

A Gibbs sampler for a class of random convex polytopes
- PMID: 35340357
- PMCID: PMC8945543
- DOI: 10.1080/01621459.2021.1945458
A Gibbs sampler for a class of random convex polytopes
Abstract
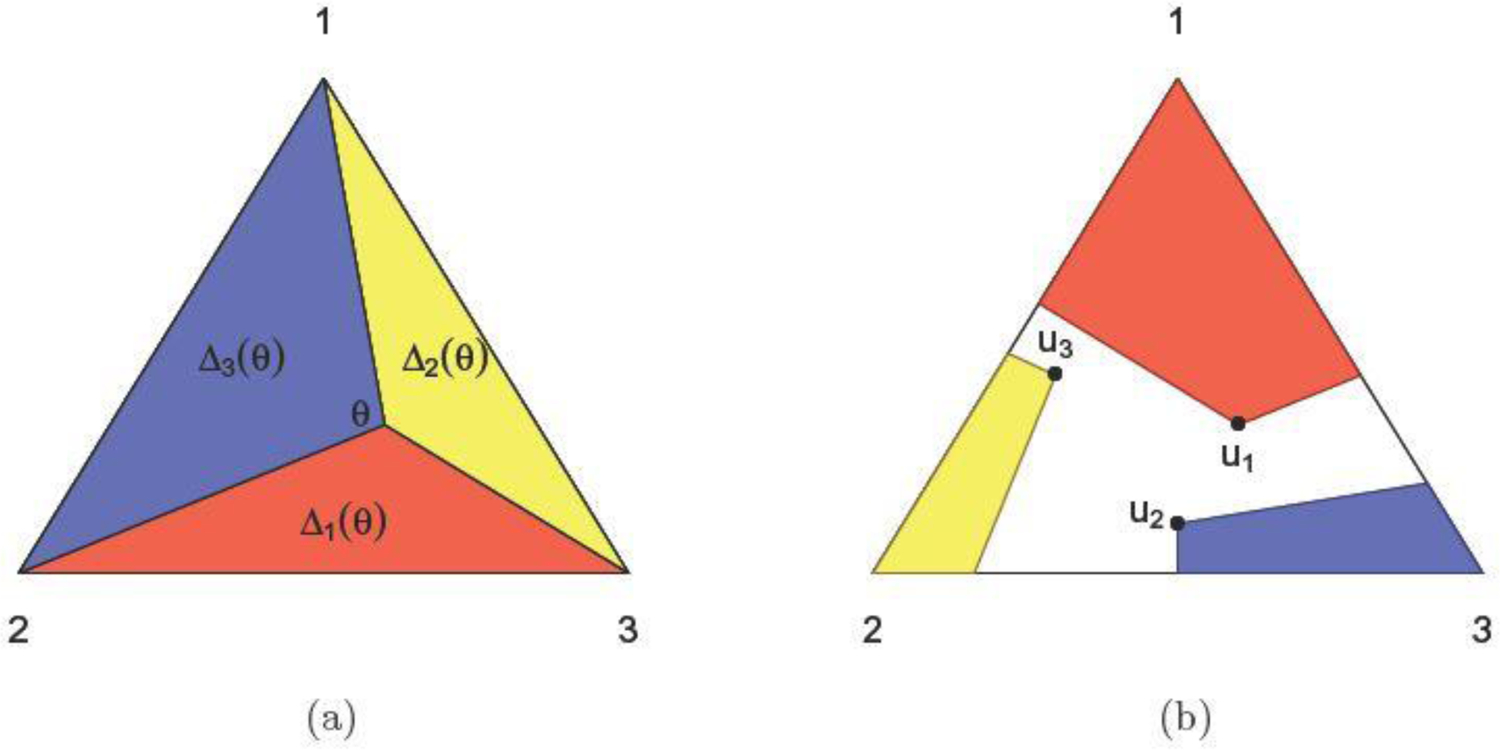
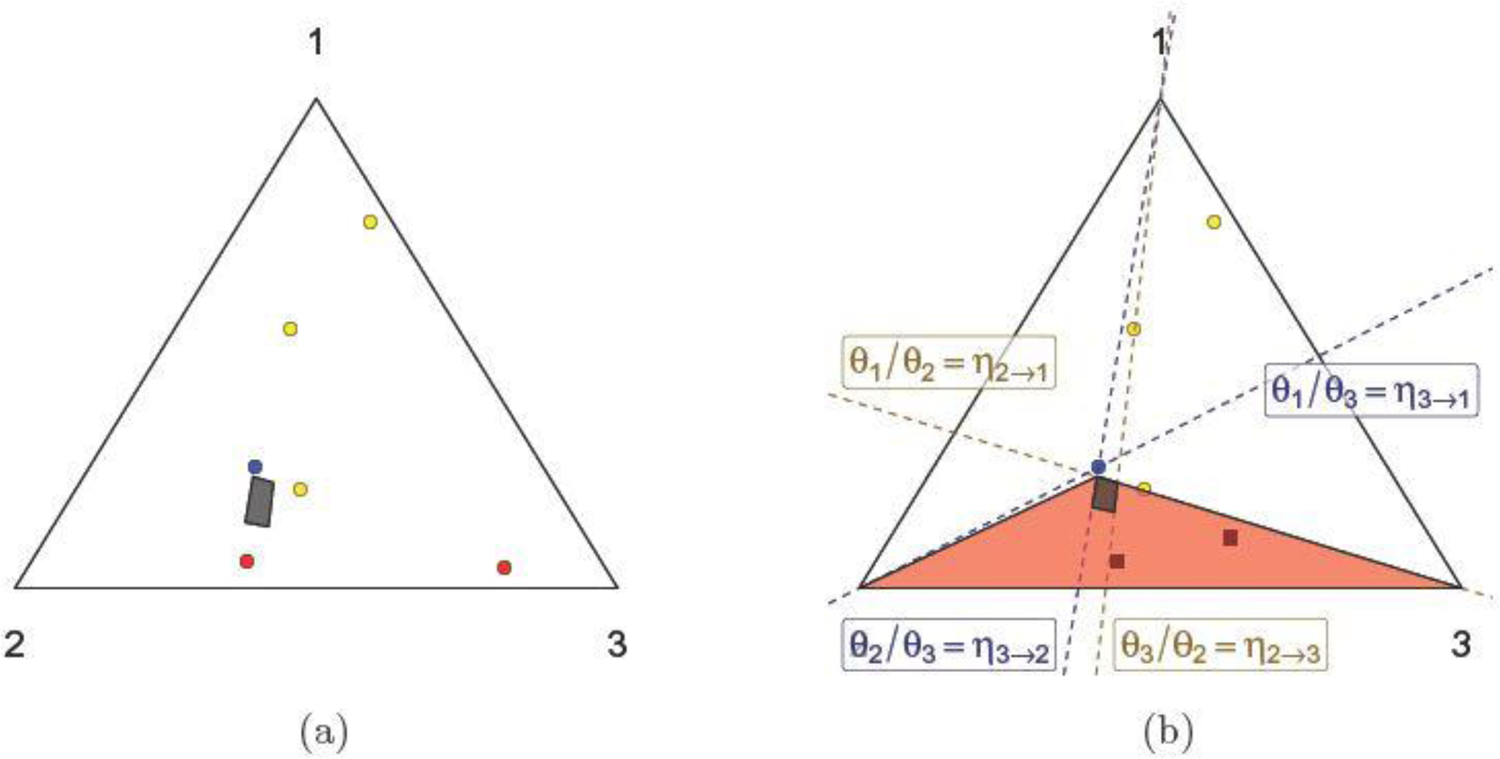
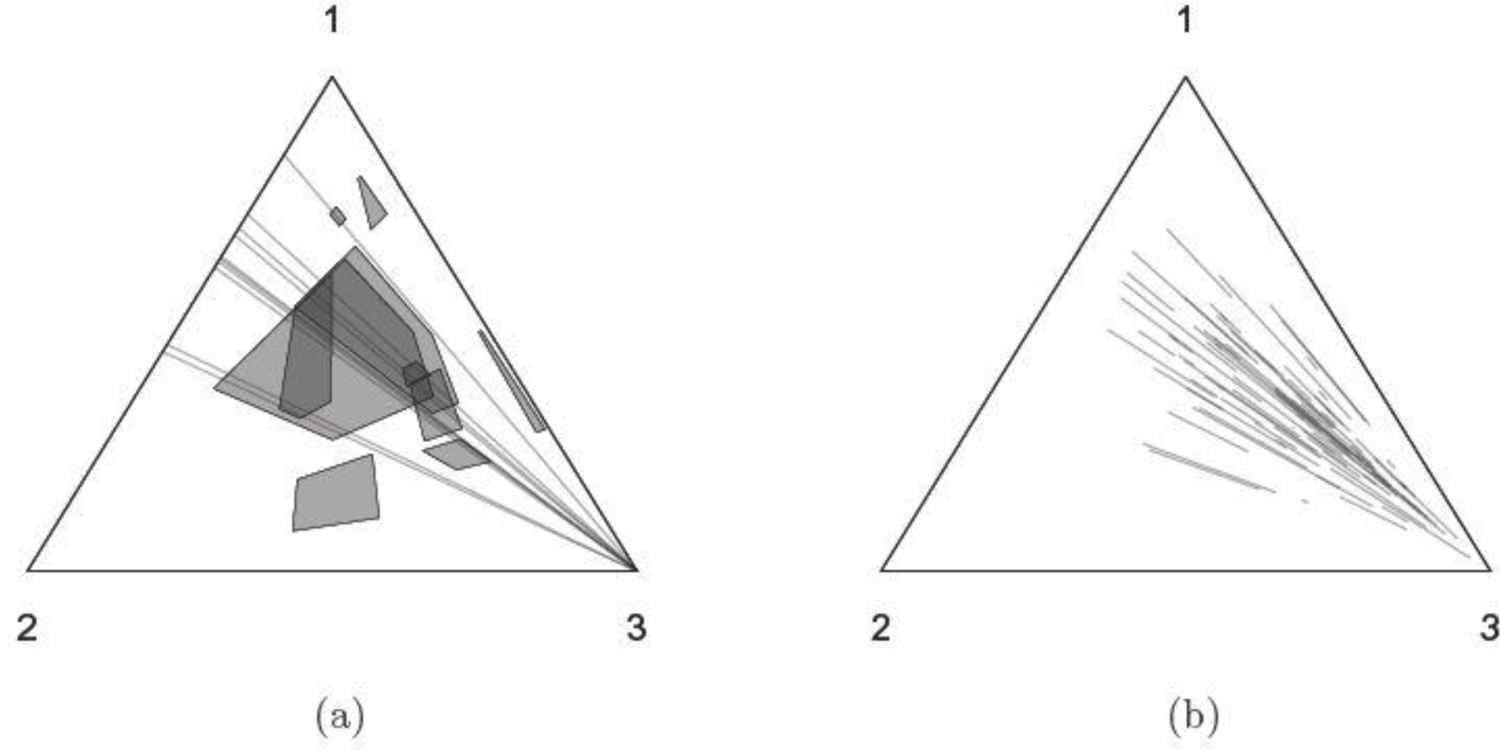
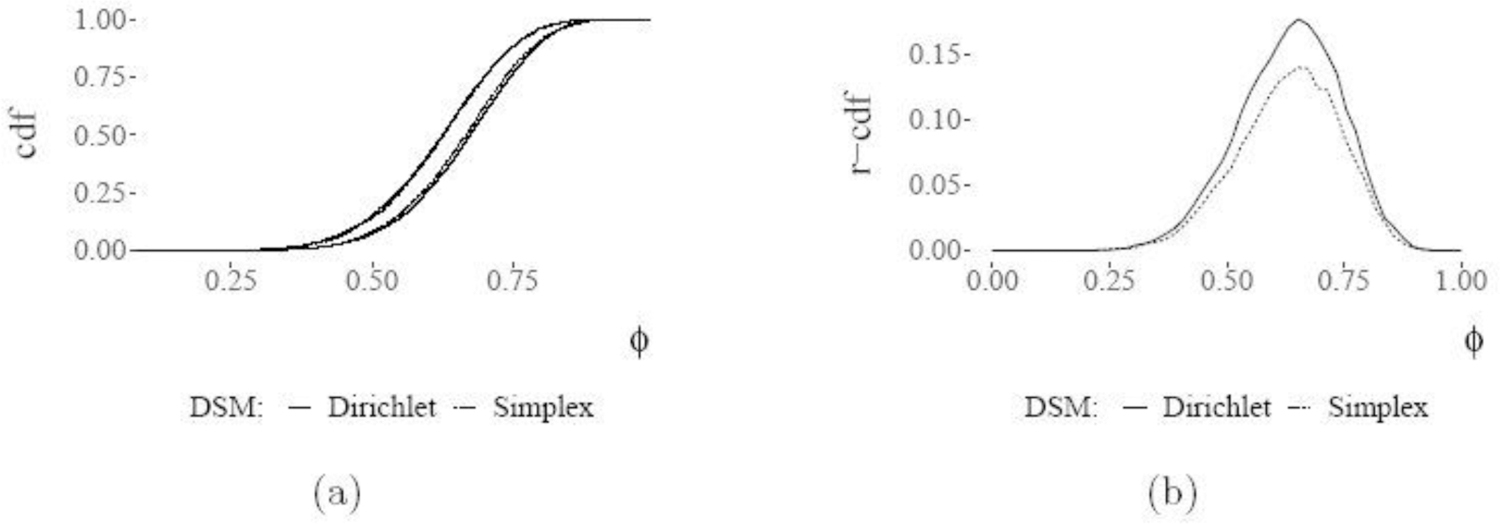
We present a Gibbs sampler for the Dempster-Shafer (DS) approach to statistical inference for Categorical distributions. The DS framework extends the Bayesian approach, allows in particular