

Pangenome-based genome inference allows efficient and accurate genotyping across a wide spectrum of variant classes
- PMID: 35410384
- PMCID: PMC9005351
- DOI: 10.1038/s41588-022-01043-w
Pangenome-based genome inference allows efficient and accurate genotyping across a wide spectrum of variant classes
Abstract
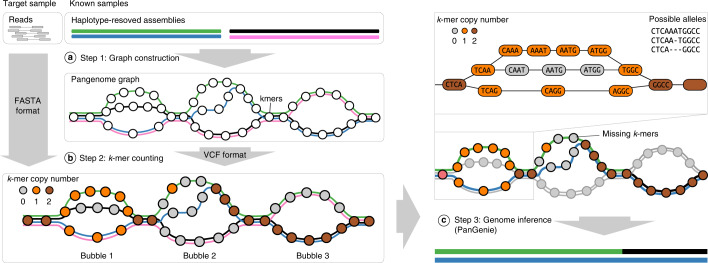
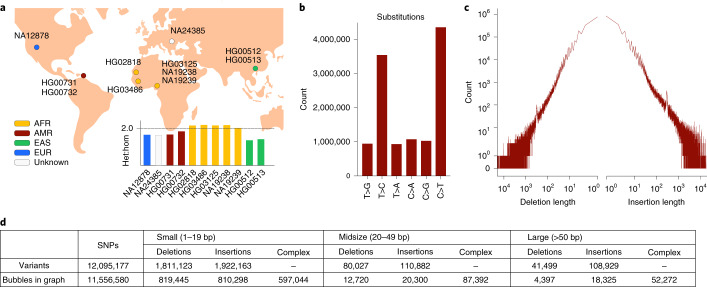
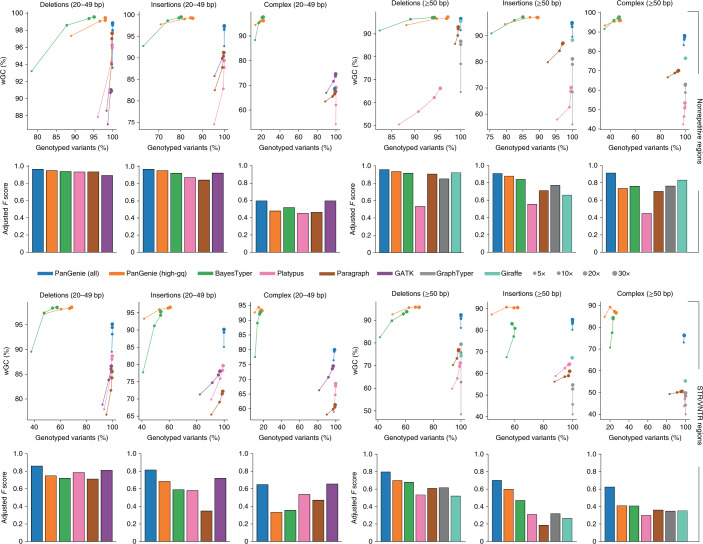
