

A Classification Algorithm-Based Hybrid Diabetes Prediction Model
- PMID: 35433625
- PMCID: PMC9008347
- DOI: 10.3389/fpubh.2022.829519
A Classification Algorithm-Based Hybrid Diabetes Prediction Model
Abstract
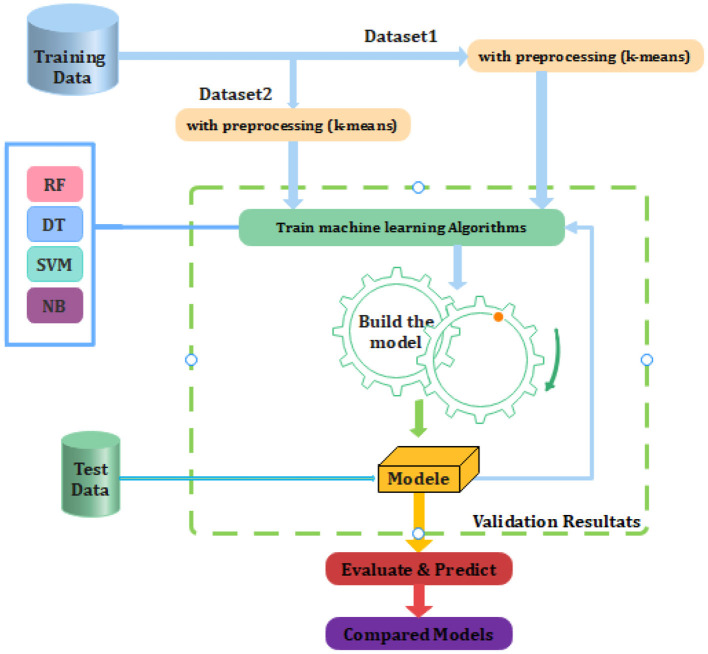
Diabetes is considered to be one of the leading causes of death globally. If diabetes is not treated and detected early, it can lead to a variety of complications. The aim of this study was to develop a model that can accurately predict the likelihood of developing diabetes in patients with the greatest amount of precision. Classification algorithms are widely used in the medical field to classify data into different categories based on some criteria that are relatively restrictive to the individual classifier, Therefore, four machine learning classification algorithms, namely supervised learning algorithms (Random forest, SVM and Naïve Bayes, Decision Tree DT) and unsupervised learning algorithm (k-means), have been a technique that was utilized in this investigation to identify diabetes in its early stages. The experiments are per-formed on two databases, one extracted from the Frankfurt Hospital in Germany and the other from the database. PIMA Indian Diabetes (PIDD) provided by the UCI machine learning repository. The results obtained from the database extracted from Frankfurt Hospital, Germany, showed that the random forest algorithm outperformed with the highest accuracy of 97.6%, and the results obtained from the Pima Indian database showed that the SVM algorithm outperformed with the highest accuracy of 83.1% compared to other algorithms. The validity of these results is confirmed by the process of separating the data set into two parts: a training set and a test set, which is described below. The training set is used to develop the model's capabilities. The test set is used to put the model through its paces and determine its correctness.
Keywords: AI; Bayesian Naive; ML; Support Vector Machine (SVM); classification; decision tree; diabetes; random forest.
Copyright © 2022 Edeh, Khalaf, Tavera, Tayeb, Ghouali, Abdulsahib, Richard-Nnabu and Louni.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
-
- Organisation mondiale de la santé . Rapport mondial sur le diabète. (2016). p. 88
-
- Medtronic . Le Diabète En Quelque Mots. [En ligne]. Available online at: https://www.parlonsdiabete.com/parlonsdiabete/le-diabete-en-quelques-mots (accessed November, 2021).
-
- Max Ray,. DIABETES -TYPE 2: The Review of Diabetic Studies. (2019). Available online at: https://www.researchgate.net/publication/336634065_DIABETES_-TYPE_2 (accessed September, 2021).
-
- Kumari VA, Chitra R. Classification de la maladie du diabète à l'aide d'une machine à vecteur de soutien. IJERA. (2013) 3:1797–801.
-
- Ahmed TM. Using data mining to develop model for classifying diabetic patient control level based on historical medical records. J Theor Appl Inf Technol. (2016) 87:316–23.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical