

Survey on Self-Supervised Learning: Auxiliary Pretext Tasks and Contrastive Learning Methods in Imaging
- PMID: 35455214
- PMCID: PMC9029566
- DOI: 10.3390/e24040551
Survey on Self-Supervised Learning: Auxiliary Pretext Tasks and Contrastive Learning Methods in Imaging
Abstract
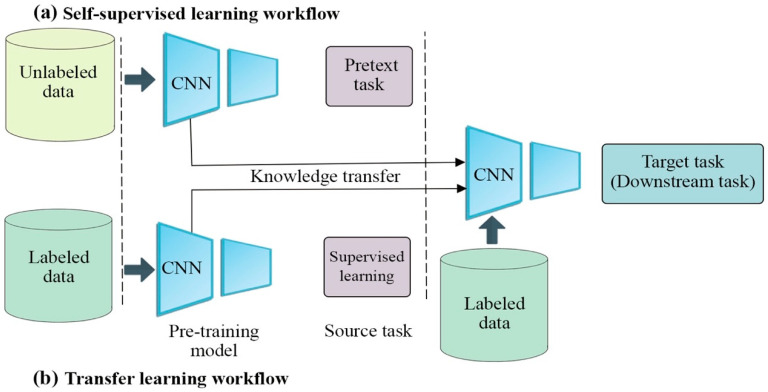
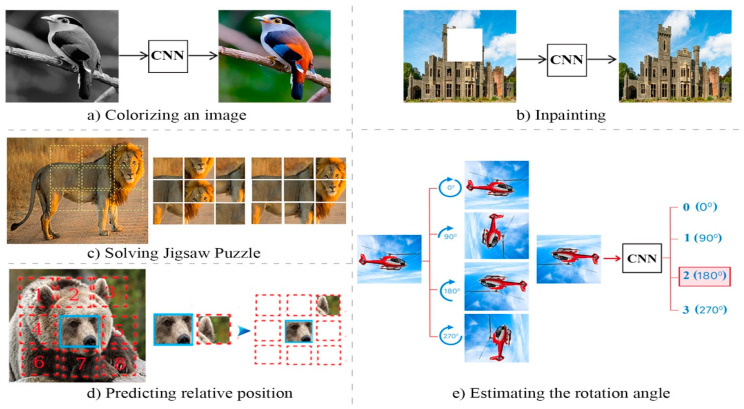
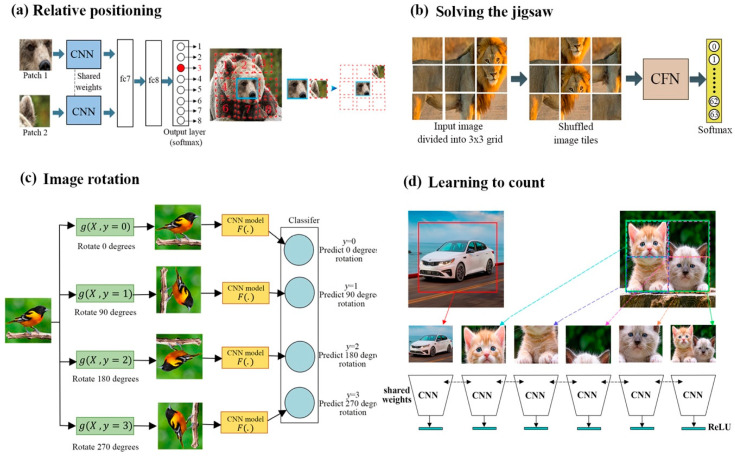
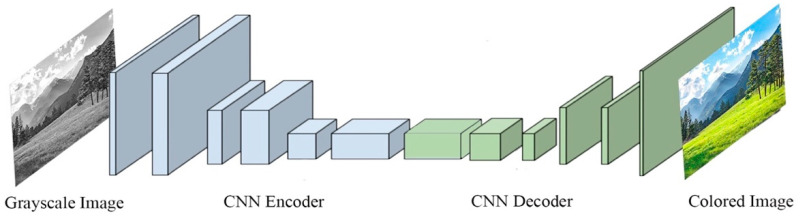
Although deep learning algorithms have achieved significant progress in a variety of domains, they require costly annotations on huge datasets. Self-supervised learning (SSL) using unlabeled data has emerged as an alternative, as it eliminates manual annotation. To do this, SSL constructs feature representations using pretext tasks that operate without manual annotation, which allows models trained in these tasks to extract useful latent representations that later improve downstream tasks such as object classification and detection. The early methods of SSL are based on auxiliary pretext tasks as a way to learn representations using pseudo-labels, or labels that were created automatically based on the dataset's attributes. Furthermore, contrastive learning has also performed well in learning representations via SSL. To succeed, it pushes positive samples closer together, and negative ones further apart, in the latent space. This paper provides a comprehensive literature review of the top-performing SSL methods using auxiliary pretext and contrastive learning techniques. It details the motivation for this research, a general pipeline of SSL, the terminologies of the field, and provides an examination of pretext tasks and self-supervised methods. It also examines how self-supervised methods compare to supervised ones, and then discusses both further considerations and ongoing challenges faced by SSL.
