

Detection of Vocal Fold Image Obstructions in High-Speed Videoendoscopy During Connected Speech in Adductor Spasmodic Dysphonia: A Convolutional Neural Networks Approach
- PMID: 35304042
- PMCID: PMC9474736
- DOI: 10.1016/j.jvoice.2022.01.028
Detection of Vocal Fold Image Obstructions in High-Speed Videoendoscopy During Connected Speech in Adductor Spasmodic Dysphonia: A Convolutional Neural Networks Approach
Abstract
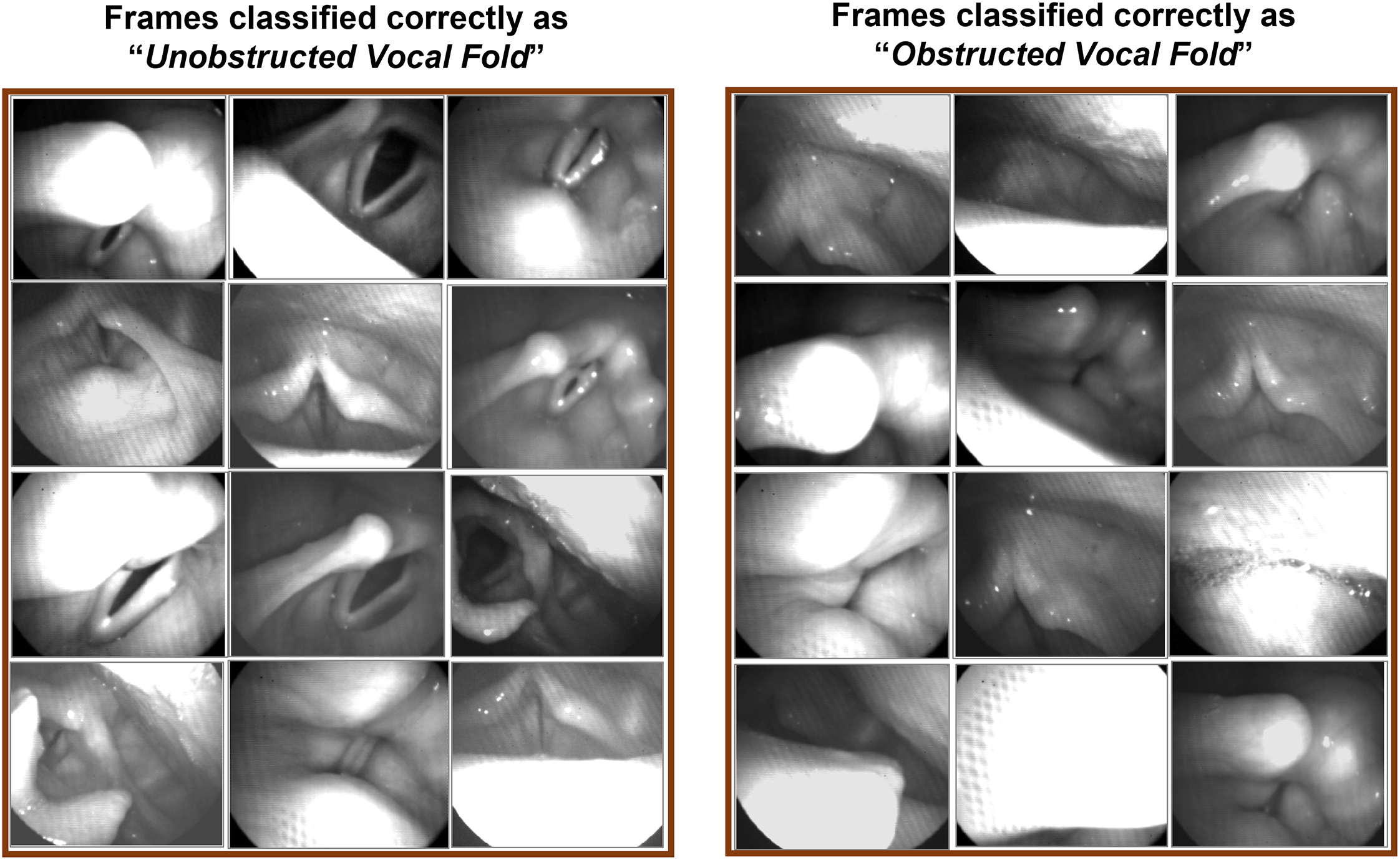
Objective: Adductor spasmodic dysphonia (AdSD) is a neurogenic voice disorder, affecting the intrinsic laryngeal muscle control. AdSD leads to involuntary laryngeal spasms and only reveals during connected speech. Laryngeal high-speed videoendoscopy (HSV) coupled with a flexible fiberoptic endoscope provides a unique opportunity to study voice production and visualize the vocal fold vibrations in AdSD during speech. The goal of this study is to automatically detect instances during which the image of the vocal folds is optically obstructed in HSV recordings obtained during connected speech.
