

Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data
- PMID: 35408237
- PMCID: PMC9003518
- DOI: 10.3390/s22072623
Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data
Abstract
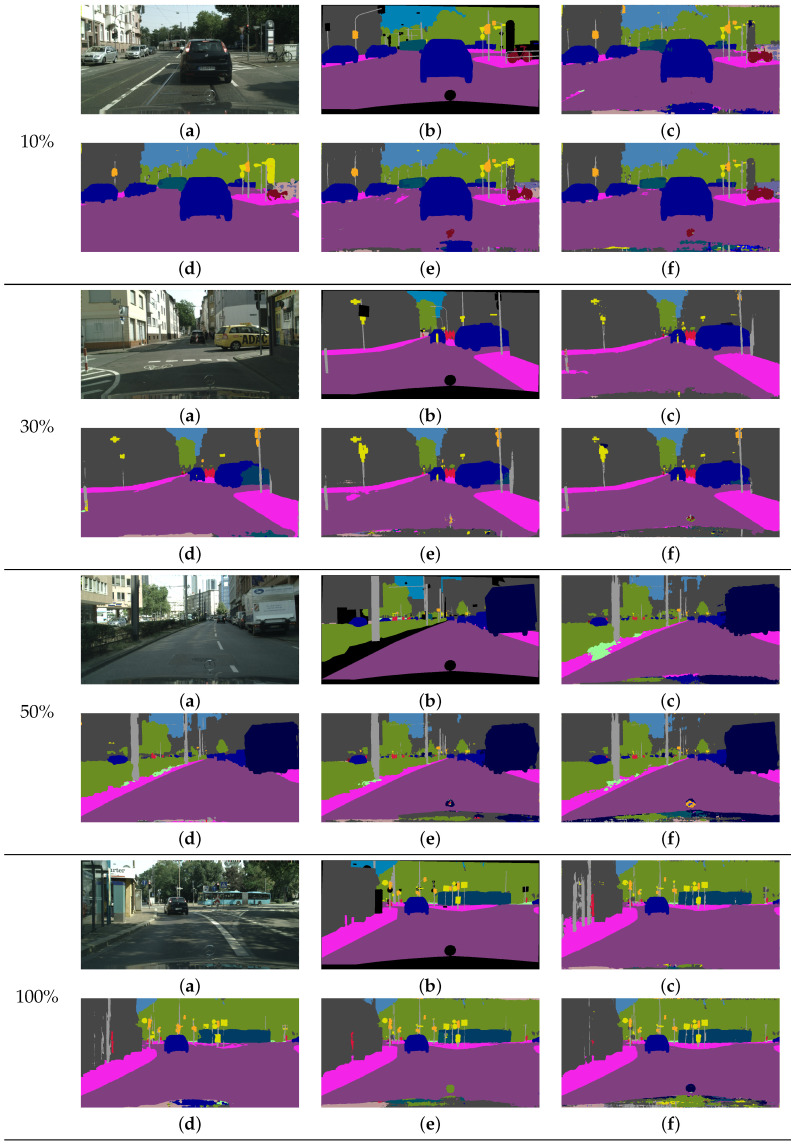
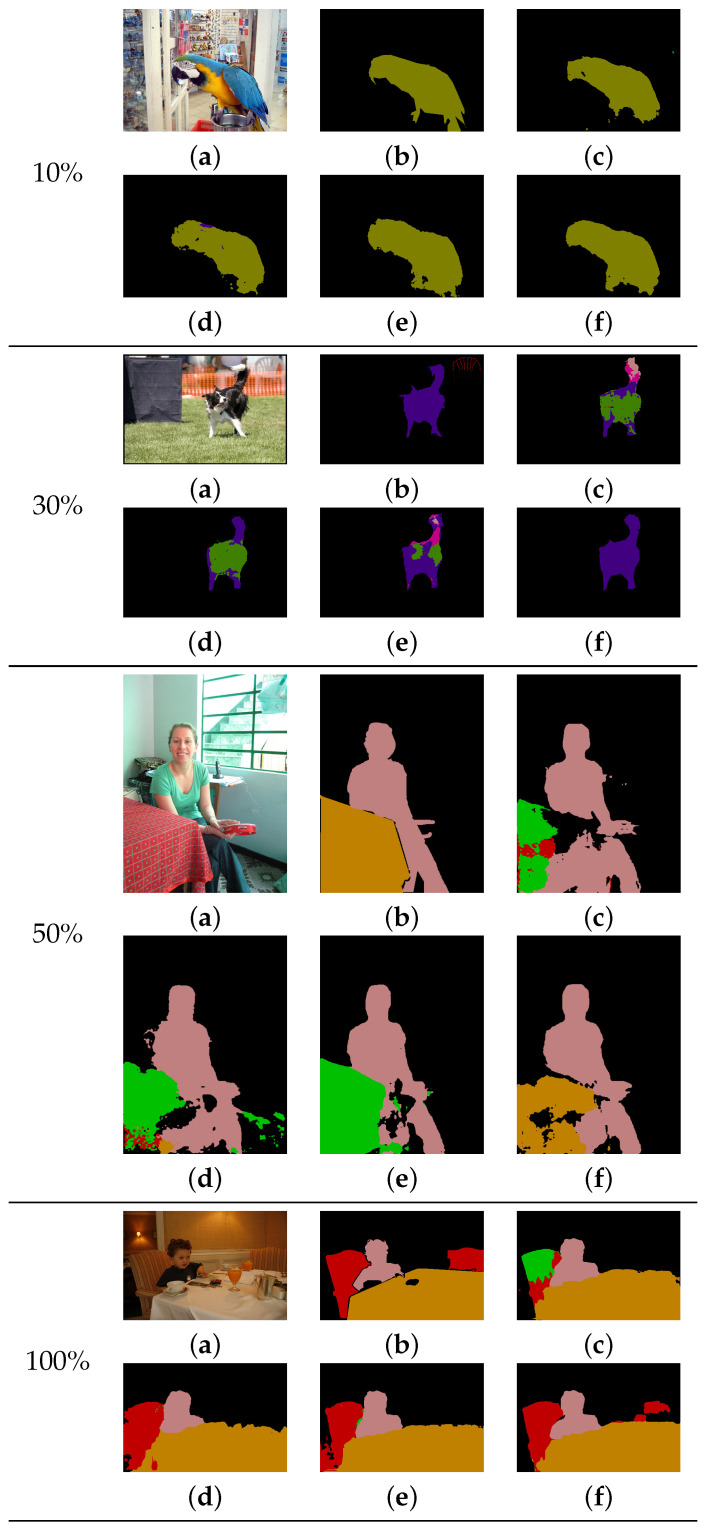
To achieve high performance, most deep convolutional neural networks (DCNNs) require a significant amount of training data with ground truth labels. However, creating ground-truth labels for semantic segmentation requires more time, human effort, and cost compared with other tasks such as classification and object detection, because the ground-truth label of every pixel in an image is required. Hence, it is practically demanding to train DCNNs using a limited amount of training data for semantic segmentation. Generally, training DCNNs using a limited amount of data is problematic as it easily results in a decrease in the accuracy of the networks because of overfitting to the training data. Here, we propose a new regularization method called pixel-wise adaptive label smoothing (PALS) via self-knowledge distillation to stably train semantic segmentation networks in a practical situation, in which only a limited amount of training data is available. To mitigate the problem caused by limited training data, our method fully utilizes the internal statistics of pixels within an input image. Consequently, the proposed method generates a pixel-wise aggregated probability distribution using a similarity matrix that encodes the affinities between all pairs of pixels. To further increase the accuracy, we add one-hot encoded distributions with ground-truth labels to these aggregated distributions, and obtain our final soft labels. We demonstrate the effectiveness of our method for the Cityscapes dataset and the Pascal VOC2012 dataset using limited amounts of training data, such as 10%, 30%, 50%, and 100%. Based on various quantitative and qualitative comparisons, our method demonstrates more accurate results compared with previous methods. Specifically, for the Cityscapes test set, our method achieved mIoU improvements of 0.076%, 1.848%, 1.137%, and 1.063% for 10%, 30%, 50%, and 100% training data, respectively, compared with the method of the cross-entropy loss using one-hot encoding with ground truth labels.
