

Self-supervised Natural Image Reconstruction and Large-scale Semantic Classification from Brain Activity
- PMID: 35342004
- PMCID: PMC9133799
- DOI: 10.1016/j.neuroimage.2022.119121
Self-supervised Natural Image Reconstruction and Large-scale Semantic Classification from Brain Activity
Abstract
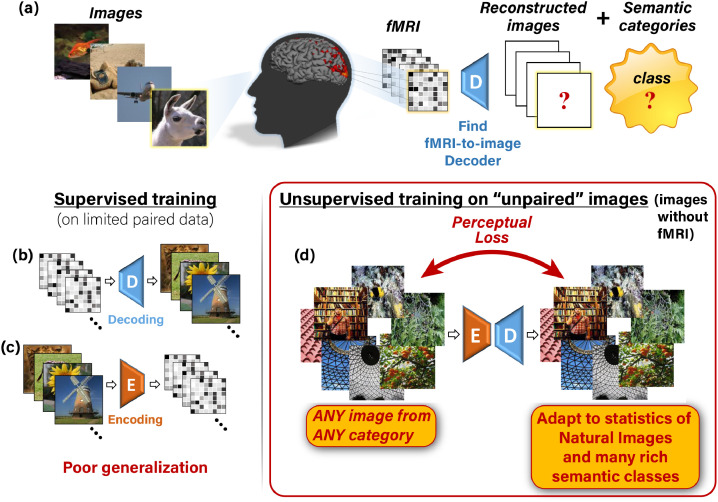
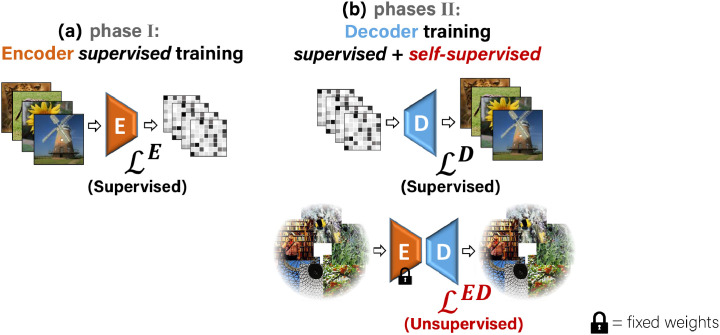
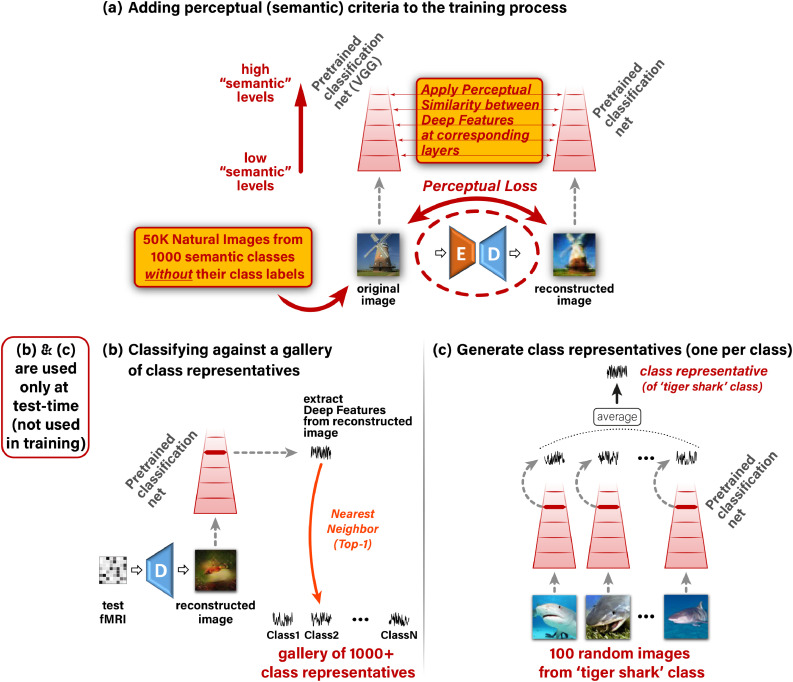
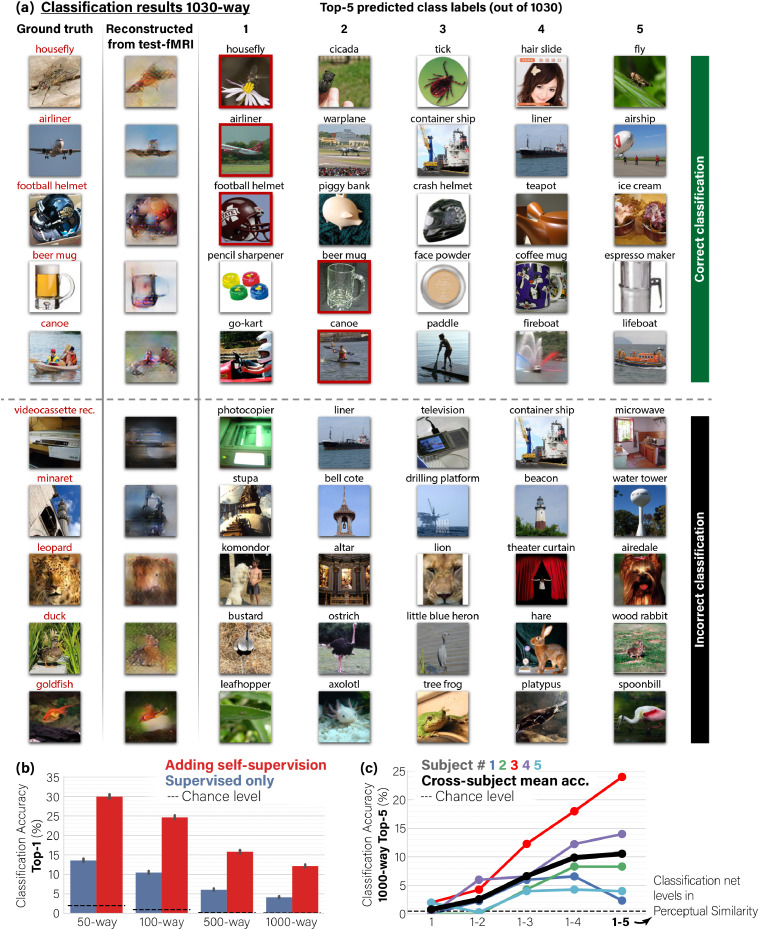
Reconstructing natural images and decoding their semantic category from fMRI brain recordings is challenging. Acquiring sufficient pairs of images and their corresponding fMRI responses, which span the huge space of natural images, is prohibitive. We present a novel self-supervised approach that goes well beyond the scarce paired data, for achieving both: (i) state-of-the art fMRI-to-image reconstruction, and (ii) first-ever large-scale semantic classification from fMRI responses. By imposing cycle consistency between a pair of deep neural networks (from image-to-fMRI & from fMRI-to-image), we train our image reconstruction network on a large number of "unpaired" natural images (images without fMRI recordings) from many novel semantic categories. This enables to adapt our reconstruction network to a very rich semantic coverage without requiring any explicit semantic supervision. Specifically, we find that combining our self-supervised training with high-level perceptual losses, gives rise to new reconstruction & classification capabilities. In particular, this perceptual training enables to classify well fMRIs of never-before-seen semantic classes, without requiring any class labels during training. This gives rise to: (i) Unprecedented image-reconstruction from fMRI of never-before-seen images (evaluated by image metrics and human testing), and (ii) Large-scale semantic classification of categories that were never-before-seen during network training. Such large-scale (1000-way) semantic classification from fMRI recordings has never been demonstrated before. Finally, we provide evidence for the biological consistency of our learned model.
Keywords: Self-Supervised learning, Decoding, Encoding, fMRI, Image reconstruction, Classification; vision.
Copyright © 2022 The Author(s). Published by Elsevier Inc. All rights reserved.