the use of partial prior information, and yields three-valued uncertainty assessments representing probabilities "for", "against", and "don't know" about formal assertions of interest. The proposed algorithm targets the distribution of a class of random convex polytopes which encapsulate the DS inference. The sampler relies on an equivalence between the iterative constraints of the vertex configuration and the non-negativity of cycles in a fully connected directed graph. Illustrations include the testing of independence in 2 × 2 contingency tables and parameter estimation of the linkage model.
Keywords: Algorithms; Bayesian methods; Categorical data analysis; Simulation.
Figures






References
-
- Albert JH and Gupta AK (1983), ‘Bayesian estimation methods for 2× 2 contingency tables using mixtures of Dirichlet distributions’, Journal of the American Statistical Association 78(383), 708–717.
-
- Avis D and Fukuda K (1992), ‘A pivoting algorithm for convex hulls and vertex enumeration of arrangements and polyhedra’, Discrete & Computational Geometry 8(3), 295–313.
-
- Bang-Jensen J and Gutin GZ (2008), Digraphs: theory, algorithms and applications, Springer Science & Business Media.
-
- Basir O and Yuan X (2007), ‘Engine fault diagnosis based on multi-sensor information fusion using Dempster–Shafer evidence theory’, Information fusion 8(4), 379–386.
-
- Bauer M (1997), ‘Approximation algorithms and decision making in the Dempster–Shafer theory of evidence - an empirical study’, International Journal of Approximate Reasoning 17(2–3), 217–237.
Grants and funding
LinkOut - more resources
Full Text Sources