Keywords: limited training data; regularization; self-knowledge distillation; semantic segmentation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures






Similar articles
-
Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation.Med Image Anal. 2023 Jul;87:102792. doi: 10.1016/j.media.2023.102792. Epub 2023 Mar 11. Med Image Anal. 2023. PMID: 37054649
-
Methods for the frugal labeler: Multi-class semantic segmentation on heterogeneous labels.PLoS One. 2022 Feb 8;17(2):e0263656. doi: 10.1371/journal.pone.0263656. eCollection 2022. PLoS One. 2022. PMID: 35134081 Free PMC article.
-
Group-Wise Learning for Weakly Supervised Semantic Segmentation.IEEE Trans Image Process. 2022;31:799-811. doi: 10.1109/TIP.2021.3132834. Epub 2022 Jan 4. IEEE Trans Image Process. 2022. PMID: 34910633
-
Sample self-selection using dual teacher networks for pathological image classification with noisy labels.Comput Biol Med. 2024 May;174:108489. doi: 10.1016/j.compbiomed.2024.108489. Epub 2024 Apr 16. Comput Biol Med. 2024. PMID: 38640633 Review.
-
A Survey on Label-Efficient Deep Image Segmentation: Bridging the Gap Between Weak Supervision and Dense Prediction.IEEE Trans Pattern Anal Mach Intell. 2023 Aug;45(8):9284-9305. doi: 10.1109/TPAMI.2023.3246102. Epub 2023 Jun 30. IEEE Trans Pattern Anal Mach Intell. 2023. PMID: 37027561 Review.
Cited by
-
FIAEPI-KD: A novel knowledge distillation approach for precise detection of missing insulators in transmission lines.PLoS One. 2025 May 30;20(5):e0324524. doi: 10.1371/journal.pone.0324524. eCollection 2025. PLoS One. 2025. PMID: 40445919 Free PMC article.
References
-
- Zeng W., Luo W., Suo S., Sadat A., Yang B., Casas S., Urtasun R. End-To-End Interpretable Neural Motion Planner; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Long Beach, CA, USA. 15–20 June 2019; pp. 8652–8661.
-
- Philion J., Fidler S. Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D; Proceedings of the European Conference on Computer Vision (ECCV); Glasgow, UK. 23–28 August 2020.
-
- Cherabier I.F., Schönberger J.L., Oswald M.R., Pollefeys M., Geiger A. Learning Priors for Semantic 3D Reconstruction; Proceedings of the European Conference on Computer Vision (ECCV); Munich, Germany. 8–14 September 2018; pp. 314–330.
-
- Ronneberger O., Fischer P., Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI); Munich, Germany. 5–9 October 2015; pp. 234–241.
MeSH terms
LinkOut - more resources
Full Text Sources