Methods: HSV data were recorded from vocally normal adults and patients with AdSD during reading of the "Rainbow Passage", six CAPE-V sentences, and production of the vowel /i/. A convolutional neural network was developed and trained as a classifier to detect obstructed/unobstructed vocal folds in HSV frames. Manually labelled data were used for training, validating, and testing of the network. Moreover, a comprehensive robustness evaluation was conducted to compare the performance of the developed classifier and visual analysis of HSV data.
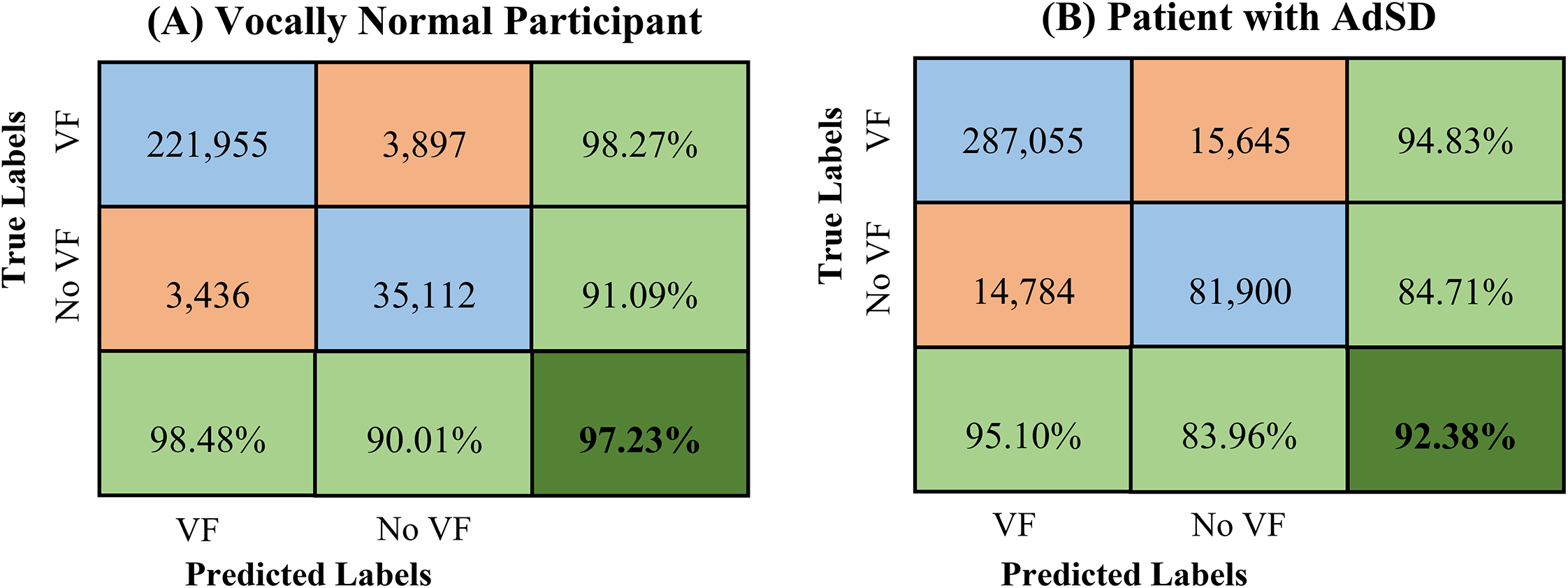
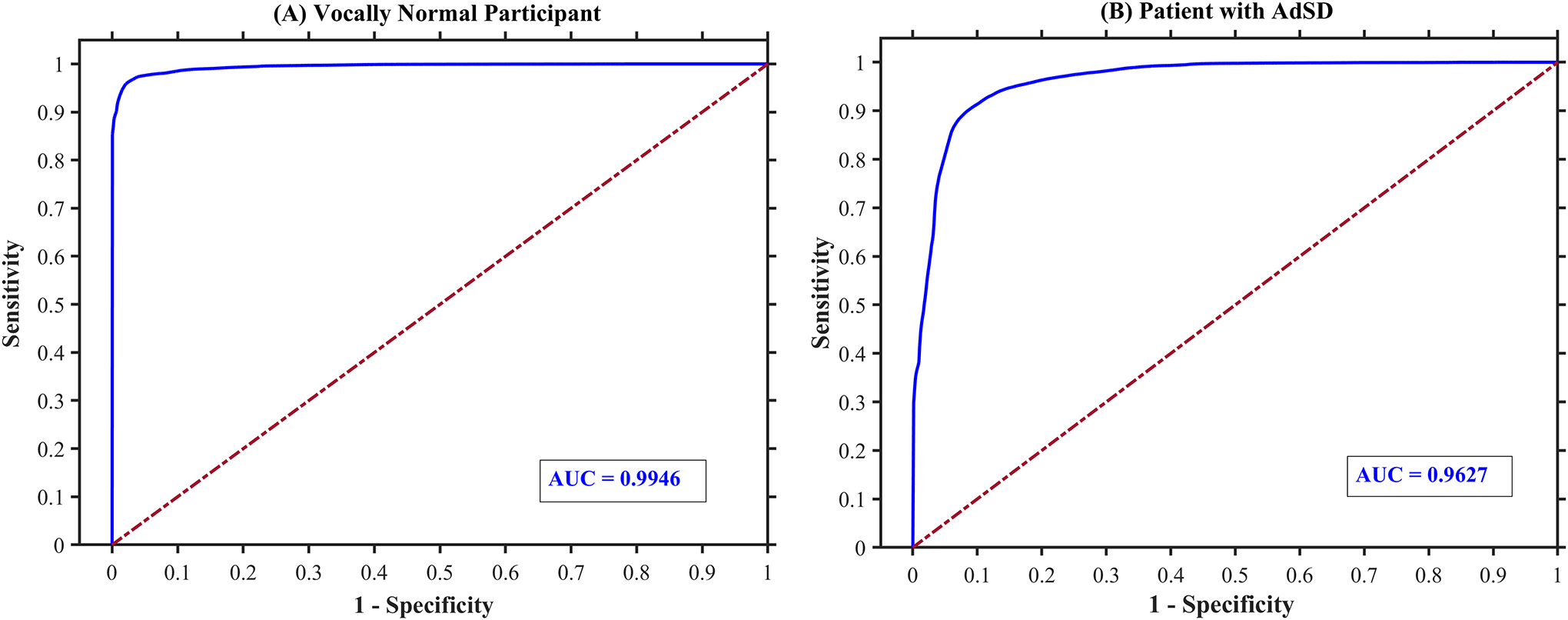
Results: The developed convolutional neural network was able to automatically detect the vocal fold obstructions in HSV data in vocally normal participants and AdSD patients. The trained network was tested successfully and showed an overall classification accuracy of 94.18% on the testing dataset. The robustness evaluation showed an average overall accuracy of 94.81% on a massive number of HSV frames demonstrating the high robustness of the introduced technique while keeping a high level of accuracy.
Conclusions: The proposed approach can be used for efficient analysis of HSV data to study laryngeal maneuvers in patients with AdSD during connected speech. Additionally, this method will facilitate development of vocal fold vibratory measures for HSV frames with an unobstructed view of the vocal folds. Indicating parts of connected speech that provide an unobstructed view of the vocal folds can be used for developing optimal passages for precise HSV examination during connected speech and subject-specific clinical voice assessment protocols.
