

Multi-animal pose estimation, identification and tracking with DeepLabCut
- PMID: 35414125
- PMCID: PMC9007739
- DOI: 10.1038/s41592-022-01443-0
Multi-animal pose estimation, identification and tracking with DeepLabCut
Abstract
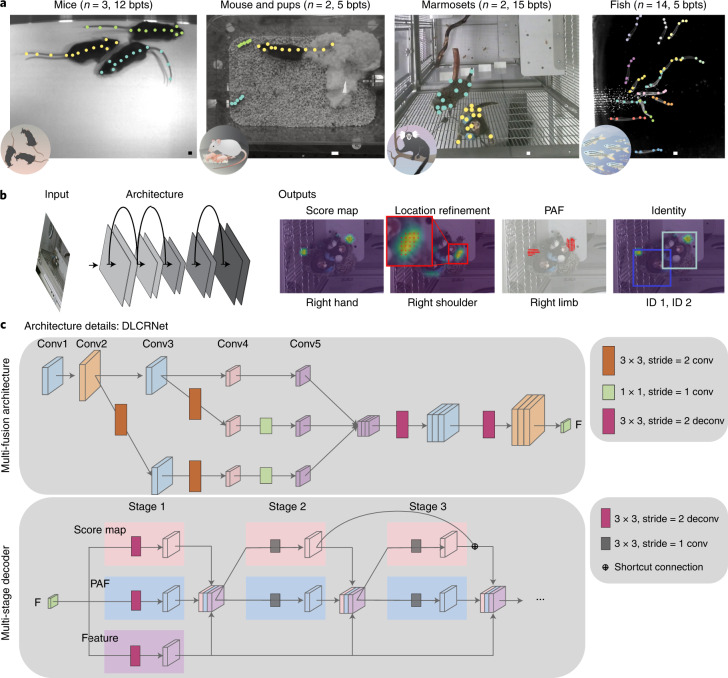
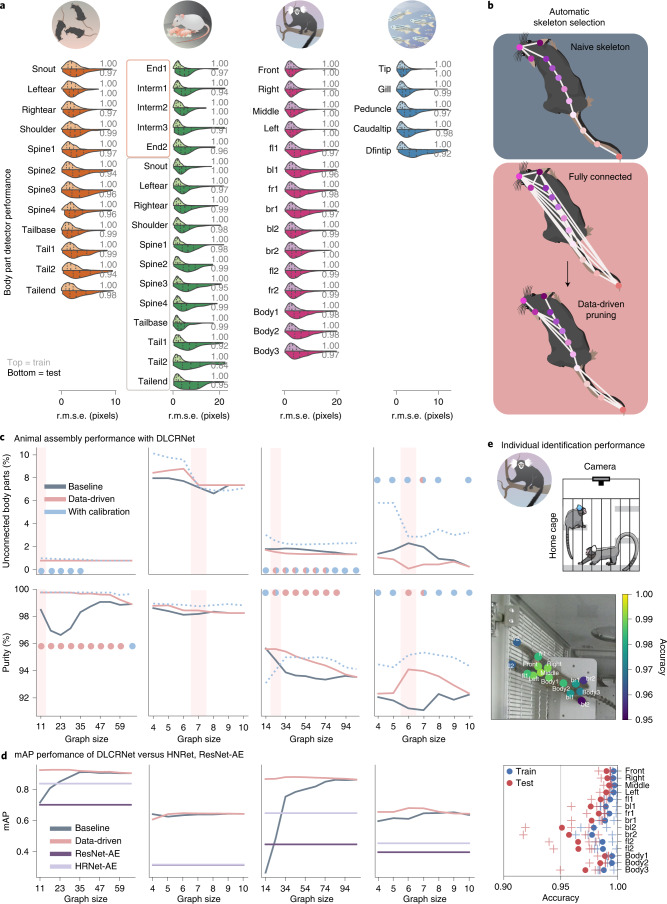
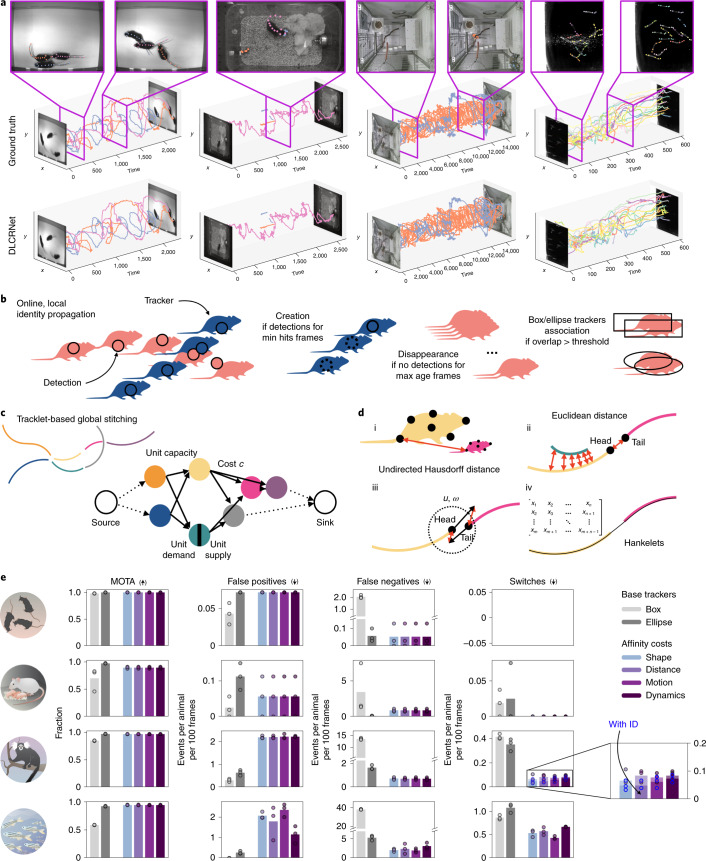
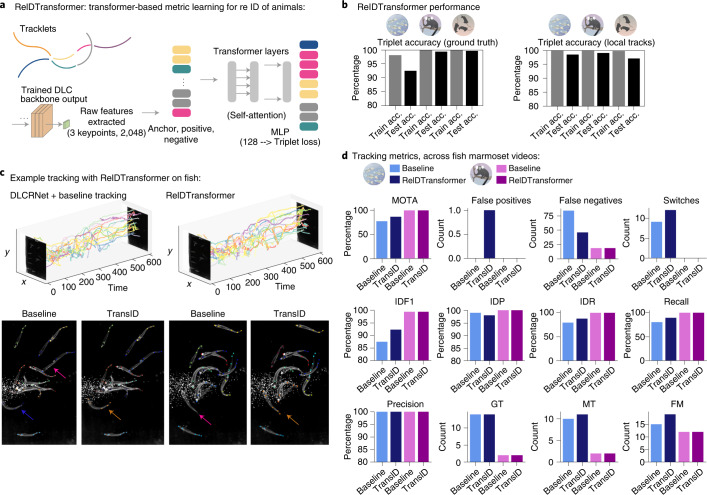
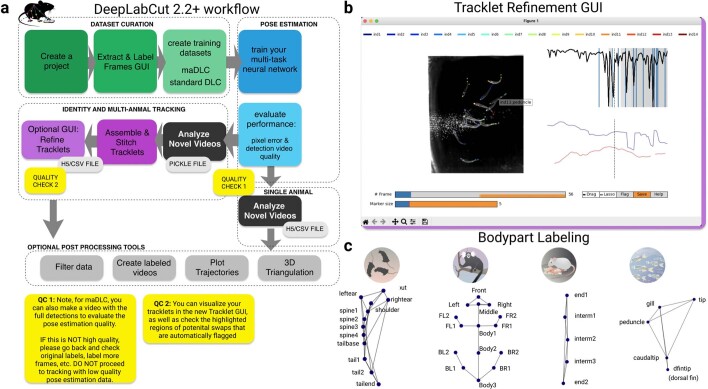
