

Integrating deep learning and unbiased automated high-content screening to identify complex disease signatures in human fibroblasts
- PMID: 35338121
- PMCID: PMC8956598
- DOI: 10.1038/s41467-022-28423-4
Integrating deep learning and unbiased automated high-content screening to identify complex disease signatures in human fibroblasts
Abstract
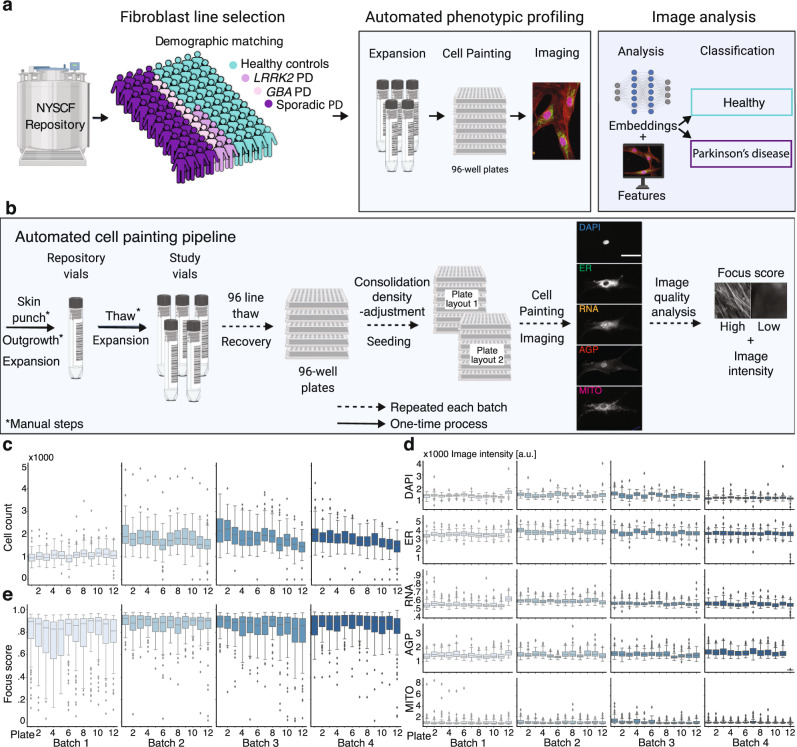
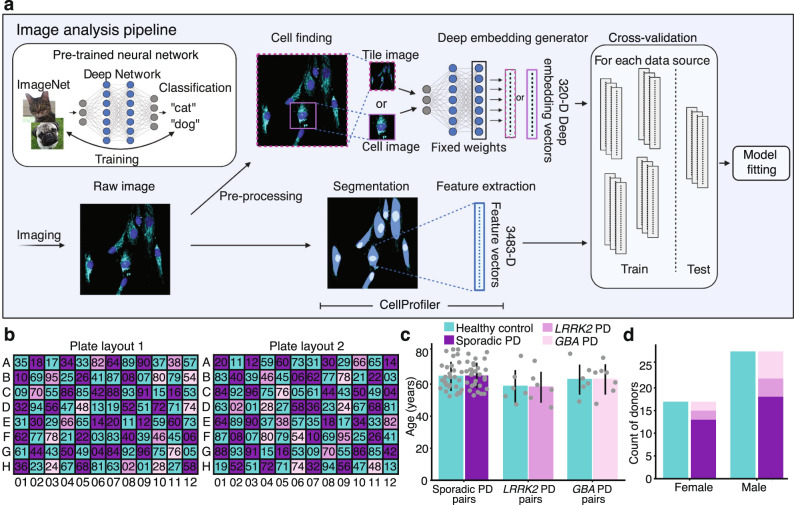
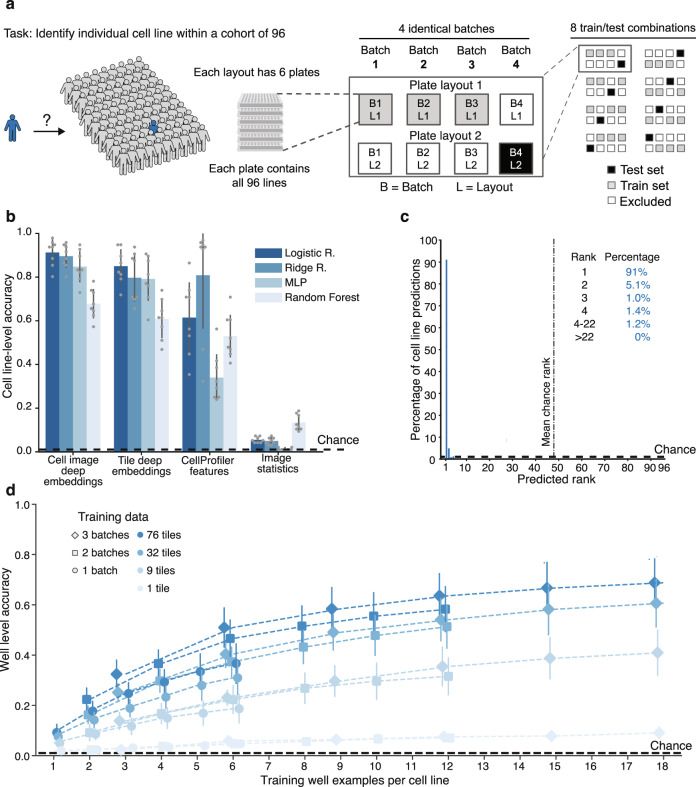
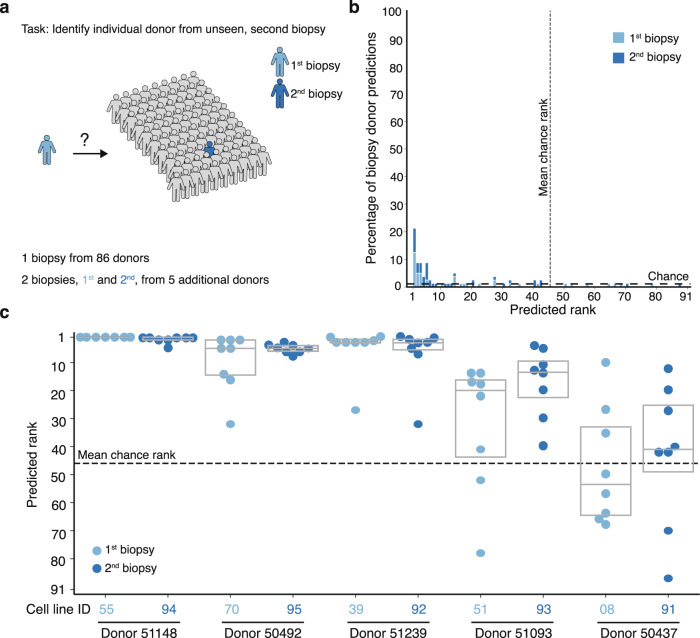
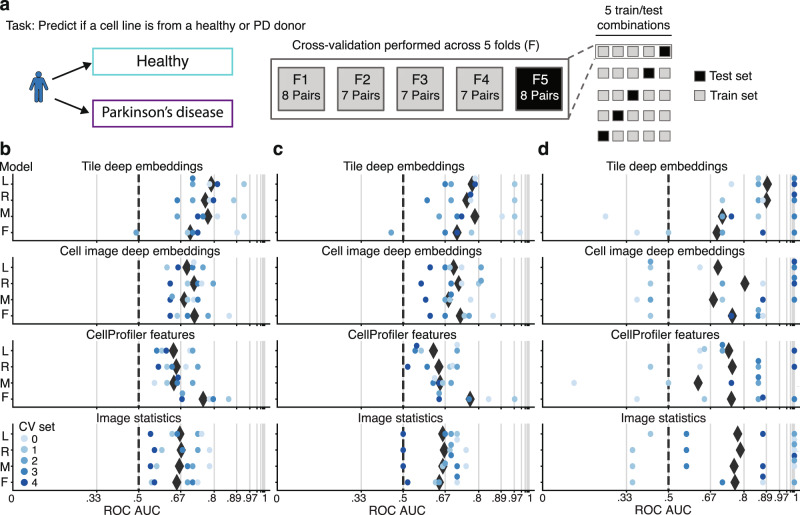
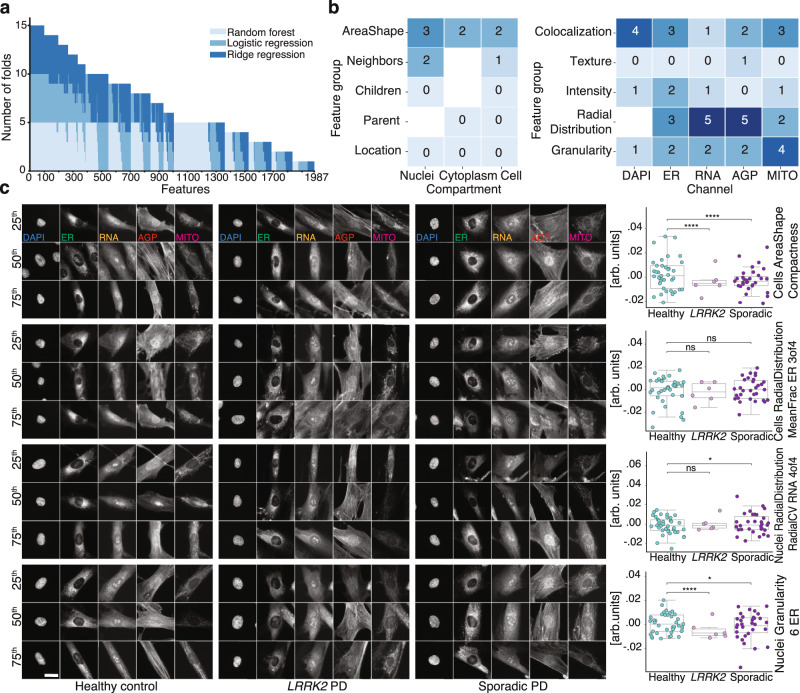
Drug discovery for diseases such as Parkinson's disease are impeded by the lack of screenable cellular phenotypes. We present an unbiased phenotypic profiling