

A Question-and-Answer System to Extract Data From Free-Text Oncological Pathology Reports (CancerBERT Network): Development Study
- PMID: 35319481
- PMCID: PMC8987958
- DOI: 10.2196/27210
A Question-and-Answer System to Extract Data From Free-Text Oncological Pathology Reports (CancerBERT Network): Development Study
Abstract
Background: Information in pathology reports is critical for cancer care. Natural language processing (NLP) systems used to extract information from pathology reports are often narrow in scope or require extensive tuning. Consequently, there is growing interest in automated deep learning approaches. A powerful new NLP algorithm, bidirectional encoder representations from transformers (BERT), was published in late 2018. BERT set new performance standards on tasks as diverse as question answering, named entity recognition, speech recognition, and more.
Objective: The aim of this study is to develop a BERT-based system to automatically extract detailed tumor site and histology information from free-text oncological pathology reports.
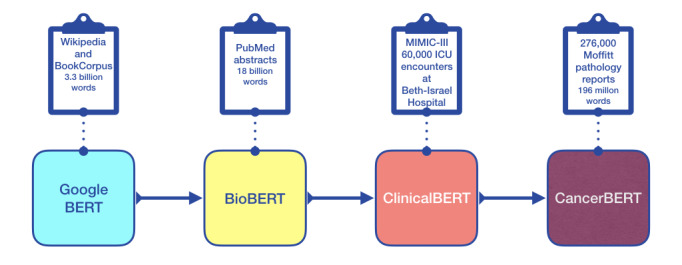
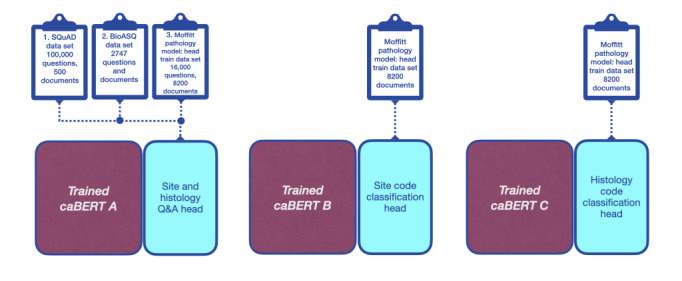
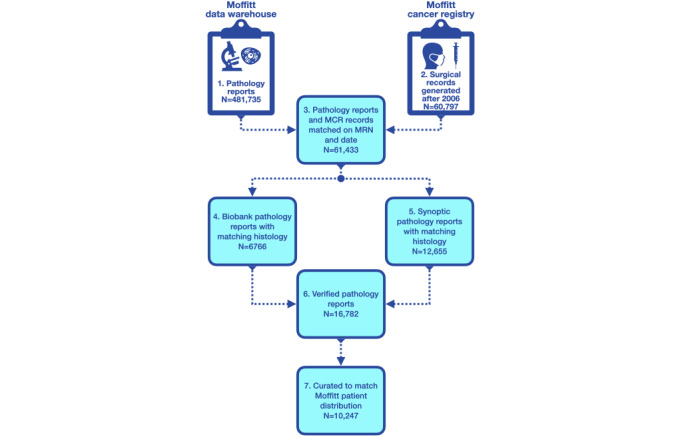
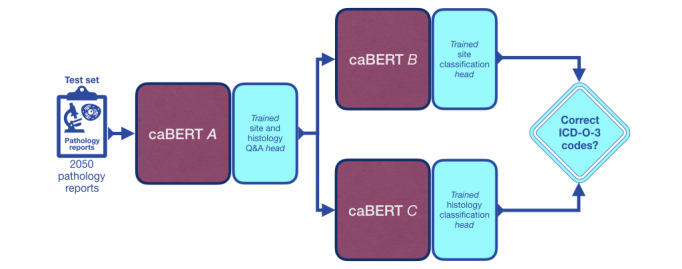
Methods: We pursued three specific aims: extract accurate tumor site and histology descriptions from free-text pathology reports, accommodate the diverse terminology used to indicate the same pathology, and provide accurate standardized tumor site and histology codes for use by downstream applications. We first trained a base language model to comprehend the technical language in pathology reports. This involved unsupervised learning on a training corpus of 275,605 electronic pathology reports from 164,531 unique patients that included 121 million words. Next, we trained a question-and-answer (Q&A) model that connects a Q&A layer to the base pathology language model to answer pathology questions. Our Q&A system was designed to search for the answers to two predefined questions in each pathology report: What organ contains the tumor? and What is the kind of tumor or carcinoma? This involved supervised training on 8197 pathology reports, each with ground truth answers to these 2 questions determined by certified tumor registrars. The data set included 214 tumor sites and 193 histologies. The tumor site and histology phrases extracted by the Q&A model were used to predict International Classification of Diseases for Oncology, Third Edition (ICD-O-3), site and histology codes. This involved fine-tuning two additional BERT models: one to predict site codes and another to predict histology codes. Our final system includes a network of 3 BERT-based models. We call this CancerBERT network (caBERTnet). We evaluated caBERTnet using a sequestered test data set of 2050 pathology reports with ground truth answers determined by certified tumor registrars.
