

Harnessing the Power of Artificial Intelligence in Otolaryngology and the Communication Sciences
- PMID: 35441936
- PMCID: PMC9086071
- DOI: 10.1007/s10162-022-00846-2
Harnessing the Power of Artificial Intelligence in Otolaryngology and the Communication Sciences
Abstract
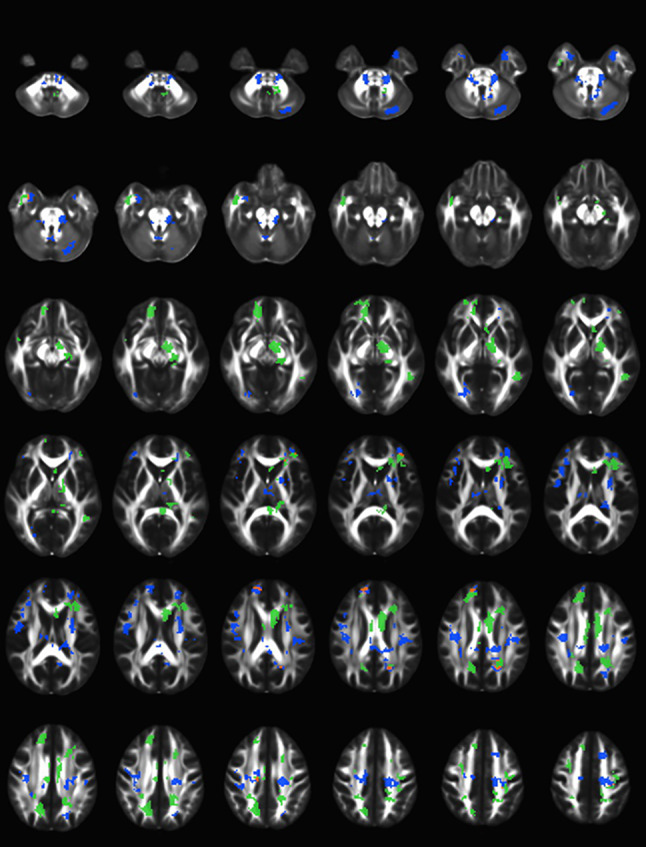
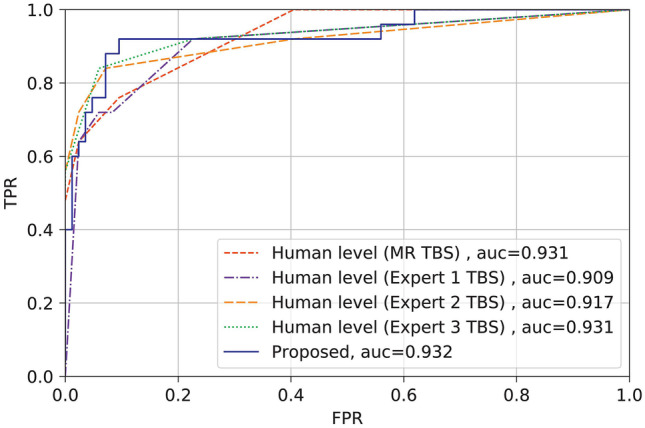
Use of artificial intelligence (AI) is a burgeoning field in otolaryngology and the communication sciences. A virtual symposium on the topic was convened from Duke University on October 26, 2020, and was attended by more than 170 participants worldwide. This review presents summaries of all but one of the talks presented during the symposium; recordings of all the talks, along with the discussions for the talks, are available at https://www.youtube.com/watch?v=ktfewrXvEFg and https://www.youtube.com/watch?v=-gQ5qX2v3rg . Each of the summaries is about 2500 words in length and each summary includes two figures. This level of detail far exceeds the brief summaries presented in traditional reviews and thus provides a more-informed glimpse into the power and diversity of current AI applications in otolaryngology and the communication sciences and how to harness that power for future applications.
Keywords: Artificial intelligence; Auditory prostheses; Auditory system; Brain-computer interfaces; Cochlear implants; Deep learning; Hearing; Hearing aids; Hearing loss; Human communication; Laryngeal pathology; Machine learning; Neural prostheses; Neuroprostheses; Otolaryngology; Speech perception; Speech production; Thyroid pathology.
© 2022. The Author(s) under exclusive licence to Association for Research in Otolaryngology.
Conflict of interest statement
The authors declare no competing interest.
Figures










References
-
- Angrick M, Ottenhoff MC, Diener L, Ivucic D, Ivucic G, Goulis S, Saal J, Colon AJ, Wagner L, Krusienski DJ, Kubben PL, Schultz T, Herff C. Real-time synthesis of imagined speech processes from minimally invasive recordings of neural activity. Commun Biol. 2021;4(1):1055–1055. doi: 10.1038/s42003-021-02578-0. - DOI - PMC - PubMed
-
- Anon. Listen to this. Nat Mach Intell. 2021;3(2):101. doi: 10.1038/s42256-021-00313-2. - DOI