Figures



Similar articles
-
Improved image reconstruction from brain activity through automatic image captioning.Sci Rep. 2025 Feb 10;15(1):4907. doi: 10.1038/s41598-025-89242-3. Sci Rep. 2025. PMID: 39930076 Free PMC article.
-
Semantics-Guided Hierarchical Feature Encoding Generative Adversarial Network for Visual Image Reconstruction From Brain Activity.IEEE Trans Neural Syst Rehabil Eng. 2024;32:1267-1283. doi: 10.1109/TNSRE.2024.3377698. Epub 2024 Mar 22. IEEE Trans Neural Syst Rehabil Eng. 2024. PMID: 38498745
-
Methods for the frugal labeler: Multi-class semantic segmentation on heterogeneous labels.PLoS One. 2022 Feb 8;17(2):e0263656. doi: 10.1371/journal.pone.0263656. eCollection 2022. PLoS One. 2022. PMID: 35134081 Free PMC article.
-
Knowledge-driven deep learning for fast MR imaging: Undersampled MR image reconstruction from supervised to un-supervised learning.Magn Reson Med. 2024 Aug;92(2):496-518. doi: 10.1002/mrm.30105. Epub 2024 Apr 16. Magn Reson Med. 2024. PMID: 38624162 Review.
-
Visual Image Reconstruction from Brain Activity via Latent Representation.Annu Rev Vis Sci. 2025 Jun 16. doi: 10.1146/annurev-vision-110423-023616. Online ahead of print. Annu Rev Vis Sci. 2025. PMID: 40523119 Review.
Cited by
-
Efficient Neural Decoding Based on Multimodal Training.Brain Sci. 2024 Sep 28;14(10):988. doi: 10.3390/brainsci14100988. Brain Sci. 2024. PMID: 39452003 Free PMC article.
-
RECONSTRUCTING RETINAL VISUAL IMAGES FROM 3T FMRI DATA ENHANCED BY UNSUPERVISED LEARNING.Proc IEEE Int Symp Biomed Imaging. 2024 May;2024:10.1109/isbi56570.2024.10635641. doi: 10.1109/isbi56570.2024.10635641. Epub 2024 Aug 22. Proc IEEE Int Symp Biomed Imaging. 2024. PMID: 39421191 Free PMC article.
-
Natural Image Reconstruction From fMRI Using Deep Learning: A Survey.Front Neurosci. 2021 Dec 20;15:795488. doi: 10.3389/fnins.2021.795488. eCollection 2021. Front Neurosci. 2021. PMID: 34987359 Free PMC article.
-
Image Semantic Recognition and Segmentation Algorithm of Colorimetric Sensor Array Based on Deep Convolutional Neural Network.Comput Intell Neurosci. 2022 Sep 30;2022:2439371. doi: 10.1155/2022/2439371. eCollection 2022. Comput Intell Neurosci. 2022. PMID: 36210987 Free PMC article.
-
Brain-optimized inference improves reconstructions of fMRI brain activity.ArXiv [Preprint]. 2023 Dec 12:arXiv:2312.07705v1. ArXiv. 2023. PMID: 38168454 Free PMC article. Preprint.
References
-
- Beliy R., Gaziv G., Hoogi A., Strappini F., Golan T., Irani M. Advances in Neural Information Processing Systems. 2019. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI.
-
https://papers.nips.cc/paper/8879-from-voxels-to-pixels-and-back-self-supervision-in-natural-image-reconstruction-from-fmri http://www.wisdom.weizmann.ac.il/~vision/ssfmri2im/
-
- Cox D.D., Savoy R.L. Functional magnetic resonance imaging (fMRI) ”brain reading”: detecting and classifying distributed patterns of fMRI activity in human visual cortex. Neuroimage. 2003;19(2 Pt 1):261–270. - PubMed
-
http://www.ncbi.nlm.nih.gov/pubmed/12814577 .
-
- Deng J., Dong W., Socher R., Li L.-J., Li K., Fei-Fei L. 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2009. ImageNet: A large-scale hierarchical image database; pp. 248–255. - DOI
-
http://ieeexplore.ieee.org/document/5206848/
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
