

Multi-modality machine learning predicting Parkinson's disease
- PMID: 35365675
- PMCID: PMC8975993
- DOI: 10.1038/s41531-022-00288-w
Multi-modality machine learning predicting Parkinson's disease
Abstract
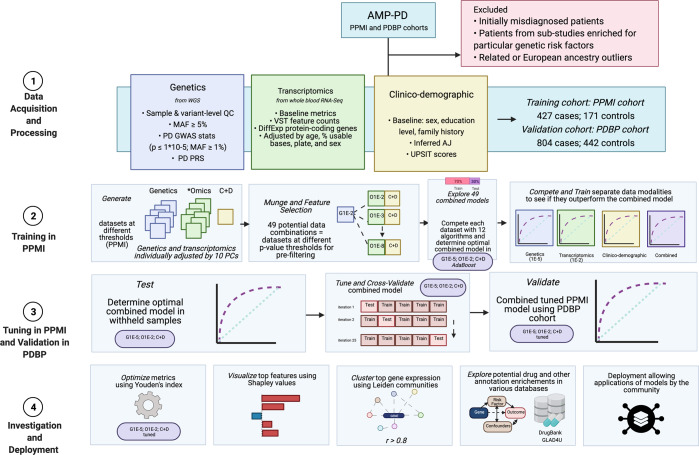
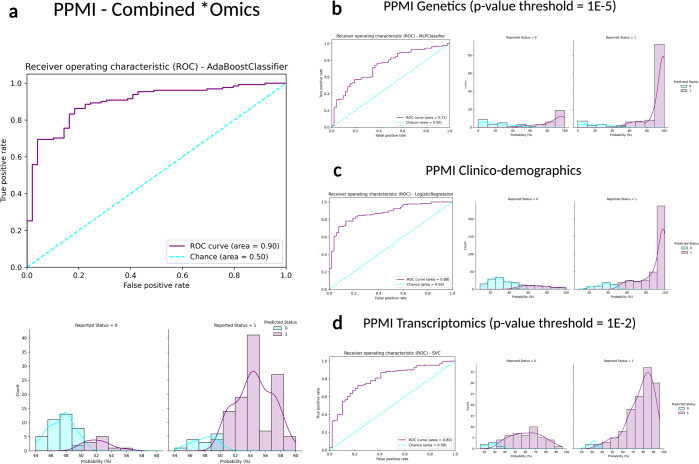
Personalized medicine promises individualized disease prediction and treatment. The convergence of machine learning (ML) and available multimodal data is key moving forward. We build upon previous work to deliver multimodal predictions of Parkinson's disease (PD) risk and systematically develop a model using GenoML, an automated ML package, to make improved multi-omic predictions of PD, validated in an external cohort. We investigated top features, constructed hypothesis-free disease-relevant networks, and investigated drug-gene interactions. We performed automated ML on multimodal data from the Parkinson's progression marker initiative (PPMI). After selecting the best performing algorithm, all PPMI data was used to tune the selected model. The model was validated in the Parkinson's Disease Biomarker Program (PDBP) dataset. Our initial model showed an area under the curve (AUC) of 89.72% for the diagnosis of PD. The tuned model was then tested for validation on external data (PDBP, AUC 85.03%). Optimizing thresholds for classification increased the diagnosis prediction accuracy and other metrics. Finally, networks were built to identify gene communities specific to PD. Combining data modalities outperforms the single biomarker paradigm. UPSIT and PRS contributed most to the predictive power of the model, but the accuracy of these are supplemented by many smaller effect transcripts and risk SNPs. Our model is best suited to identifying large groups of individuals to monitor within a health registry or biobank to prioritize for further testing. This approach allows complex predictive models to be reproducible and accessible to the community, with the package, code, and results publicly available.
© 2022. This is a U.S. government work and not under copyright protection in the U.S.; foreign copyright protection may apply.
Conflict of interest statement
H.L.L., H.I., F.F., D.V., Y.S., and M.A.N. declare that they are consultants employed by Data Tecnica International, whose participation in this is part of a consulting agreement between the US National Institutes of Health and said company. H.R.M. is employed by UCL. In the last 24 months, he reports paid consultancy from Biogen, Biohaven, Lundbeck; lecture fees/honoraria from Wellcome Trust, Movement Disorders Society. Research Grants from Parkinson’s UK, Cure Parkinson’s Trust, PSP Association, CBD Solutions, Drake Foundation, Medical Research Council, Michael J Fox Foundation. H.R.M. is also a co-applicant on a patent application related to C9ORF72—Method for diagnosing a neurodegenerative disease (PCT/GB2012/052140). The study’s funders had no role in the study design, data collection, data analysis, data interpretation, or writing of the report. Authors M.B.M., A.D., I.V., E.H., D.S., S.B.C., J.J.K., M.B., W.N., R.H.C., S.H.H., J.A.B., J.F.C., M.M., D.W.C., K.V.K.-J, J.A.H., C.B., and A.B.S. declare no competing interests. All authors and the public can access all data and statistical programming code used in this project for the analyses and results generation. M.A.N. takes final responsibility for the decision to submit the paper for publication.
Figures


References
-
- Rizzo G, et al. Accuracy of clinical diagnosis of Parkinson disease: a systematic review and meta-analysis. Neurology. 2016;86:566–576. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
