

Expert-augmented automated machine learning optimizes hemodynamic predictors of spinal cord injury outcome
- PMID: 35390006
- PMCID: PMC8989303
- DOI: 10.1371/journal.pone.0265254
Expert-augmented automated machine learning optimizes hemodynamic predictors of spinal cord injury outcome
Erratum in
-
Correction: Expert-augmented automated machine learning optimizes hemodynamic predictors of spinal cord injury outcome.PLoS One. 2023 Nov 2;18(11):e0294081. doi: 10.1371/journal.pone.0294081. eCollection 2023. PLoS One. 2023. PMID: 37917637 Free PMC article.
Abstract
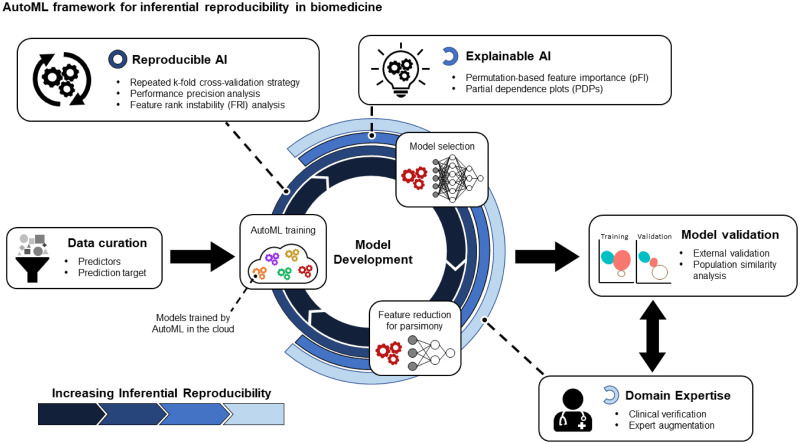
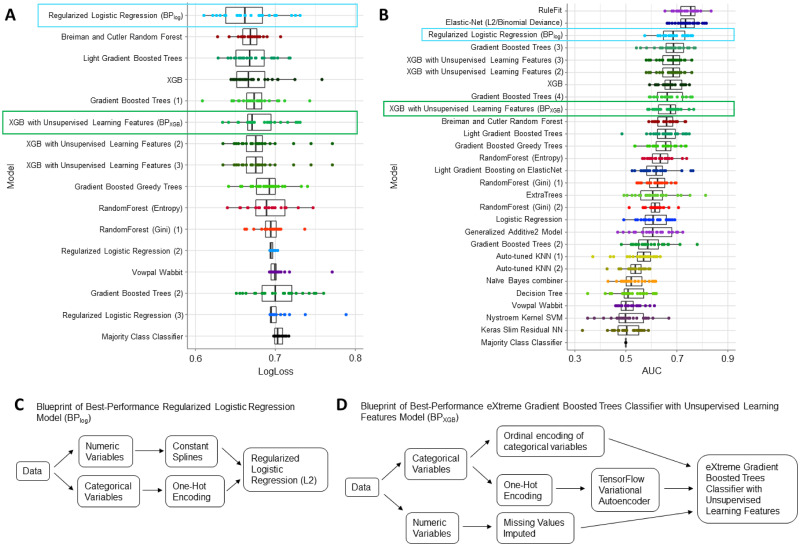
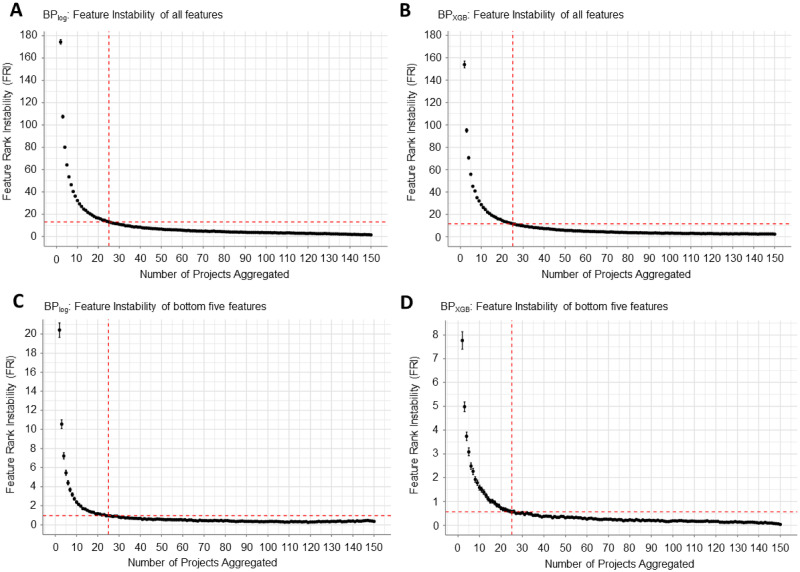
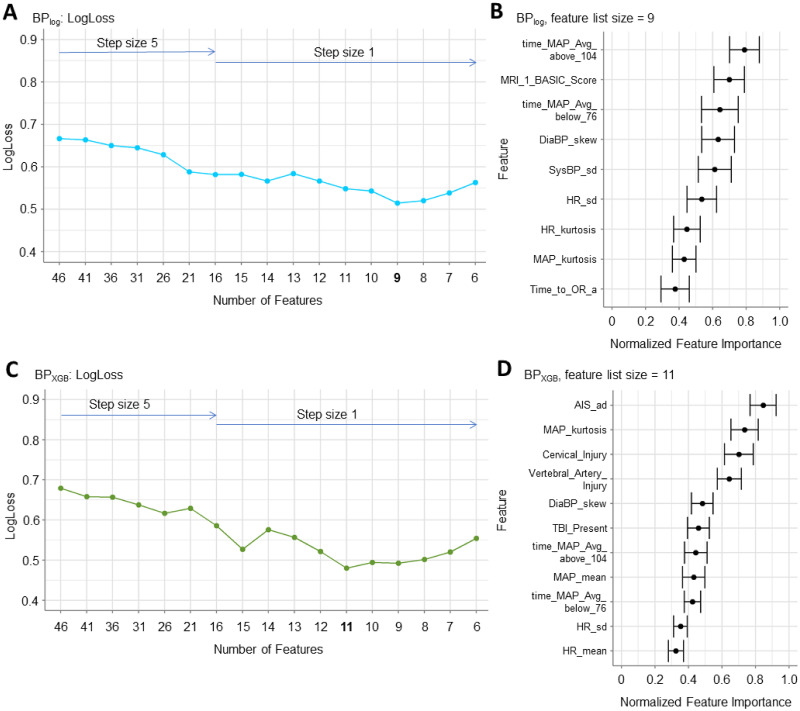
Artificial intelligence and machine learning (AI/ML) is becoming increasingly more accessible to biomedical researchers with significant potential to transform biomedicine through optimization of highly-accurate predictive models and enabling better understanding of disease biology. Automated machine learning (AutoML) in particular is positioned to democratize artificial intelligence (AI) by reducing the amount of human input and ML expertise needed. However, successful translation of AI/ML in biomedicine requires moving beyond optimizing only for prediction accuracy and towards establishing reproducible clinical and biological inferences. This is especially challenging for clinical studies on rare disorders where the smaller patient cohorts and corresponding sample size is an obstacle for reproducible modeling results. Here, we present a model-agnostic framework to reinforce AutoML using strategies and tools of explainable and reproducible AI, including novel metrics to assess model reproducibility. The framework enables clinicians to interpret AutoML-generated models for clinical and biological verifiability and consequently integrate domain expertise during model development. We applied the framework towards spinal cord injury prognostication to optimize the intraoperative hemodynamic range during injury-related surgery and additionally identified a strong detrimental relationship between intraoperative hypertension and patient outcome. Furthermore, our analysis captured how evolving clinical practices such as faster time-to-surgery and blood pressure management affect clinical model development. Altogether, we illustrate how expert-augmented AutoML improves inferential reproducibility for biomedical discovery and can ultimately build trust in AI processes towards effective clinical integration.