platform that combines automated cell culture, high-content imaging, Cell Painting, and deep learning. We applied this platform to primary fibroblasts from 91 Parkinson's disease patients and matched healthy controls, creating the largest publicly available Cell Painting image dataset to date at 48 terabytes. We use fixed weights from a convolutional deep neural network trained on ImageNet to generate deep embeddings from each image and train machine learning models to detect morphological disease phenotypes. Our platform's robustness and sensitivity allow the detection of individual-specific variation with high fidelity across batches and plate layouts. Lastly, our models confidently separate LRRK2 and sporadic Parkinson's disease lines from healthy controls (receiver operating characteristic area under curve 0.79 (0.08 standard deviation)), supporting the capacity of this platform for complex disease modeling and drug screening applications.
© 2022. The Author(s).
Conflict of interest statement
Y.C., M.F., S.A., A.G., S.V., A.N., Z.A., B.W., J.K., M.C., E.A.B., O.P., A.D., P.C.N., M.F., M.B., and S.J.Y. were employed by Google. M.F., A.G., S.V., A.N., Z.A., B.W., J.K., M.C., E.A.B., O.P., P.C.N., M.F., M.B., and S.J.Y. own Alphabet stock. The remaining authors declare no competing interests.
Figures
References
-
- Ando, D. M., McLean, C. & Berndl, M. Improving phenotypic measurements in high-content imaging screens. Preprint (2017).
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