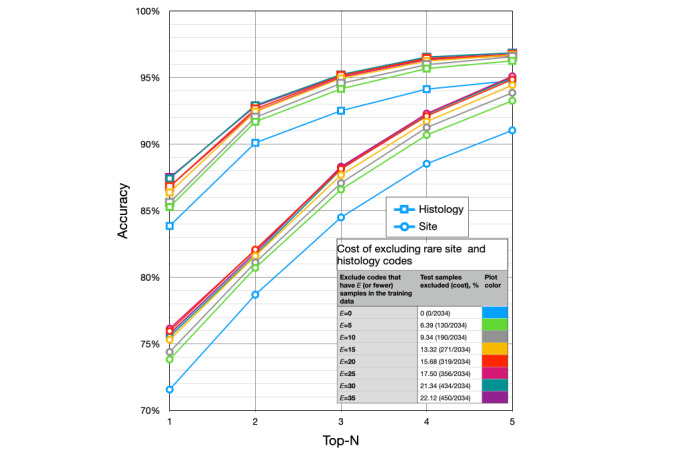
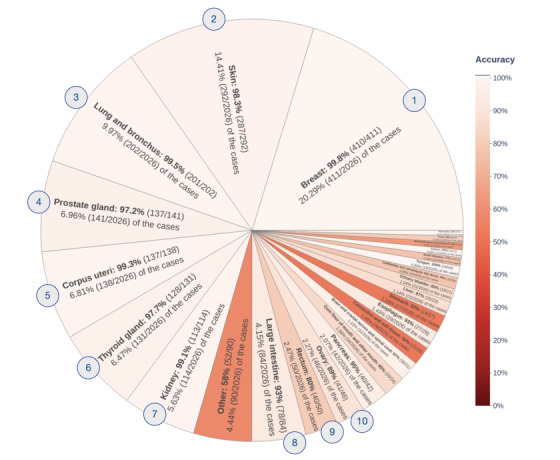
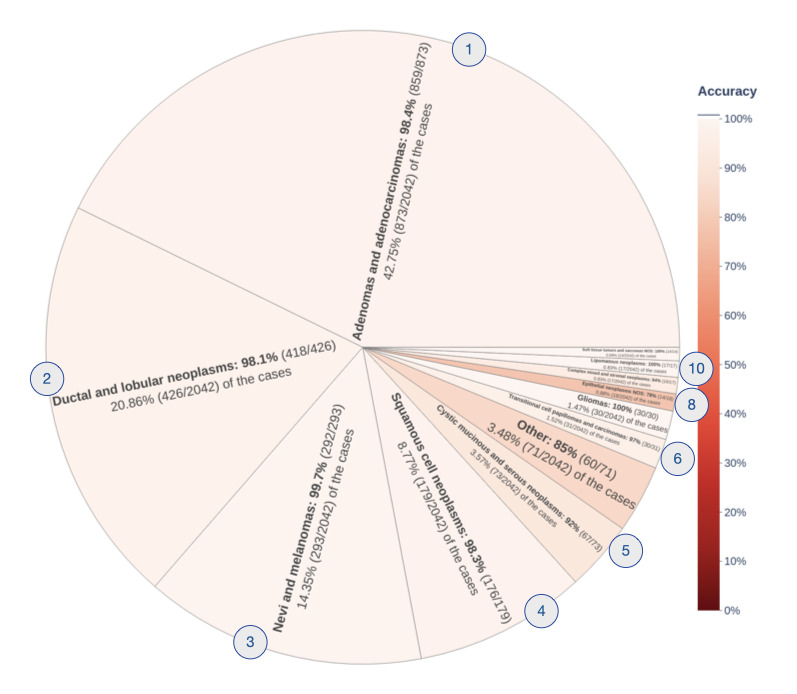
Results: caBERTnet's accuracies for predicting group-level site and histology codes were 93.53% (1895/2026) and 97.6% (1993/2042), respectively. The top 5 accuracies for predicting fine-grained ICD-O-3 site and histology codes with 5 or more samples each in the training data set were 92.95% (1794/1930) and 96.01% (1853/1930), respectively.
Conclusions: We have developed an NLP system that outperforms existing algorithms at predicting ICD-O-3 codes across an extensive range of tumor sites and histologies. Our new system could help reduce treatment delays, increase enrollment in clinical trials of new therapies, and improve patient outcomes.
Keywords: BERT; ICD-O-3; NLP; cancer; deep learning; natural language processing; pathology; transformer.
©Joseph Ross Mitchell, Phillip Szepietowski, Rachel Howard, Phillip Reisman, Jennie D Jones, Patricia Lewis, Brooke L Fridley, Dana E Rollison. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 23.03.2022.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Pratt A, Thomas L. An information processing system for pathology data. Pathol Annul. 1966;1
-
- Meystre S, Haug PJ. Natural language processing to extract medical problems from electronic clinical documents: performance evaluation. J Biomed Inform. 2006 Dec;39(6):589–99. doi: 10.1016/j.jbi.2005.11.004. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(05)00114-0 S1532-0464(05)00114-0 - DOI - PubMed
-
- Murff HJ, FitzHenry F, Matheny ME, Gentry N, Kotter KL, Crimin K, Dittus RS, Rosen AK, Elkin PL, Brown SH, Speroff T. Automated identification of postoperative complications within an electronic medical record using natural language processing. JAMA. 2011 Aug 24;306(8):848–55. doi: 10.1001/jama.2011.1204.306/8/848 - DOI - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
