

Deep learning-enabled assessment of cardiac allograft rejection from endomyocardial biopsies
- PMID: 35314822
- PMCID: PMC9353336
- DOI: 10.1038/s41591-022-01709-2
Deep learning-enabled assessment of cardiac allograft rejection from endomyocardial biopsies
Abstract
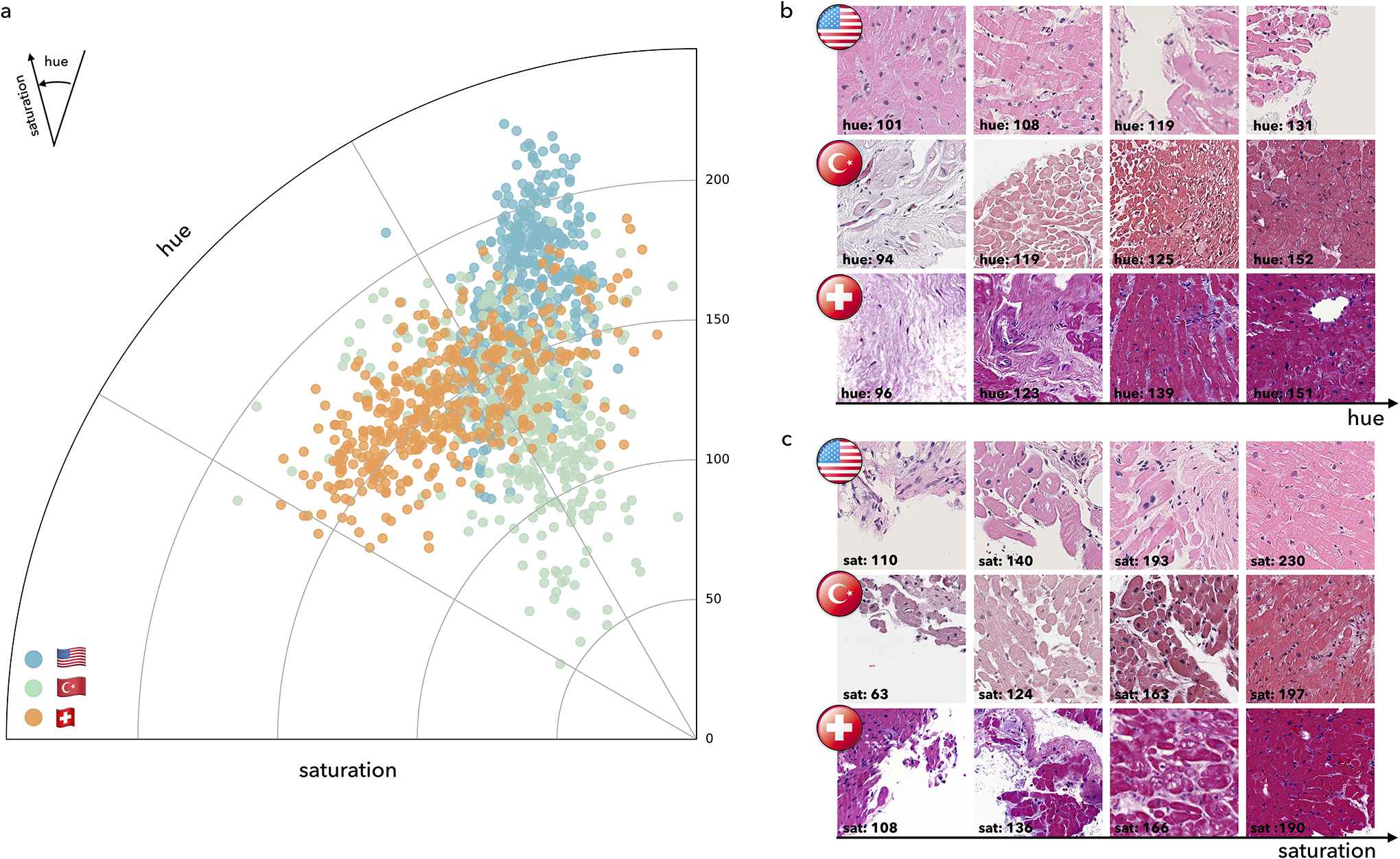
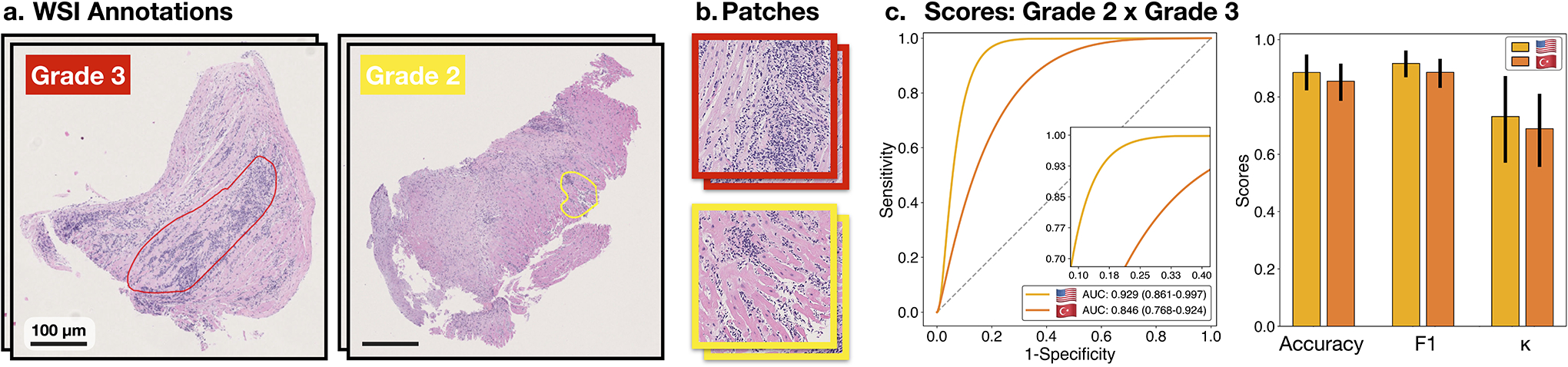
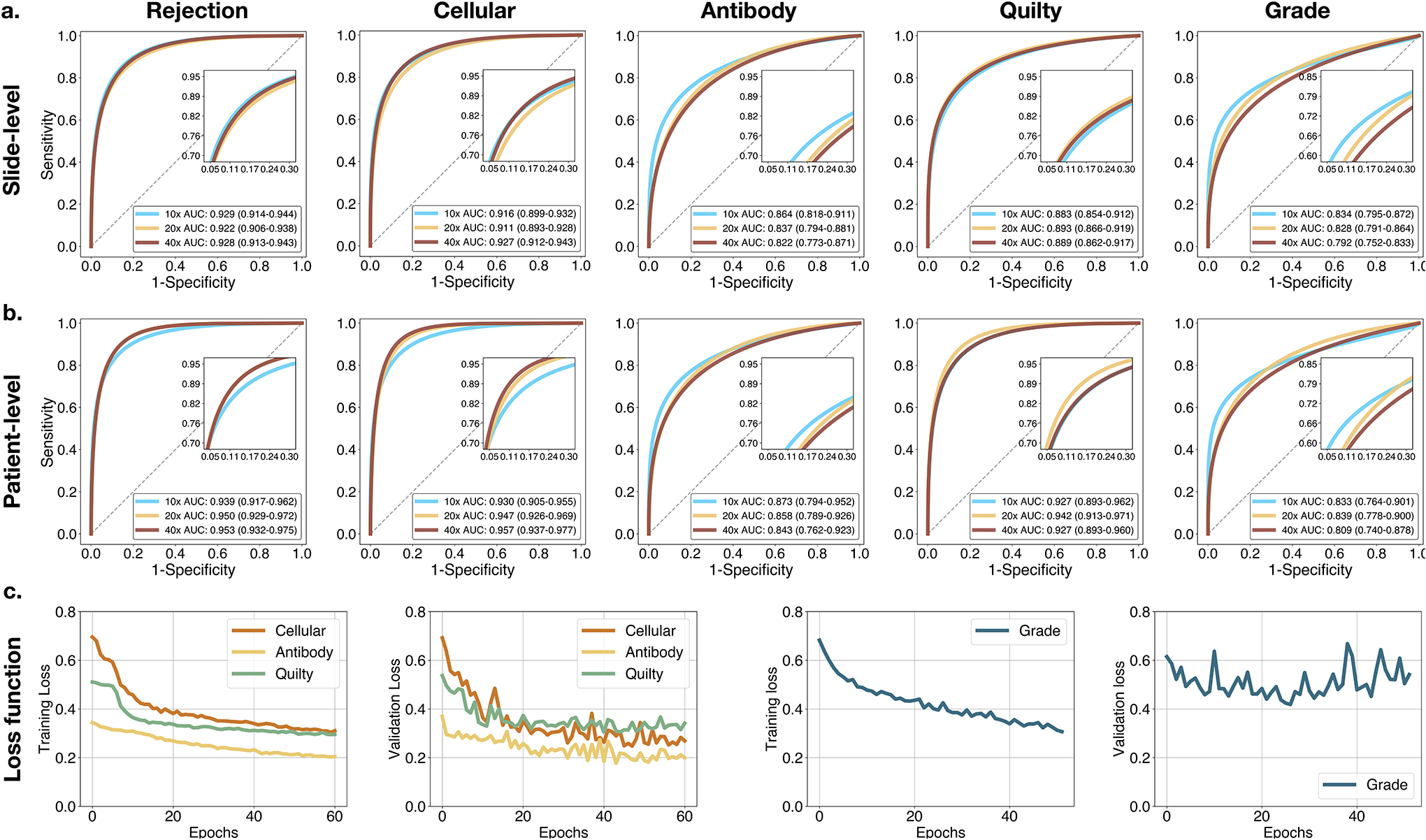
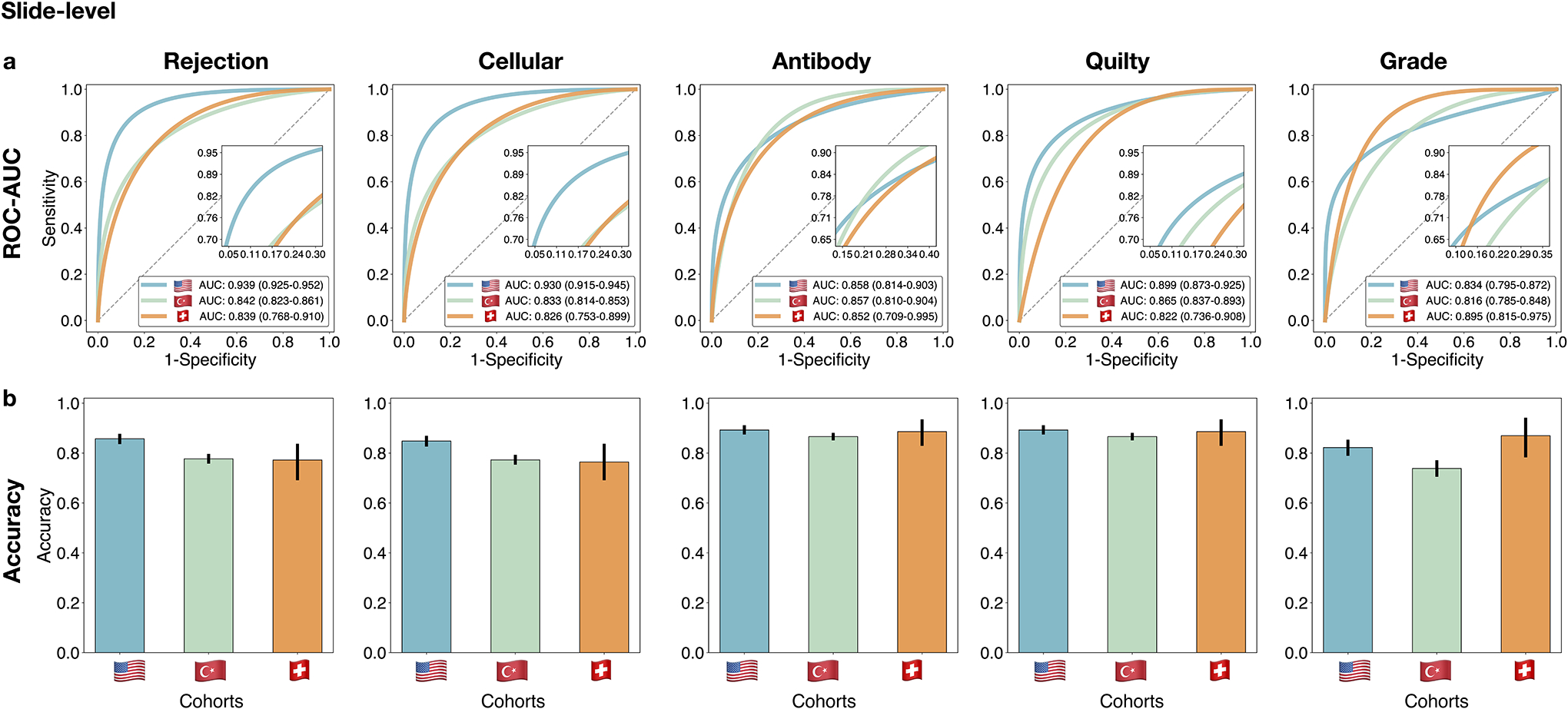