Keywords: Laryngeal imaging—Connected speech—High-speed videoendoscopy—Adductor spasmodic dysphonia—Vocal fold obstruction—Convolutional neural network.
Copyright © 2022 The Voice Foundation. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no conflict of interest.
Figures





References
-
- Chetri DK, Merati AL, Blumin JH, Sulica L, Damrose EJ and Tsai VW, “Reliability of the perceptual evaluation of adductor spasmodic dysphonia,” An Otol Rhinol Laryngol, vol. 117, pp. 159–165, 2008. - PubMed
-
- Roy N, Gouse M, Mauszycki SC, Merrill RM and Smith ME, “Task specificity in adductor spasmodic dysphonia versus muscle tension dysphonia,” The Laryngoscope, vol. 115, no. 2, pp. 311–316, 2005. - PubMed
-
- Roy N, Mazin A and Awan SN, “Automated acoustic analysis of task dependency in adductor spasmodic dysphonia versus muscle tension dysphonia,” The Laryngoscope, vol. 124, no. 3, pp. 718–724, 2014. - PubMed
-
- Boutsen F, Cannito MP, Taylor M and Bender B, “Botox treatment in adductor spasmodic dysphonia: a meta-analysis,” J Sp Lang Hear Res, vol. 45, pp. 469–481, 2002. - PubMed
-
- Morrison MD and Rammage LA, “Muscle misuse voice disorders: description and classification,” Acta oto-laryngologica, vol. 113, no. 3, pp. 428–434, 1993. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