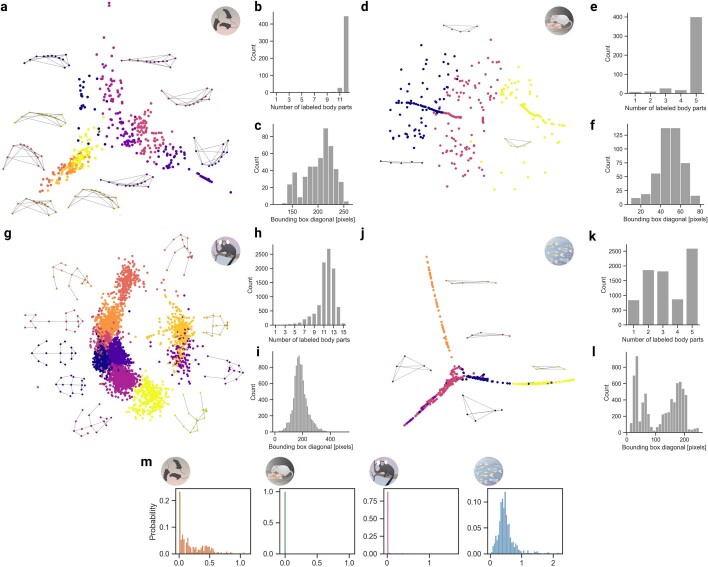
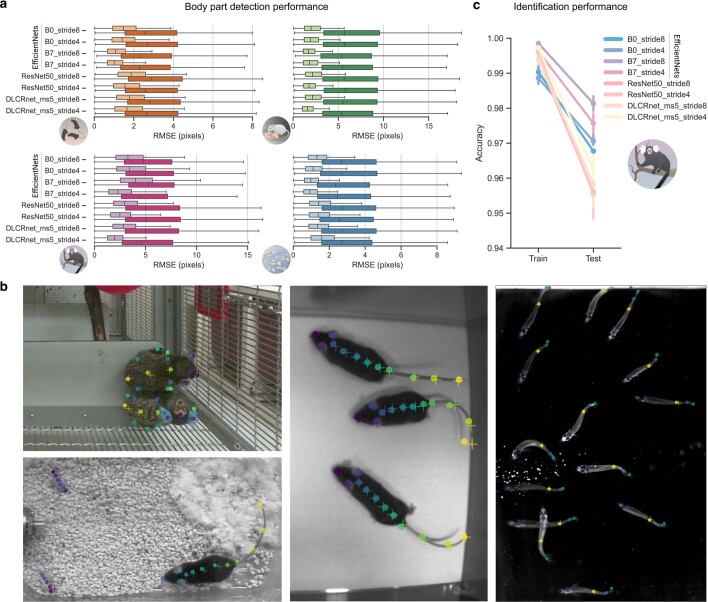
Estimating the pose of multiple animals is a challenging computer vision problem: frequent interactions cause occlusions and complicate the association of detected keypoints to the correct individuals, as well as having highly similar looking animals that interact more closely than in typical multi-human scenarios. To take up this challenge, we build on