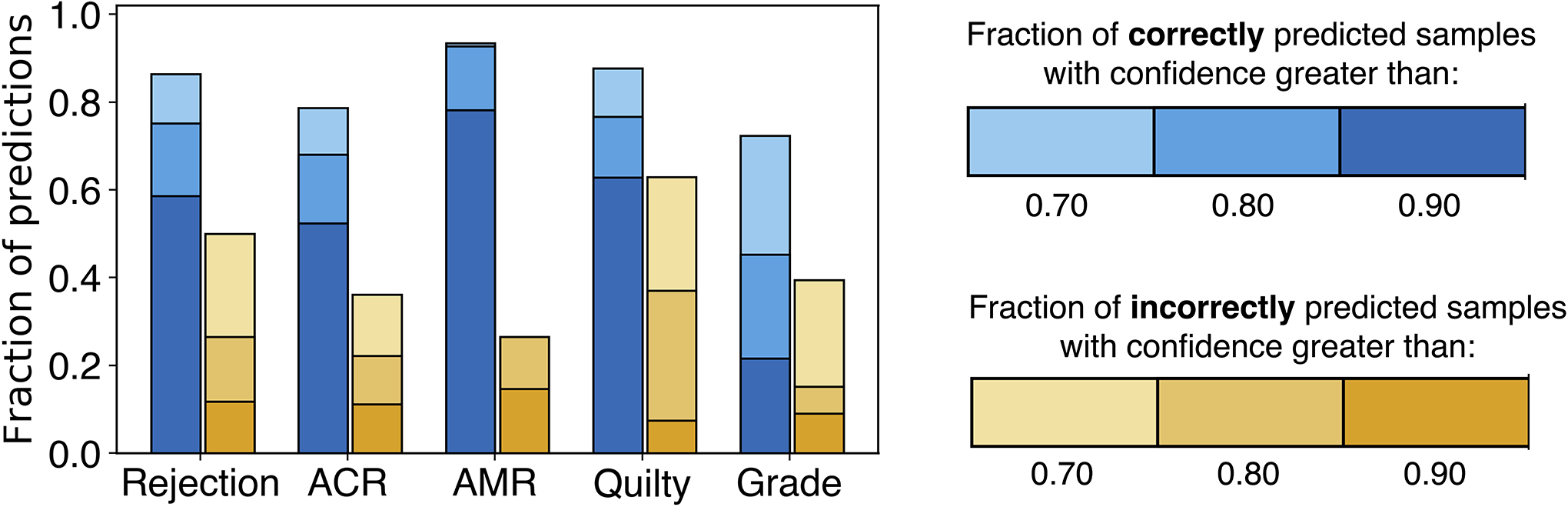
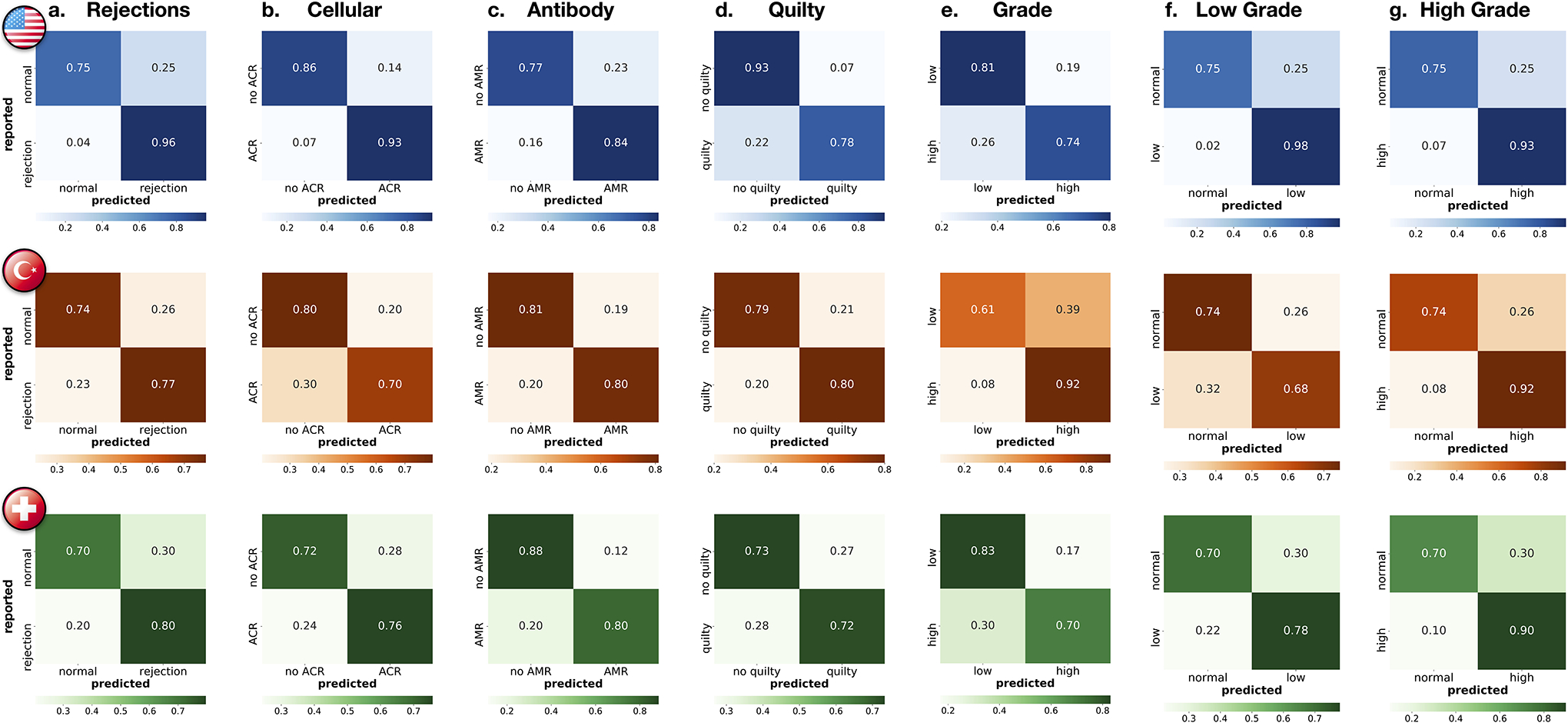
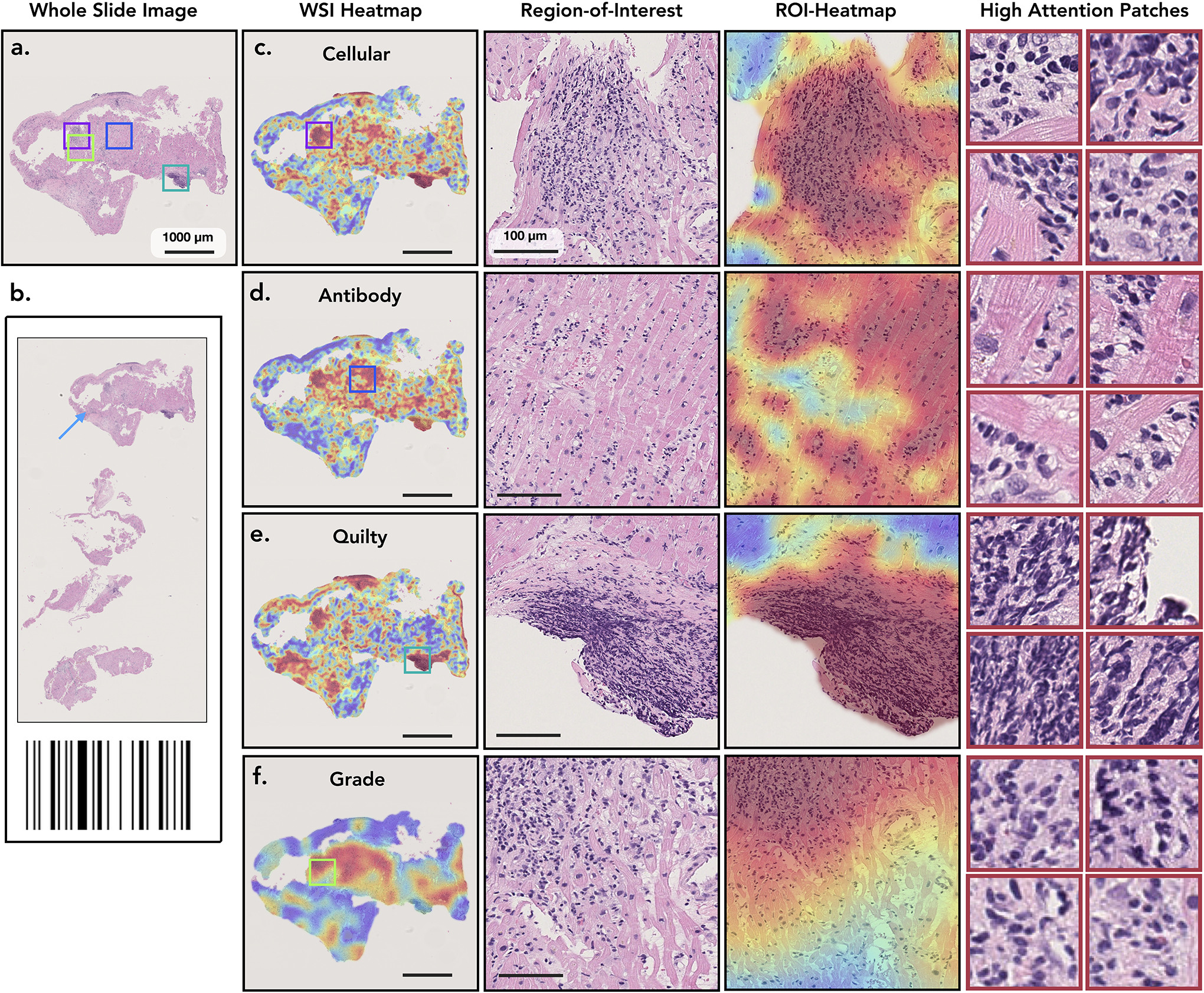
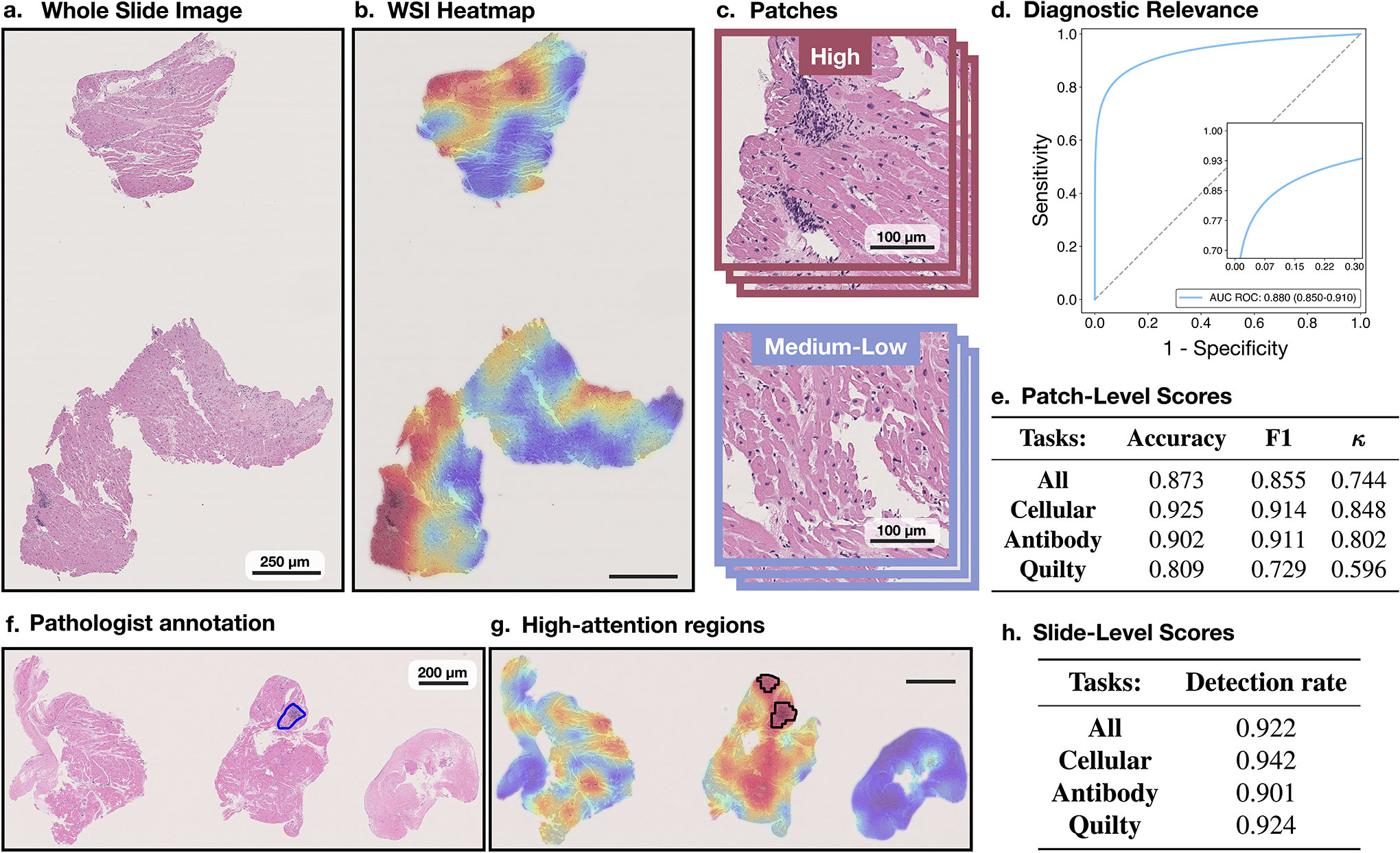
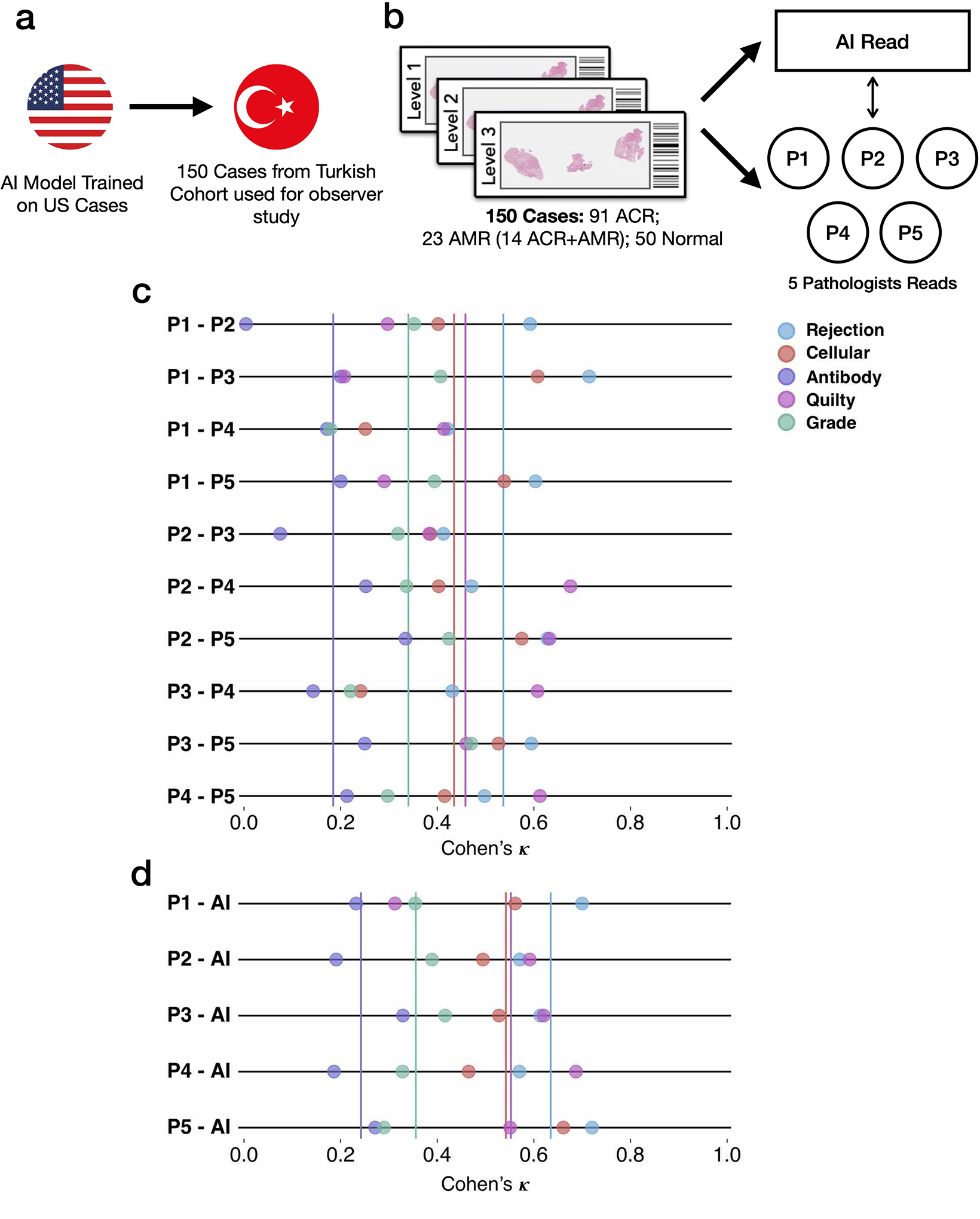
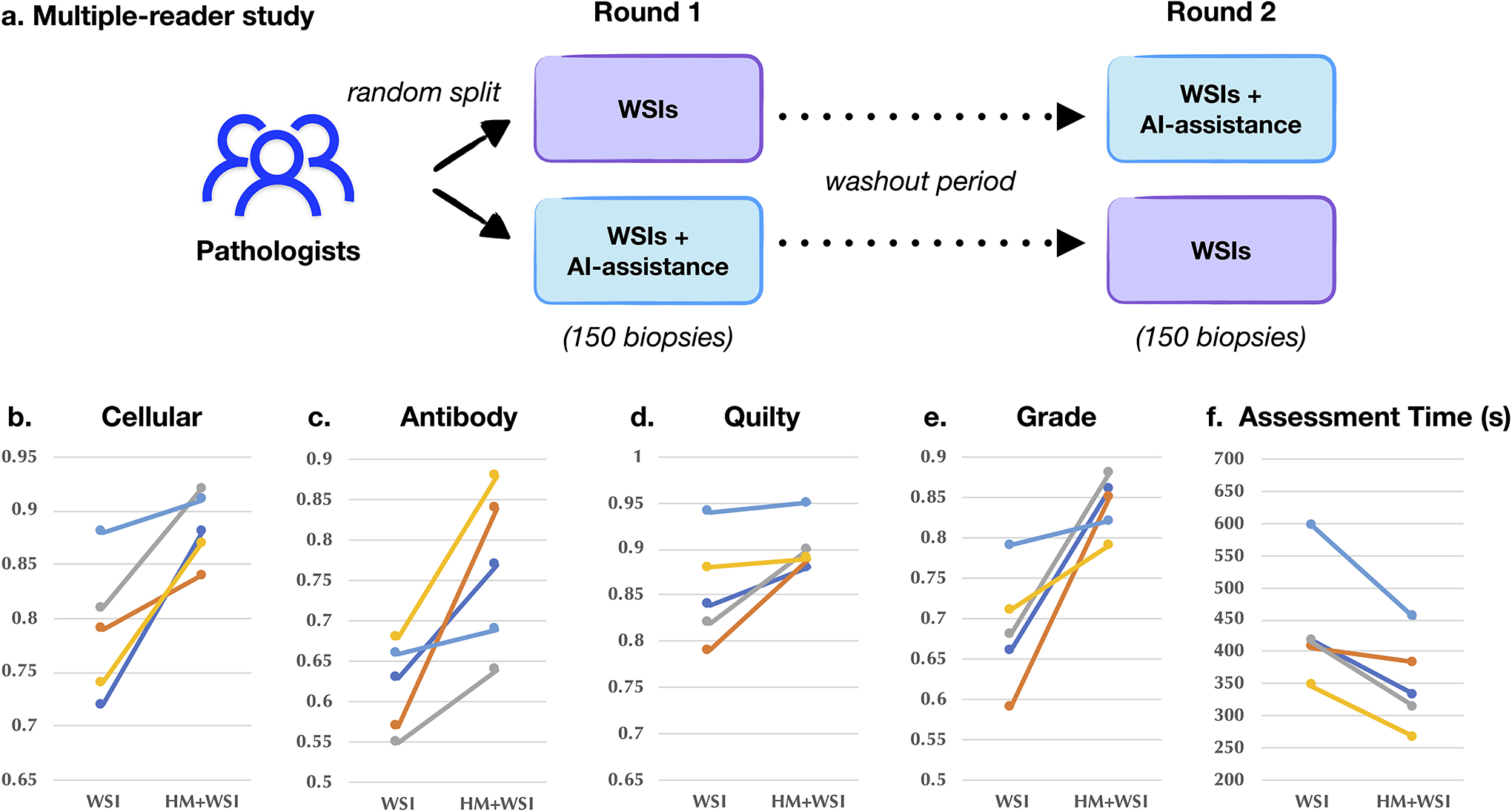
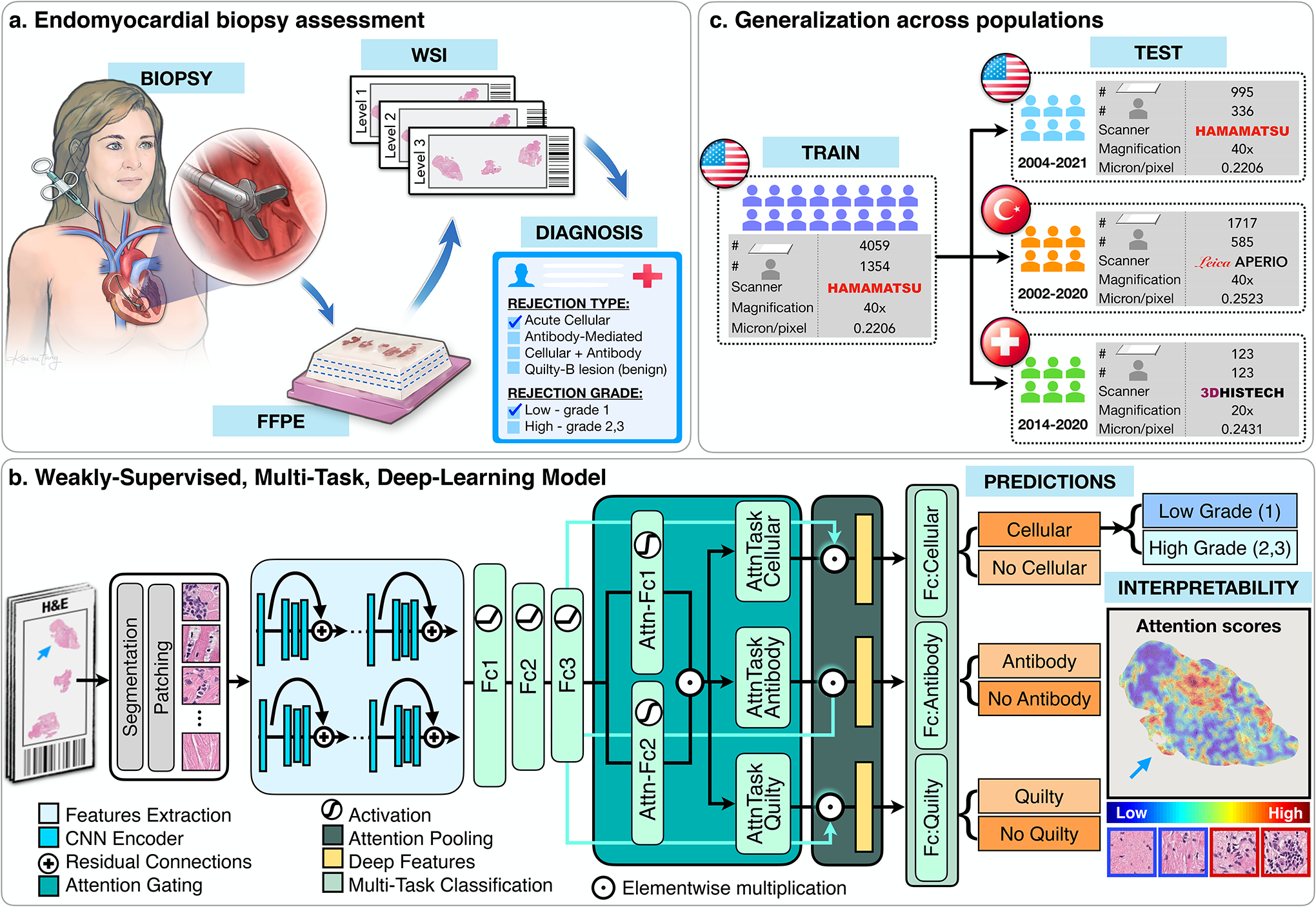
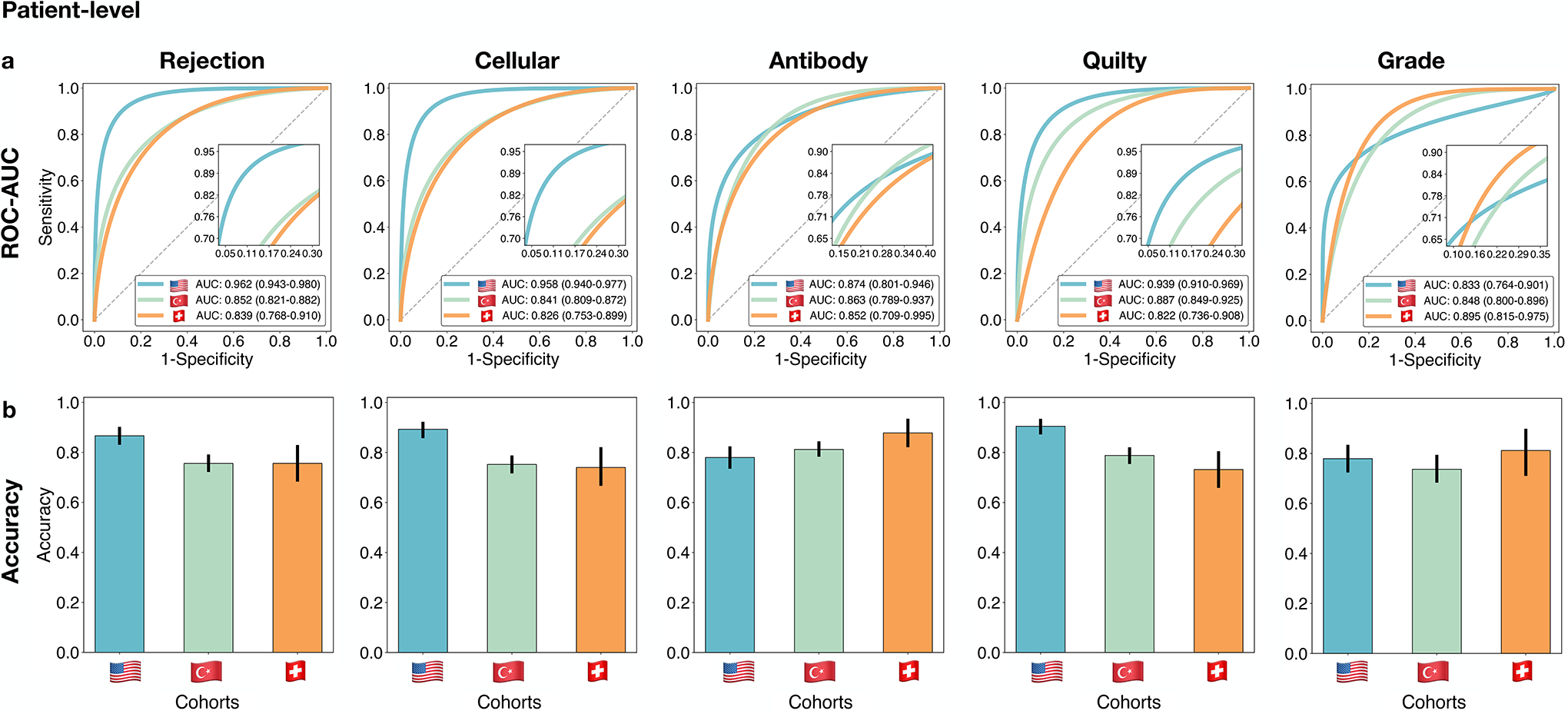
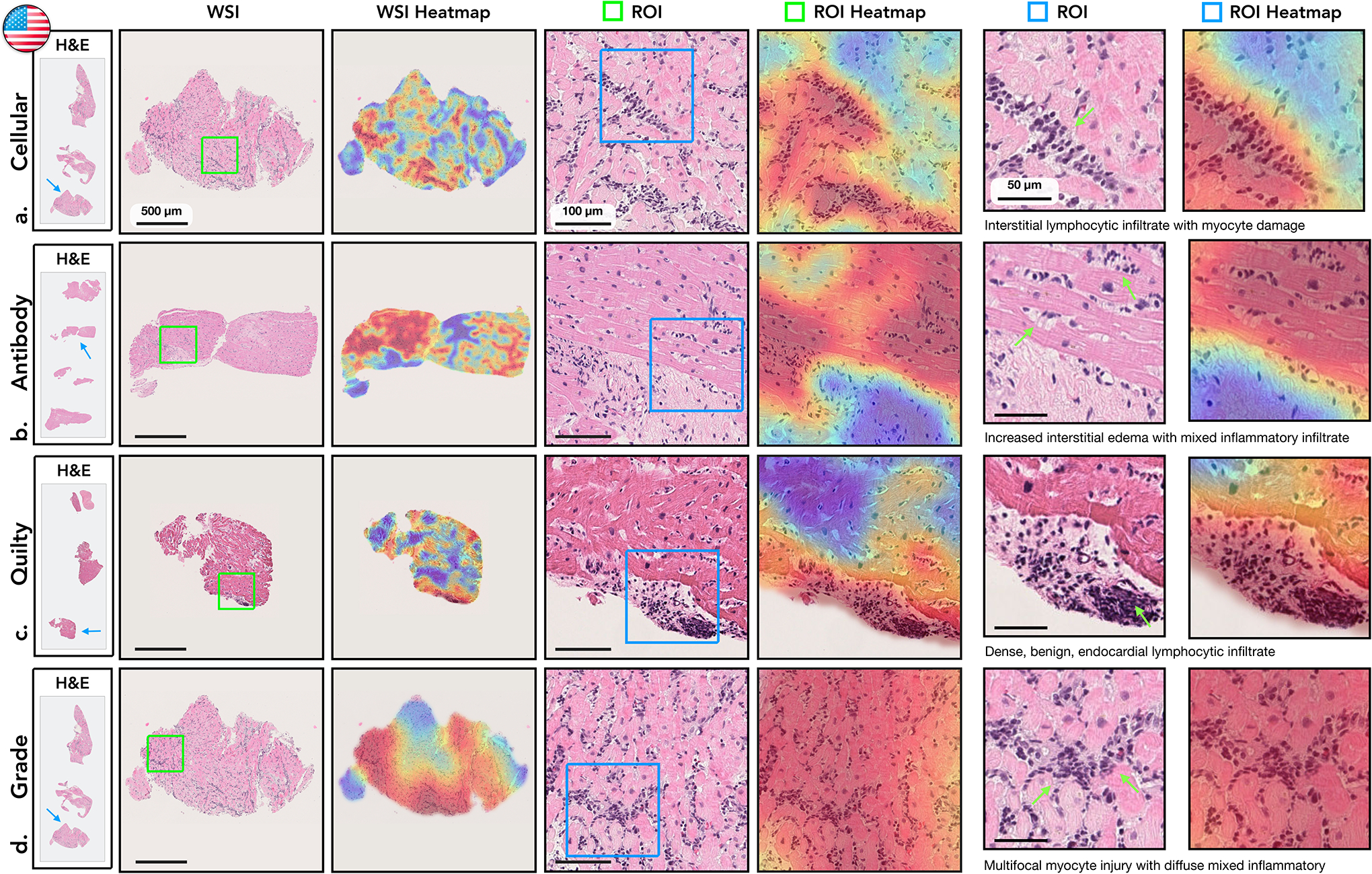
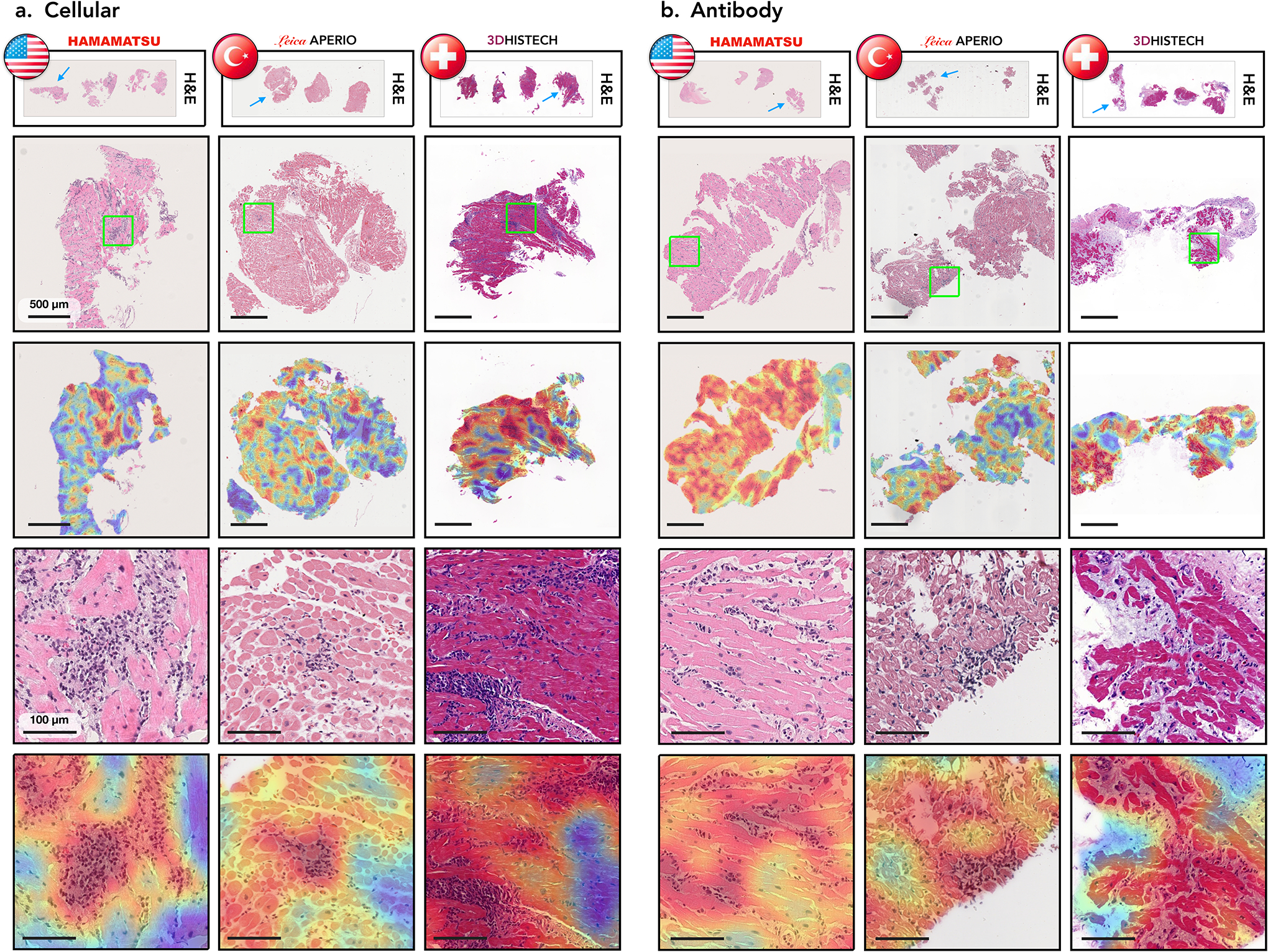
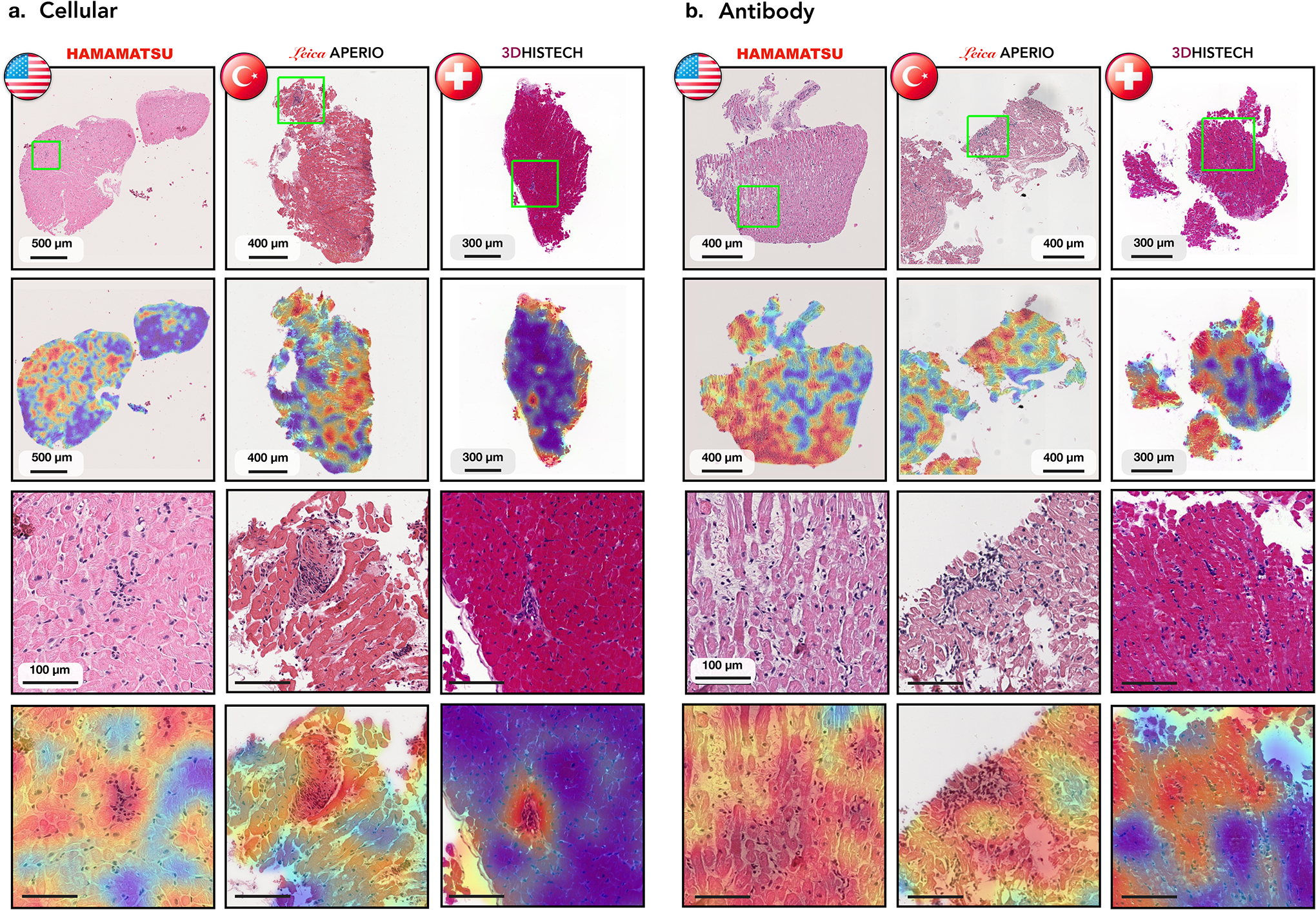