Conflict of interest statement
I have read the journal’s policy and the authors of this manuscript have the following competing interests: AC, SK, JF, JH, AL, RS, and CM are current or former employees of DataRobot and own shares of the company. Access to the DataRobot Automated Machine Learning platform was awarded through application and selection by the DataRobot AI for Good program. DataRobot affiliated authors provided editorial contributions during the preparation of the manuscript. All other authors have declared that they have no competing interests.
Figures
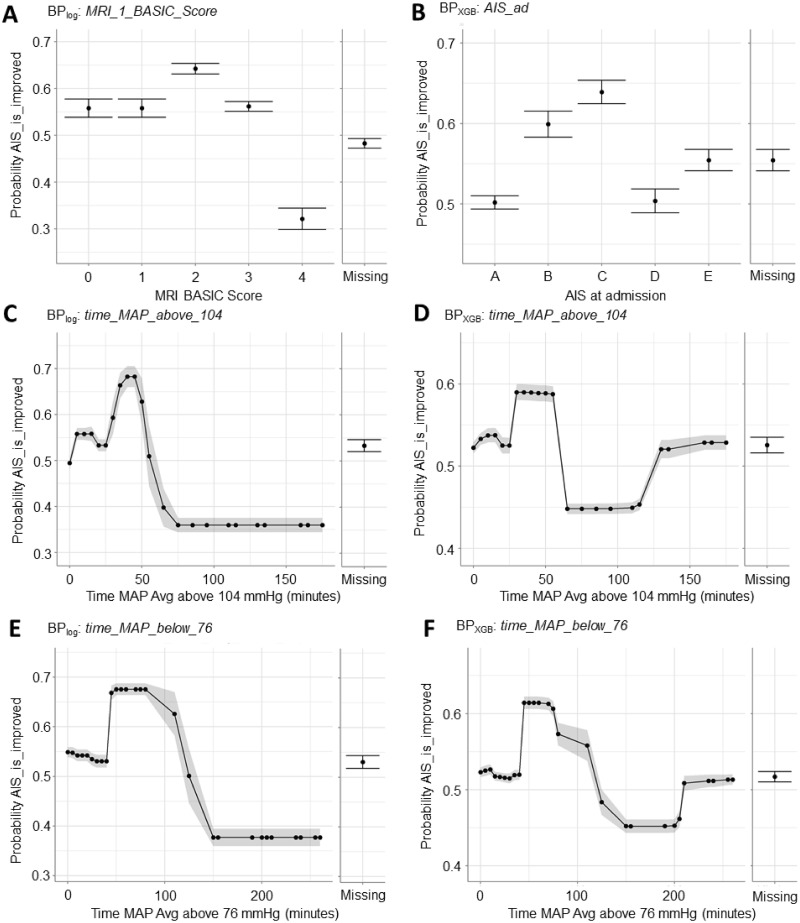
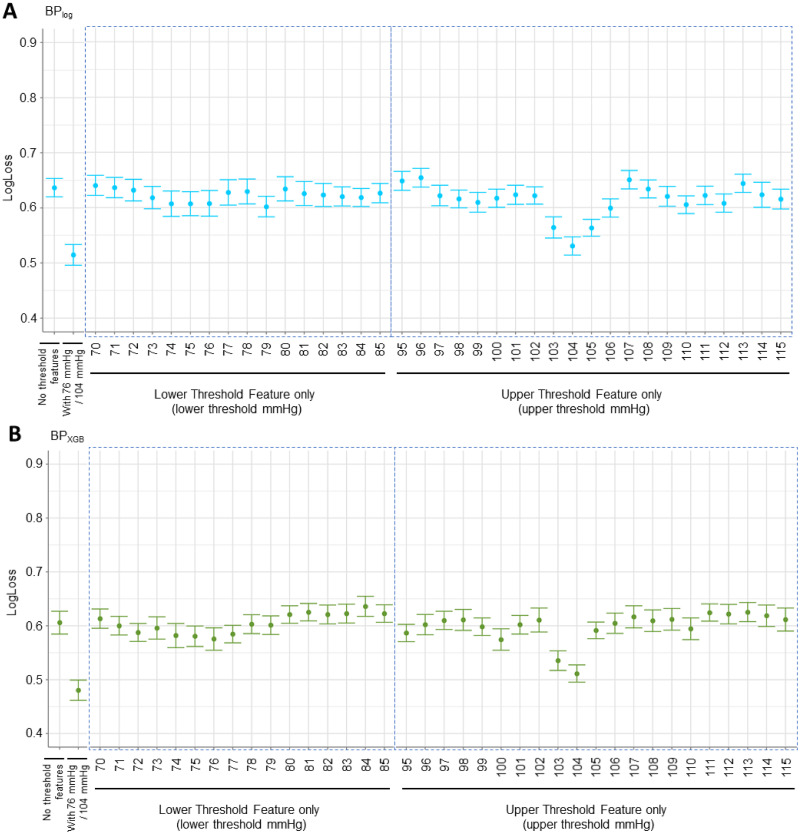