DeepLabCut, an open-source pose estimation toolbox, and provide high-performance animal assembly and tracking-features required for multi-animal scenarios. Furthermore, we integrate the ability to predict an animal's identity to assist tracking (in case of occlusions). We illustrate the power of this framework with four datasets varying in complexity, which we release to serve as a benchmark for future algorithm development.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

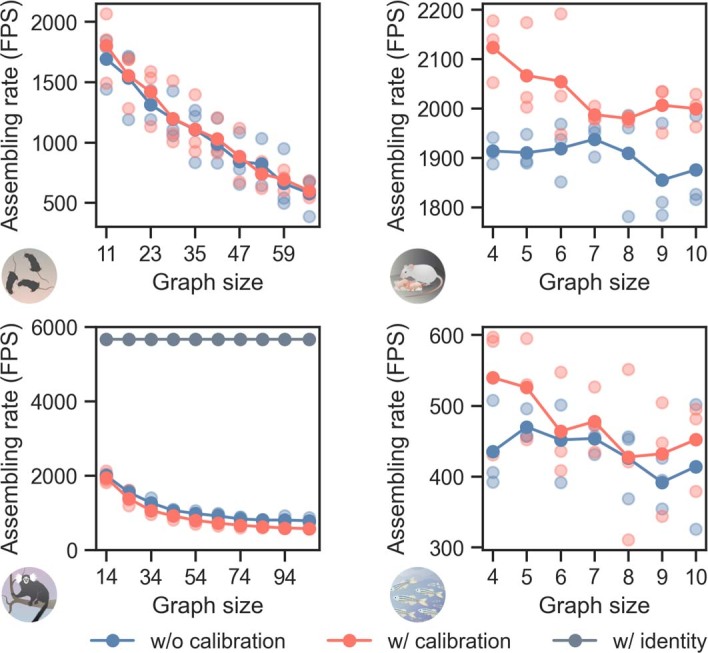
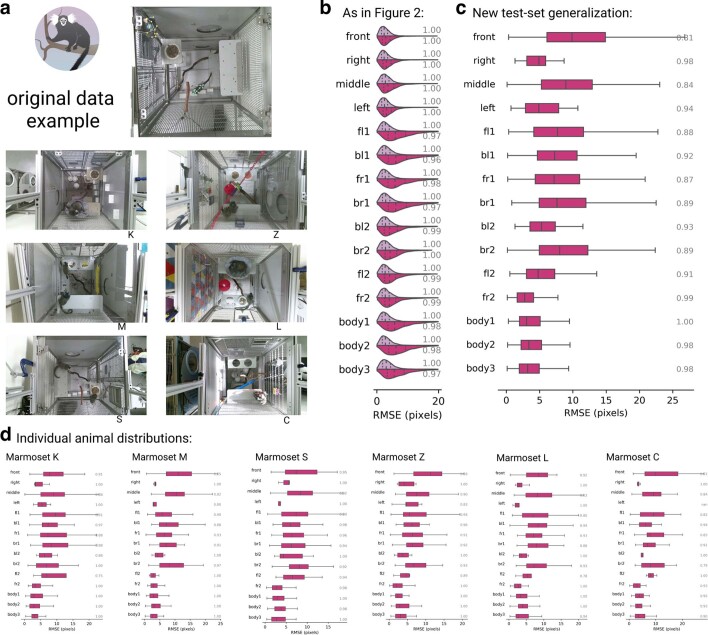

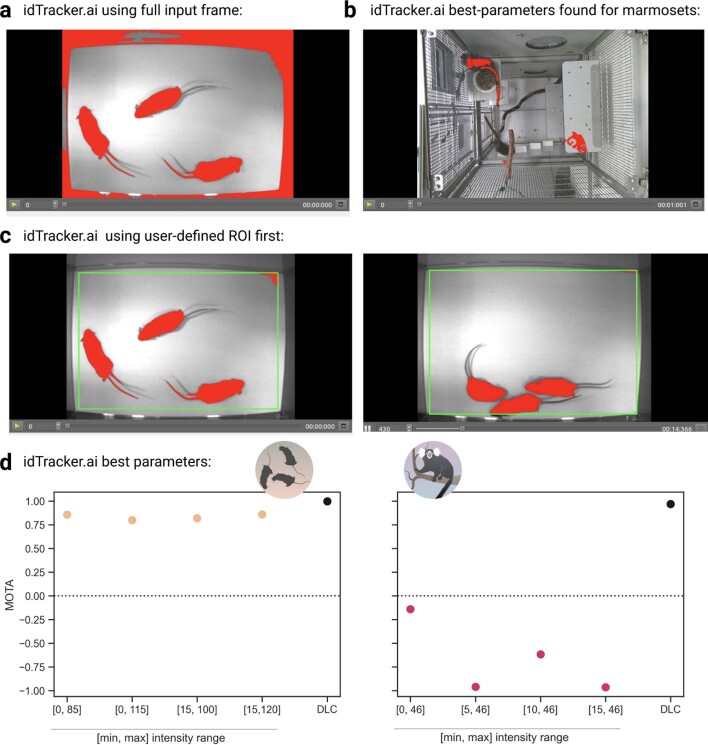
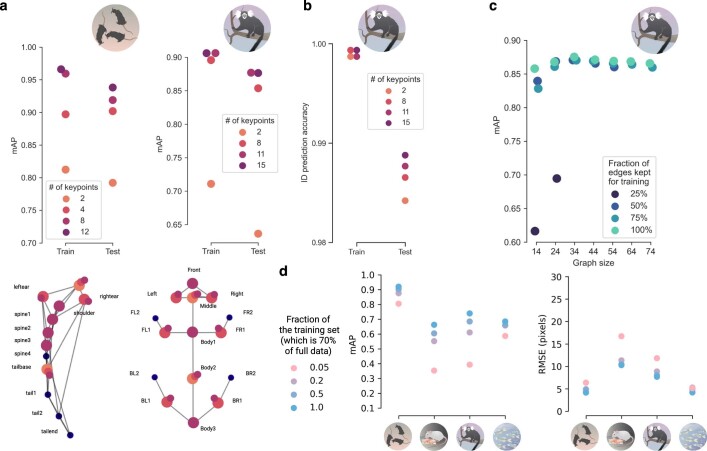
Comment in
-
Tracking together: estimating social poses.Nat Methods. 2022 Apr;19(4):410-411. doi: 10.1038/s41592-022-01452-z. Nat Methods. 2022. PMID: 35414127 No abstract available.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
