

Generation of human islet cell type-specific identity genesets
- PMID: 35440614
- PMCID: PMC9019032
- DOI: 10.1038/s41467-022-29588-8
Generation of human islet cell type-specific identity genesets
Erratum in
-
Author Correction: Generation of human islet cell type-specific identity genesets.Nat Commun. 2024 Mar 22;15(1):2574. doi: 10.1038/s41467-024-46525-z. Nat Commun. 2024. PMID: 38519459 Free PMC article. No abstract available.
Abstract
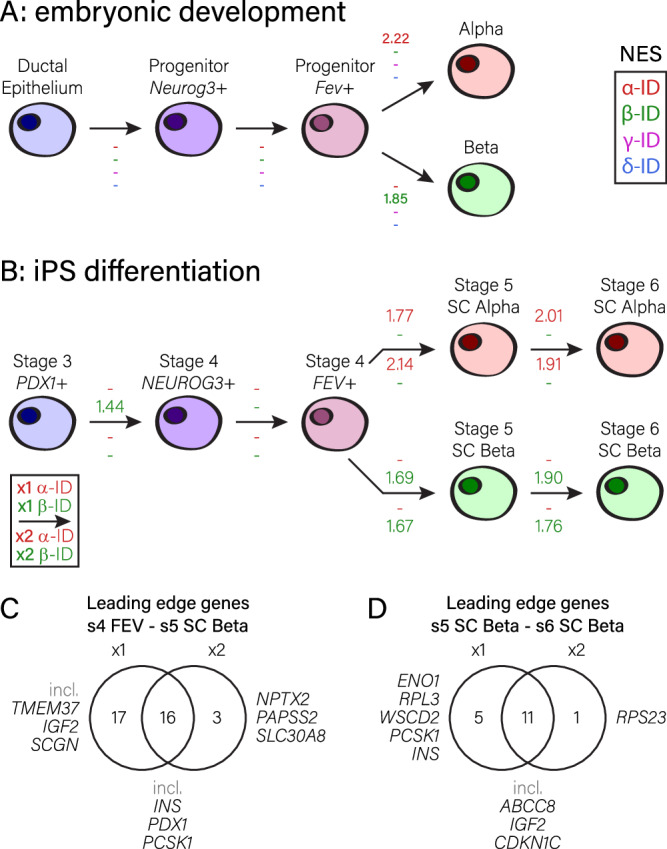
Generation of surrogate cells with stable functional identities is crucial for developing cell-based therapies. Efforts to produce insulin-secreting replacement cells to treat diabetes require reliable tools to assess islet cellular identity. Here, we conduct a thorough single-cell transcriptomics meta-analysis to identify robustly expressed markers used to build genesets describing the identity of human α-, β-, γ- and δ-cells. These genesets define islet cellular identities better than previously published genesets. We show their efficacy to outline cell identity changes and unravel some of their underlying genetic mechanisms, whether during embryonic pancreas development or in experimental setups aiming at developing glucose-responsive insulin-secreting cells, such as pluripotent stem-cell differentiation or in adult islet cell reprogramming protocols. These islet cell type-specific genesets represent valuable tools that accurately benchmark gain and loss in islet cell identity traits.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
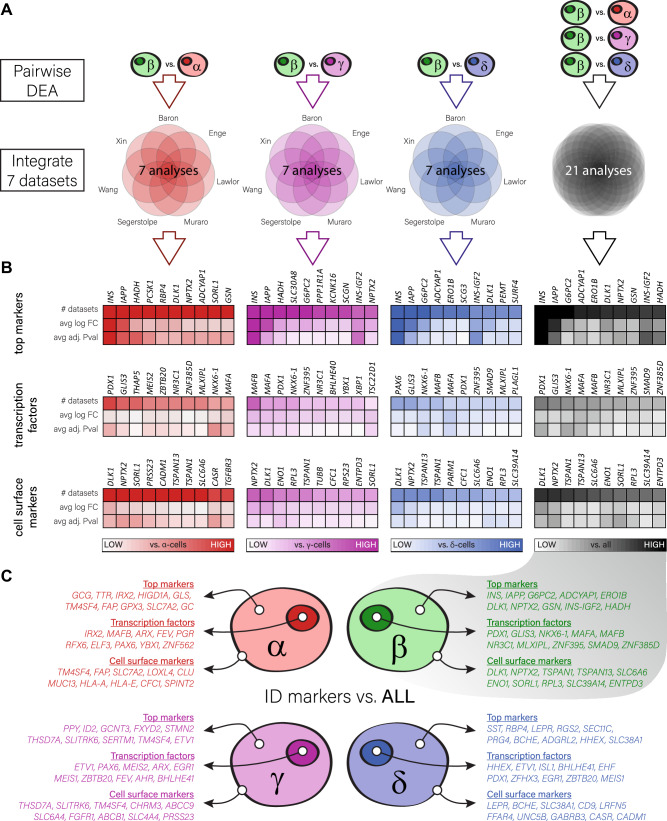
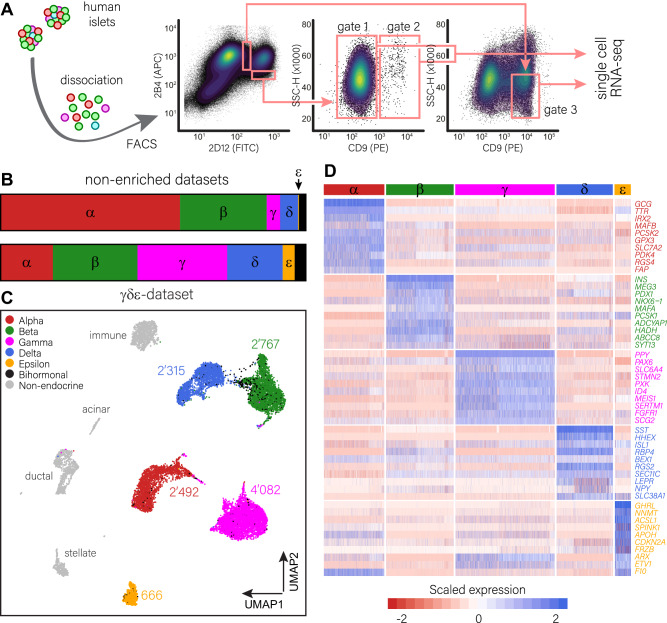
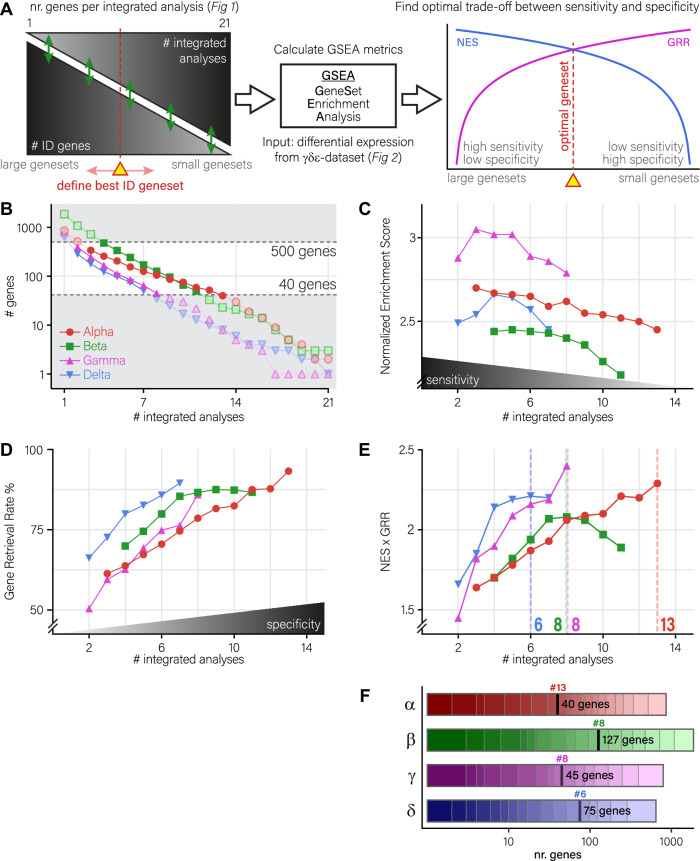
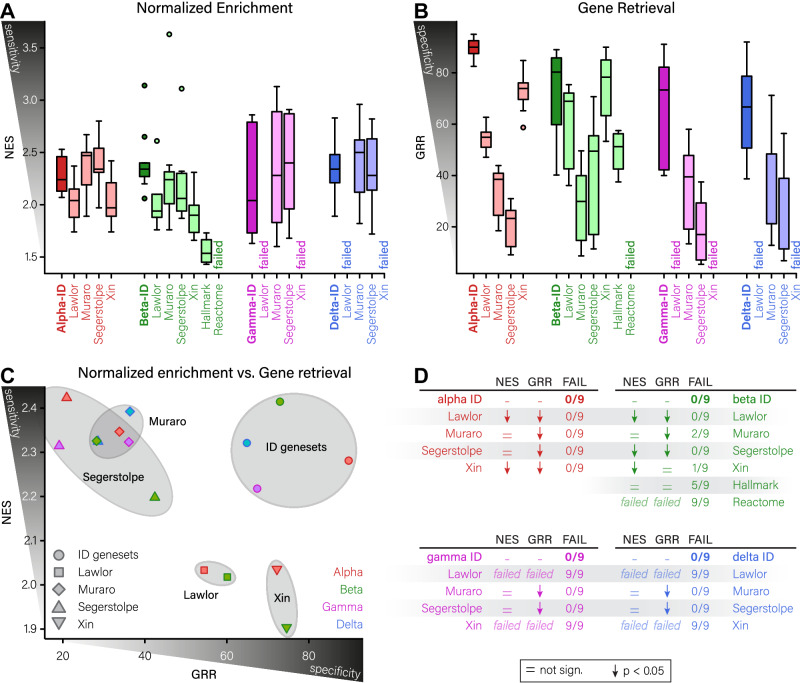
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