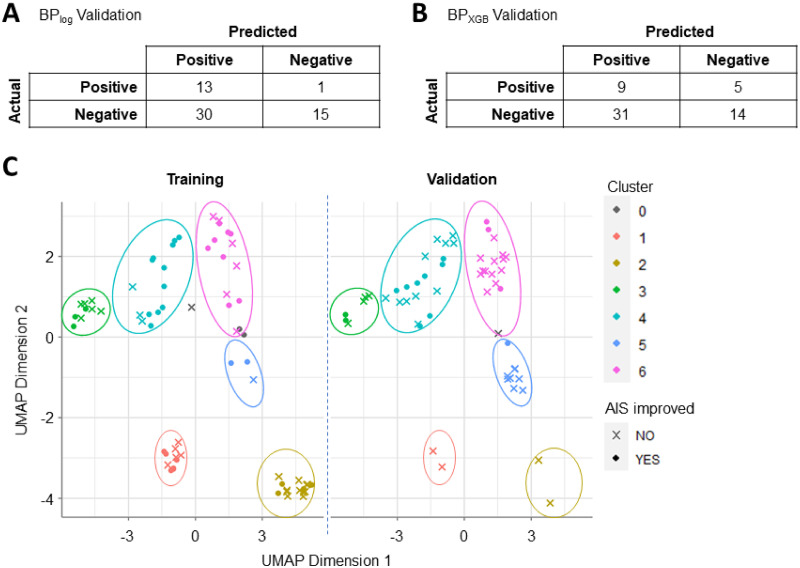
References
-
- Yao Q, Wang M, Chen Y, Dai W, Li Y-F, Tu W-W, et al. Taking Human out of Learning Applications: A Survey on Automated Machine Learning. ArXiv181013306 Cs Stat [Internet]. 2019 Dec 16 [cited 2020 Dec 7]; http://arxiv.org/abs/1810.13306.
-
- Escalante HJ, Montes M, Sucar LE, Mx I, Mx I. Particle Swarm Model Selection.:36.
-
- Feurer M, Klein A, Eggensperger K, Springenberg JT, Blum M, Hutter F. Efficient and Robust Automated Machine Learning.:9.
-
- Balaji A, Allen A. Benchmarking Automatic Machine Learning Frameworks. ArXiv180806492 Cs Stat [Internet]. 2018 Aug 16 [cited 2021 Feb 14]; http://arxiv.org/abs/1808.06492