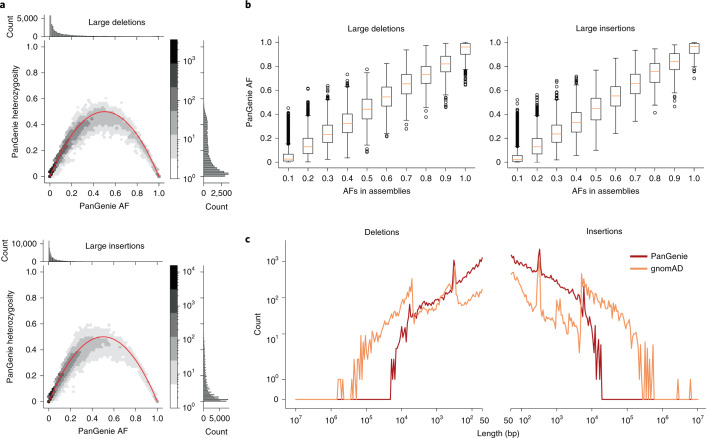
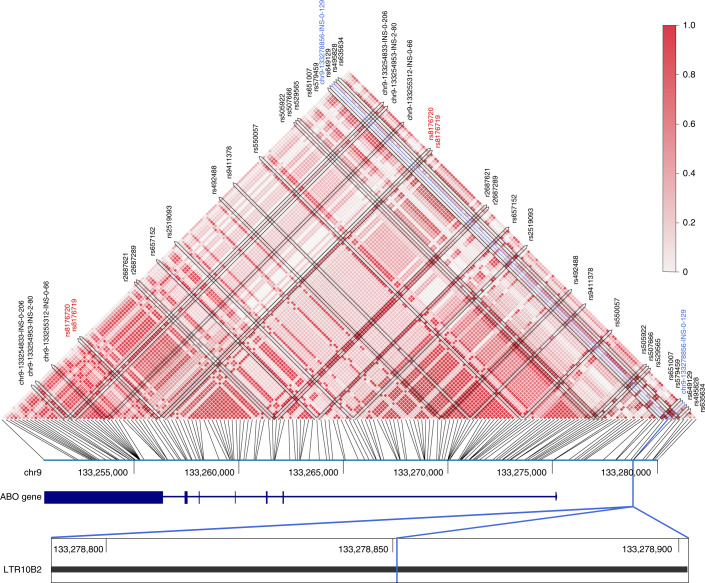
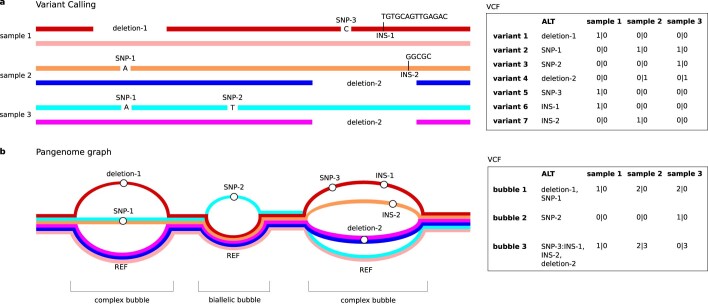
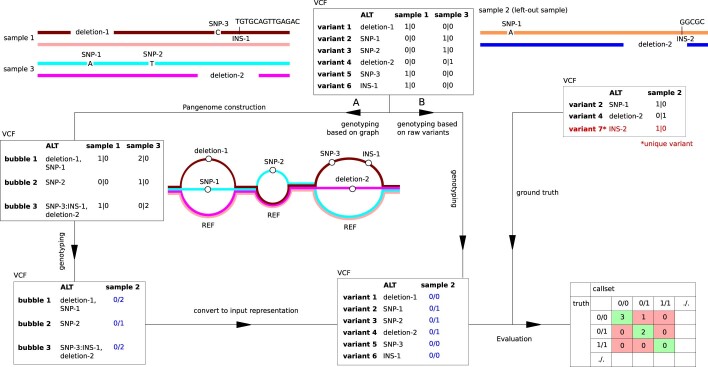
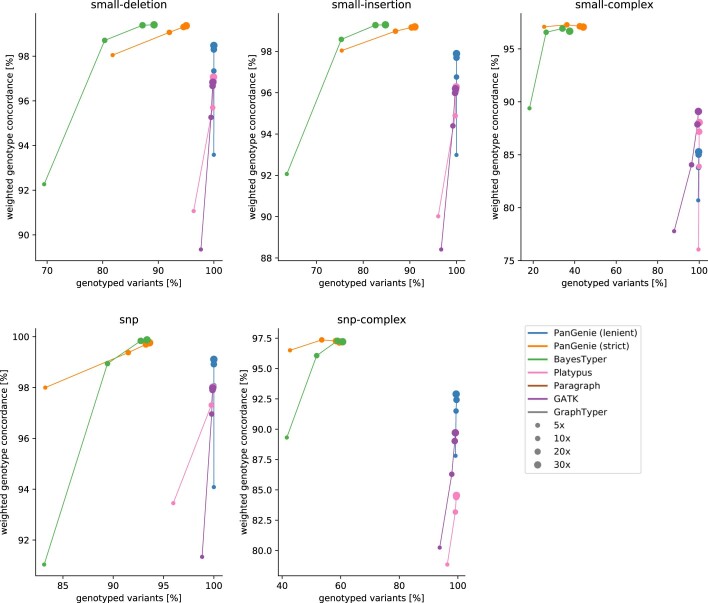
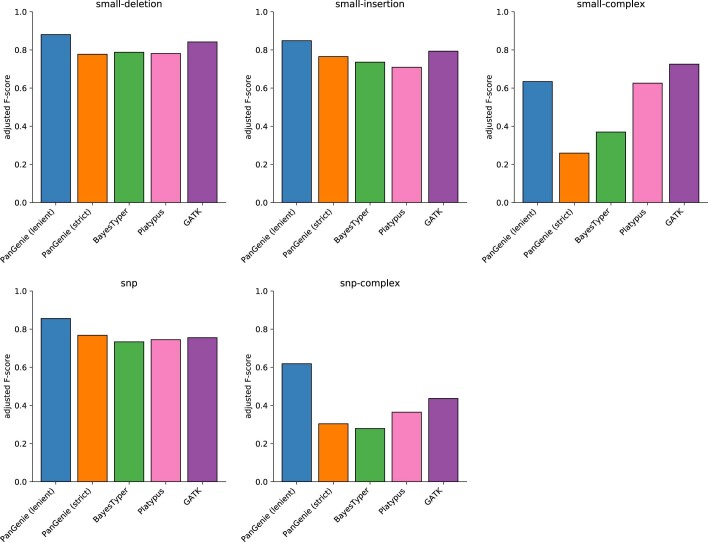
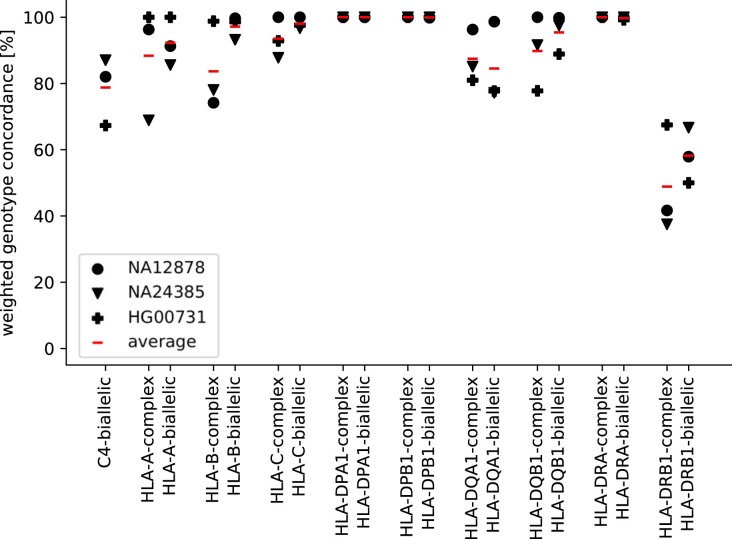
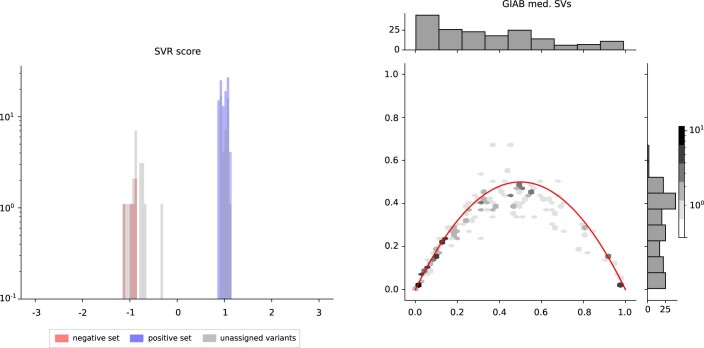
Typical genotyping workflows map reads to a reference genome before identifying genetic variants. Generating such alignments introduces