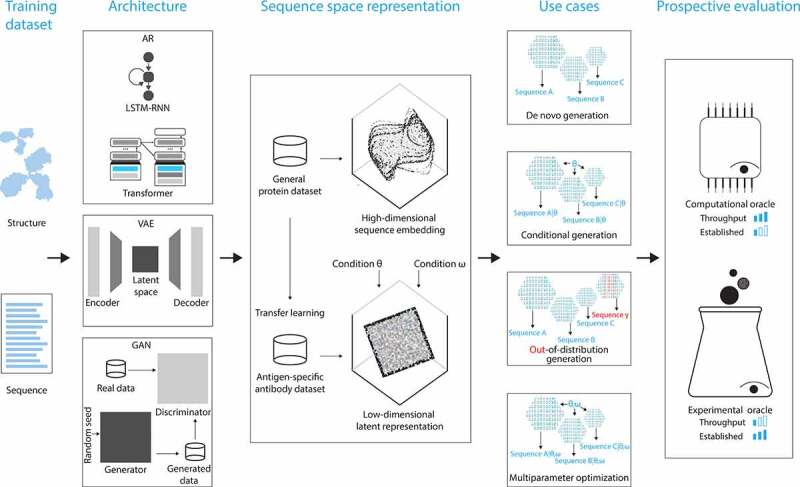
Although the therapeutic efficacy and commercial success of monoclonal antibodies (mAbs) are tremendous, the design and discovery of new candidates remain a time and cost-intensive endeavor. In this regard, progress in the generation of data describing antigen binding and developability, computational methodology, and artificial intelligence may pave the way for a new era of in silico on-demand immunotherapeutics design and discovery. Here, we argue that the main necessary machine learning (ML) components for an in silico mAb sequence generator are: understanding of the rules of mAb-antigen binding, capacity to modularly combine mAb design parameters, and algorithms for unconstrained parameter-driven in silico mAb sequence synthesis. We review the current progress toward the realization of these necessary components and discuss the challenges that must be overcome to allow the on-demand ML-based discovery and design of fit-for-purpose mAb therapeutic candidates.
Keywords: Machine learning; antibody; antigen; artificial intelligence; developability; drug design.
Conflict of interest statement
V.G. declares advisory board positions in aiNET GmbH and Enpicom B.V.G. is a consultant for Roche/Genentech.
Figures




References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources