

Detection of ovarian cancer via the spectral fingerprinting of quantum-defect-modified carbon nanotubes in serum by machine learning
- PMID: 35301449
- PMCID: PMC9108893
- DOI: 10.1038/s41551-022-00860-y
Detection of ovarian cancer via the spectral fingerprinting of quantum-defect-modified carbon nanotubes in serum by machine learning
Abstract
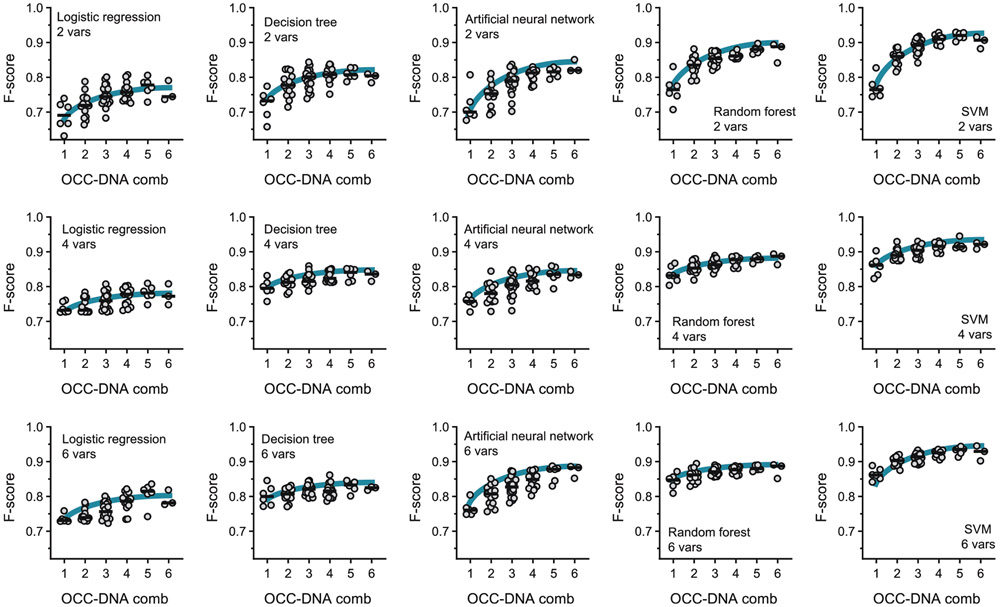
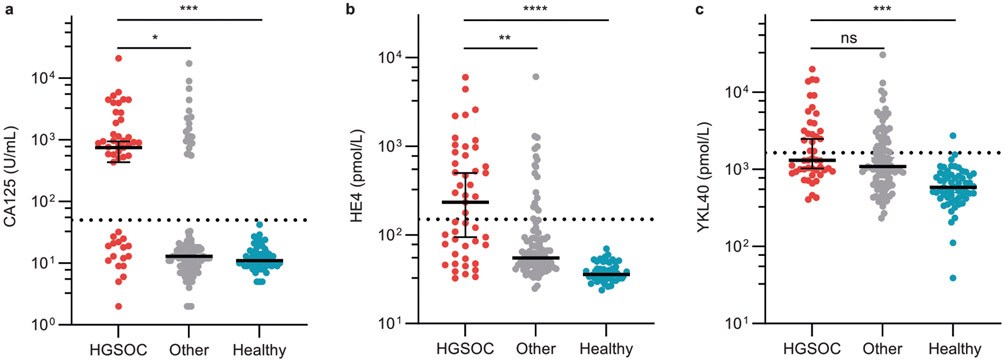
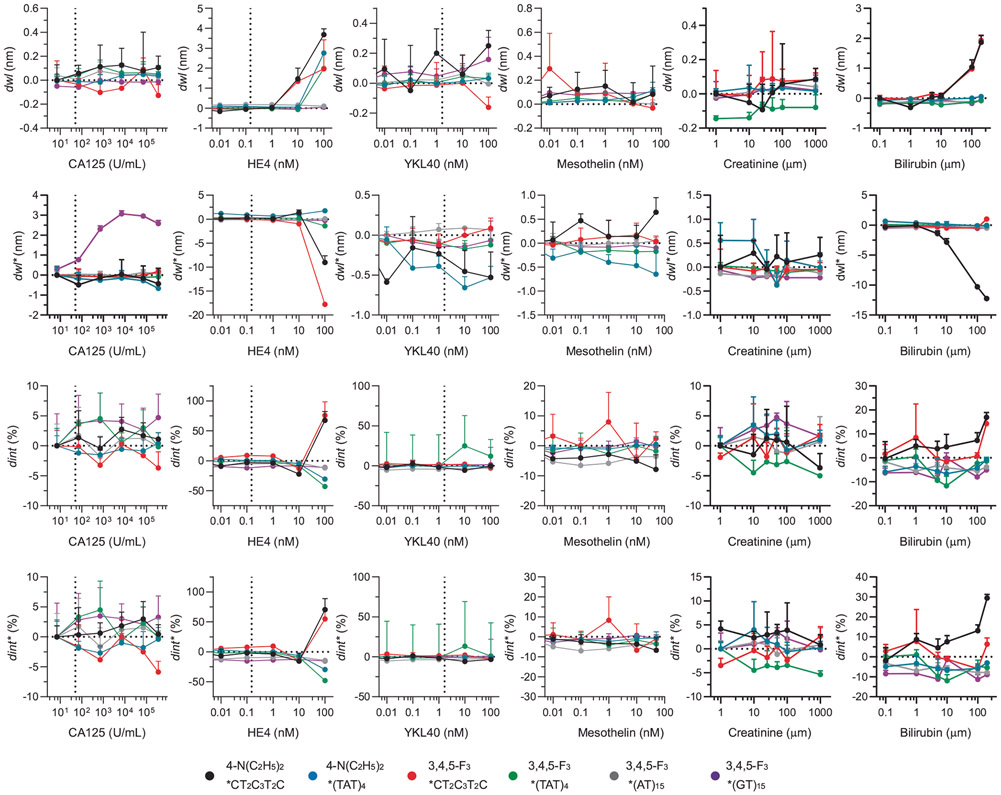
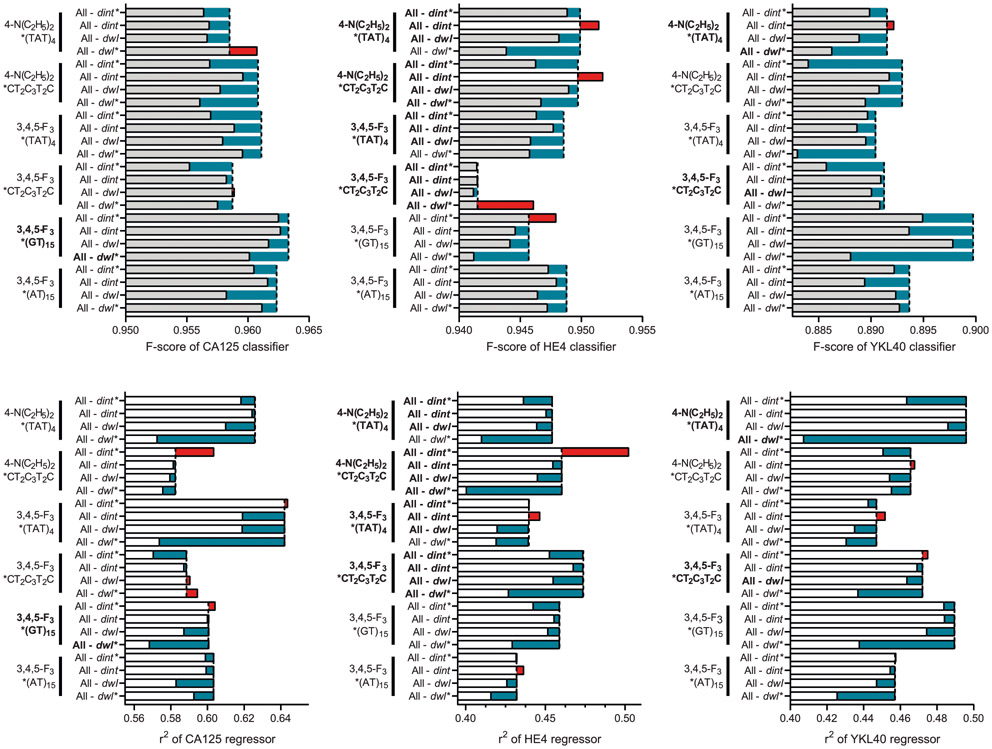
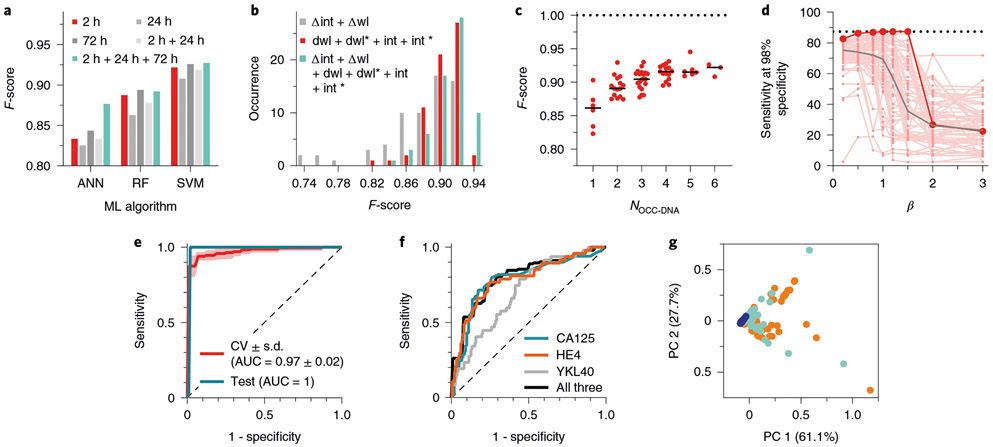
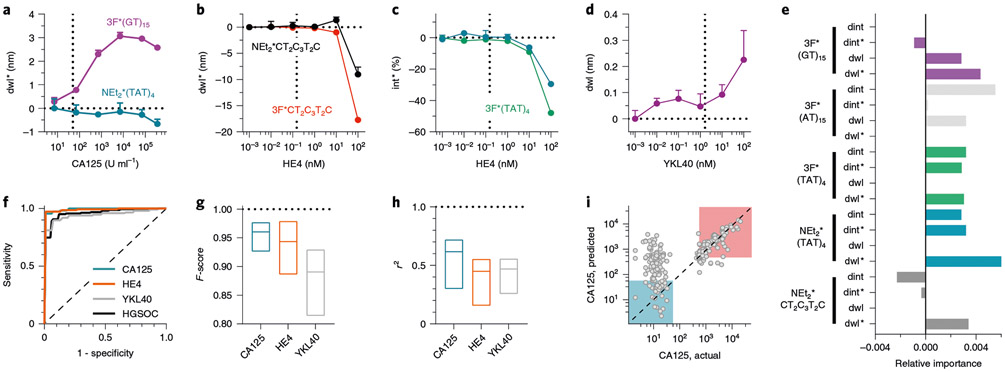
Serum biomarkers are often insufficiently sensitive or specific to facilitate cancer screening or diagnostic testing. In ovarian cancer, the few established serum biomarkers are highly specific, yet insufficiently sensitive to detect early-stage disease and to impact the mortality rates of patients with this cancer. Here we show that a 'disease fingerprint' acquired via machine learning from the spectra of near-infrared fluorescence emissions of an array of carbon nanotubes functionalized with quantum defects detects high-grade serous ovarian carcinoma in serum samples from symptomatic individuals with 87% sensitivity at 98% specificity (compared with 84% sensitivity at 98% specificity for the current best clinical screening test, which uses measurements of cancer antigen 125 and transvaginal ultrasonography). We used 269 serum samples to train and validate several machine-learning classifiers for the discrimination of patients with ovarian cancer from those with other diseases and from healthy individuals. The predictive values of the best classifier could not be attained via known protein biomarkers, suggesting that the array of nanotube sensors responds to unidentified serum biomarkers.
© 2022. The Author(s), under exclusive licence to Springer Nature Limited.
Figures






References
-
- Bray F et al. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin 68, 394–424 (2018). - PubMed
-
- Siegel RL, Miller KD & Jemal A Cancer statistics, 2020. CA Cancer J. Clin 70, 7–30 (2020). - PubMed
-
- Dupont J et al. Early detection and prognosis of ovarian cancer using serum YKL-40. J. Clin. Oncol 22, 3330–3339 (2004). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