Endomyocardial biopsy (EMB) screening represents the standard of care for detecting allograft rejections after heart transplant. Manual interpretation of EMBs is affected by substantial interobserver and intraobserver variability, which often leads to inappropriate treatment with immunosuppressive drugs, unnecessary follow-up biopsies and poor transplant outcomes. Here we present a deep learning-based artificial intelligence (AI) system for automated assessment of gigapixel whole-slide images obtained from EMBs, which simultaneously addresses detection, subtyping and grading of allograft rejection. To assess model performance, we curated a large dataset from the United States, as well as independent test cohorts from Turkey and Switzerland, which includes large-scale variability across populations, sample preparations and slide scanning instrumentation. The model detects allograft rejection with an area under the receiver operating characteristic curve (AUC) of 0.962; assesses the cellular and antibody-mediated rejection type with AUCs of 0.958 and 0.874, respectively; detects Quilty B lesions, benign mimics of rejection, with an AUC of 0.939; and differentiates between low-grade and high-grade rejections with an AUC of 0.833. In a human reader study, the AI system showed non-inferior performance to conventional assessment and reduced interobserver variability and assessment time. This robust evaluation of cardiac allograft rejection paves the way for clinical trials to establish the efficacy of AI-assisted EMB assessment and its potential for improving heart transplant outcomes.
© 2022. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
Competing Interests
The authors declare no competing financial interests.
Figures
References
-
- Benjamin Emelia J et al. “Forecasting the future of cardiovascular disease in the United States: a policy statement from the American Heart Association.” In: Circulation 137.12 (2018), e67–e492. - PubMed
-
- Badoe Nina and Shah Palak. “History of Heart Transplant”. In: Contemporary Heart Transplantation (2020), pp. 3–12.
-
- Orrego Carlos M et al. “Usefulness of routine surveillance endomyocardial biopsy 6 months after heart transplantation”. In: The Journal of heart and lung transplantation 31.8 (2012), pp. 845–849. - PubMed
-
- Lund Lars H et al. “The Registry of the International Society for Heart and Lung Transplantation: thirtyfourth adult heart transplantation report—2017; focus theme: allograft ischemic time”. In: The Journal of Heart and Lung Transplantation 36.10 (2017), pp. 1037–1046. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
