

Outcome Prediction from Behaviour Change Intervention Evaluations using a Combination of Node and Word Embedding
- PMID: 35308987
- PMCID: PMC8861683
Outcome Prediction from Behaviour Change Intervention Evaluations using a Combination of Node and Word Embedding
Abstract
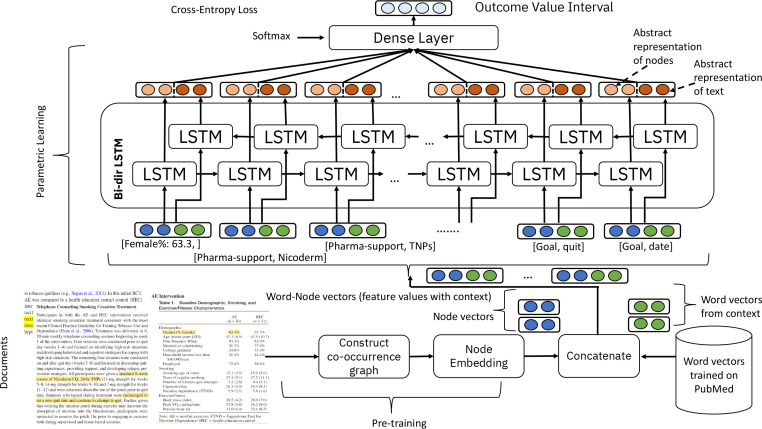
Findings from randomized controlled trials (RCTs) of behaviour change interventions encode much of our knowledge on intervention efficacy under defined conditions. Predicting outcomes of novel interventions in novel conditions can be challenging, as can predicting differences in outcomes between different interventions or different conditions. To predict outcomes from RCTs, we propose a generic framework of combining the information from two sources - i) the instances (comprised of surrounding text and their numeric values) of relevant attributes, namely the intervention, setting and population characteristics of a study, and ii) abstract representation of the categories of these attributes themselves. We demonstrate that this way of encoding both the information about an attribute and its value when used as an embedding layer within a standard deep sequence modeling setup improves the outcome prediction effectiveness.
©2021 AMIA - All rights reserved.
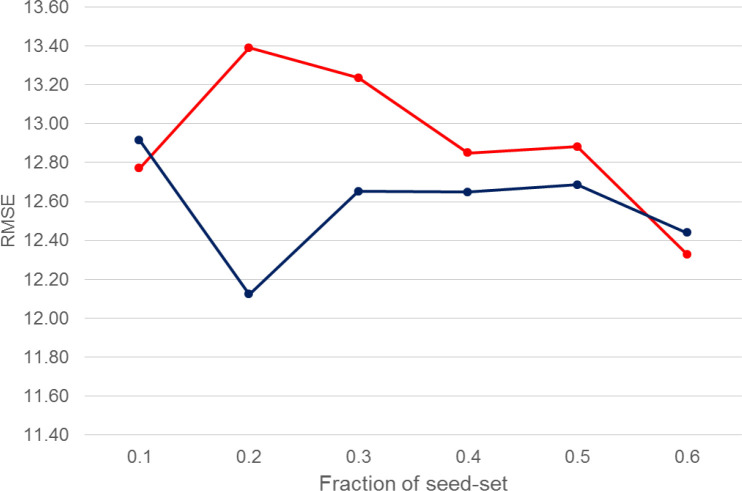
Figures
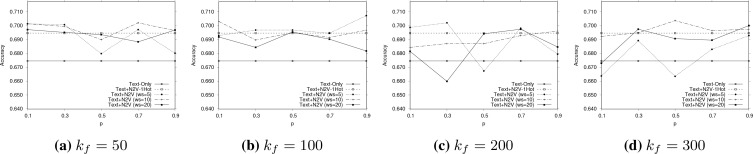
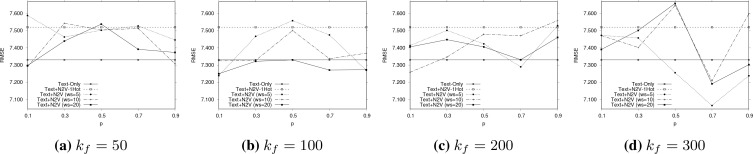
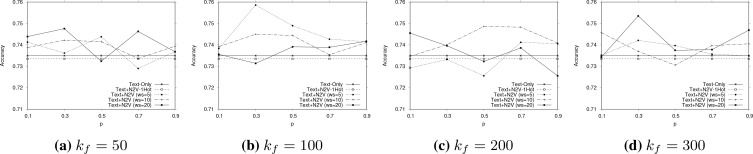
References
-
- Tsafnat G, Dunn A, Glasziou P, Coiera E. The automation of systematic reviews. BMJ (Clinical research ed) 2013;01:346. f139. - PubMed
-
- Zhou P, Shi W, Tian J, Qi Z, Li B, Hao H. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. Proc. of ACL’16. 2016:207–212.
-
- Xu J, Chen D, Qiu X, Huang X. Cached Long Short-Term Memory Neural Networks for Document-Level Sentiment Classification. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016:1660–1669.
-
- Zhou X, Wan X, Xiao J. Attention-based LSTM Network for Cross-Lingual Sentiment Classification. Proc. of EMNLP’16. 2016:247–256.
MeSH terms
LinkOut - more resources
Full Text Sources