reference biases and comes with substantial computational burden. Furthermore, short-read lengths limit the ability to characterize repetitive genomic regions, which are particularly challenging for fast k-mer-based genotypers. In the present study, we propose a new algorithm, PanGenie, that leverages a haplotype-resolved pangenome reference together with k-mer counts from short-read sequencing data to genotype a wide spectrum of genetic variation-a process we refer to as genome inference. Compared with mapping-based approaches, PanGenie is more than 4 times faster at 30-fold coverage and achieves better genotype concordances for almost all variant types and coverages tested. Improvements are especially pronounced for large insertions (≥50 bp) and variants in repetitive regions, enabling the inclusion of these classes of variants in genome-wide association studies. PanGenie efficiently leverages the increasing amount of haplotype-resolved assemblies to unravel the functional impact of previously inaccessible variants while being faster compared with alignment-based workflows.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
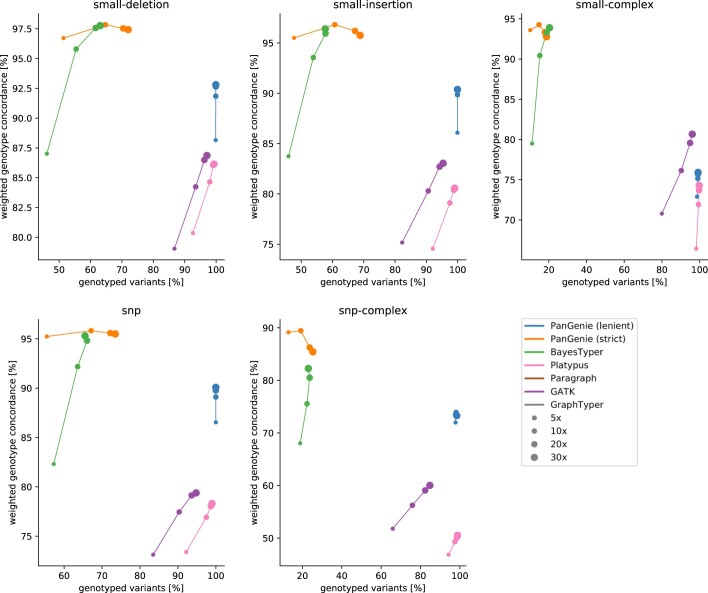
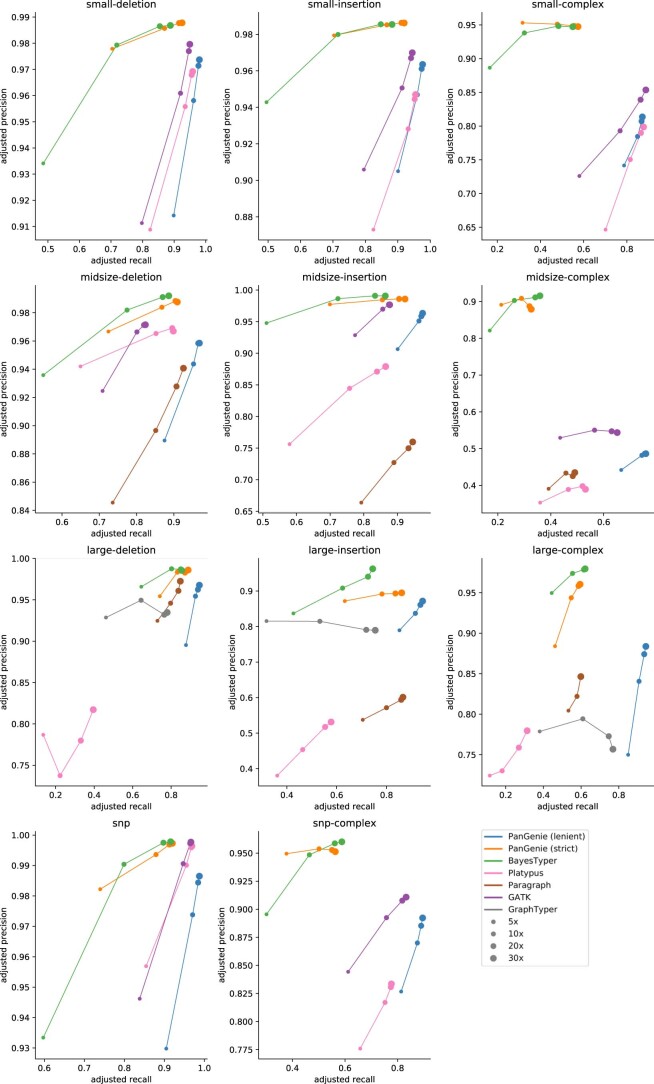
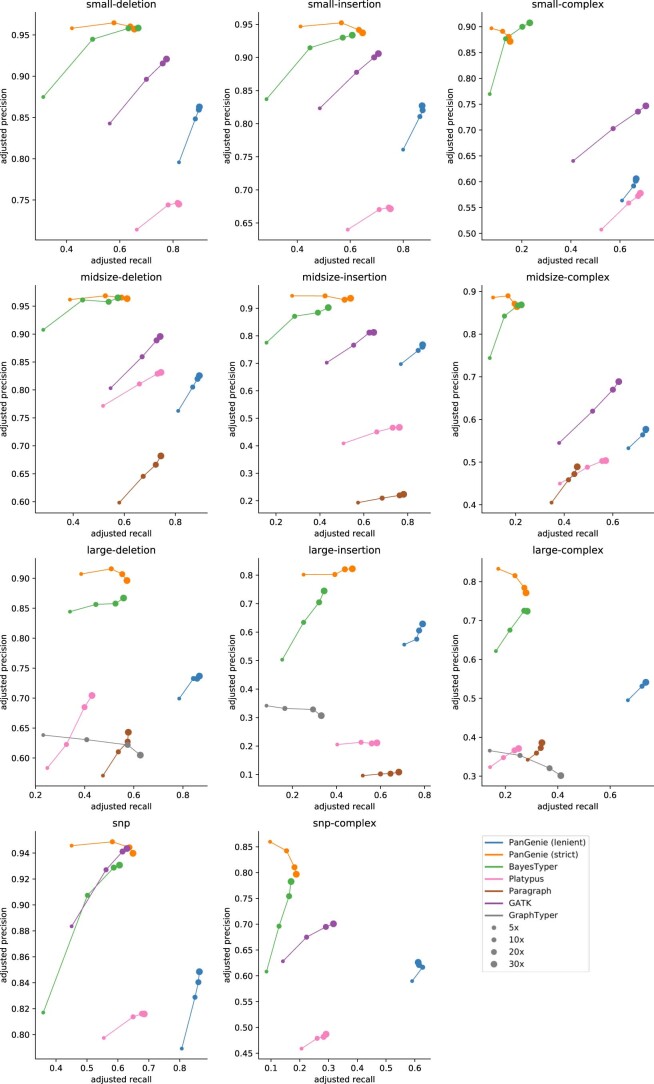
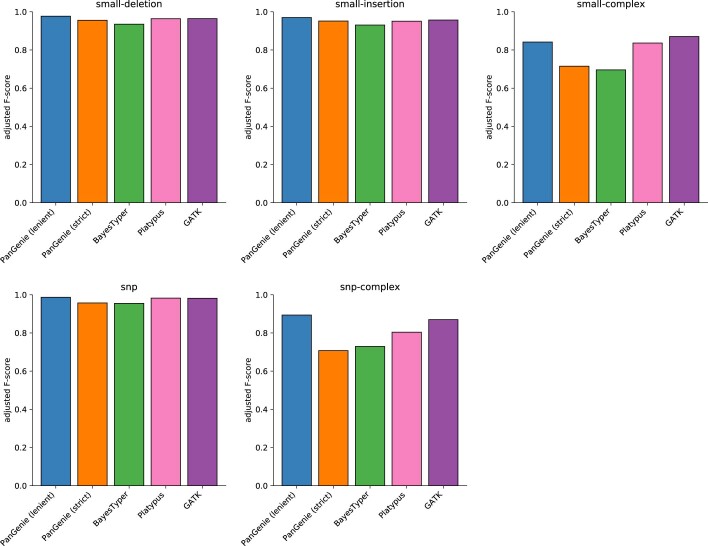
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