Keywords: auxiliary pretext tasks; contrastive learning; contrastive loss; data augmentation; downstream tasks; encoder; pretext tasks; self-supervised learning (SSL).
Conflict of interest statement
The author declares no conflict of interest.
Figures

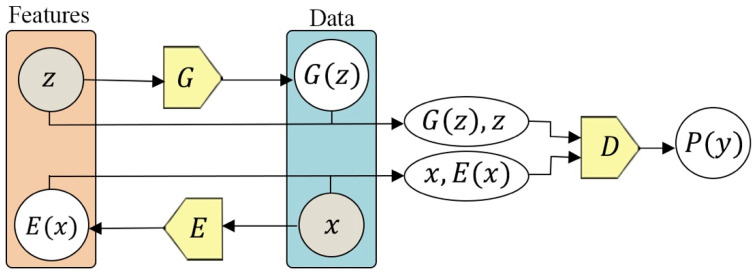
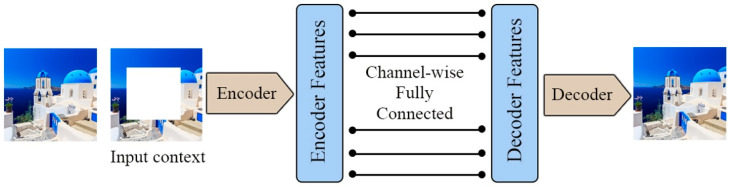
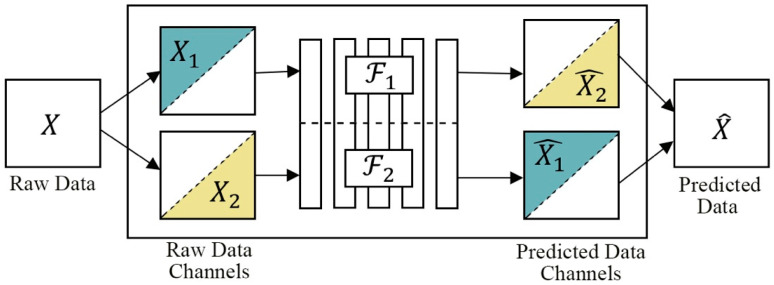
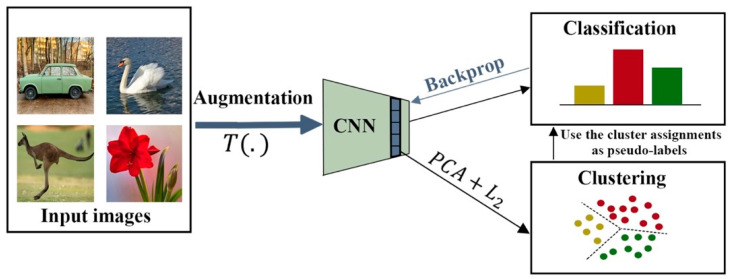
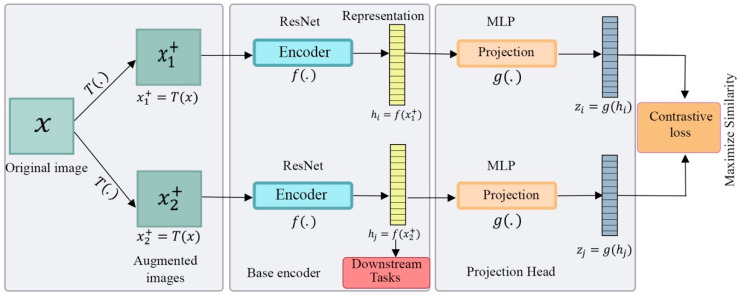
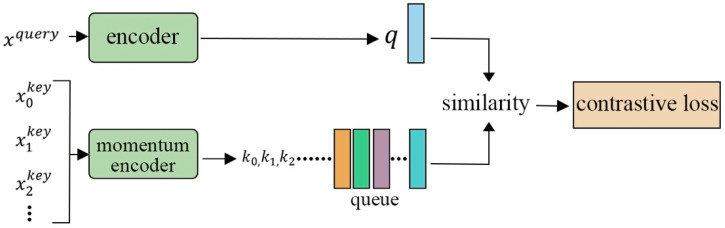
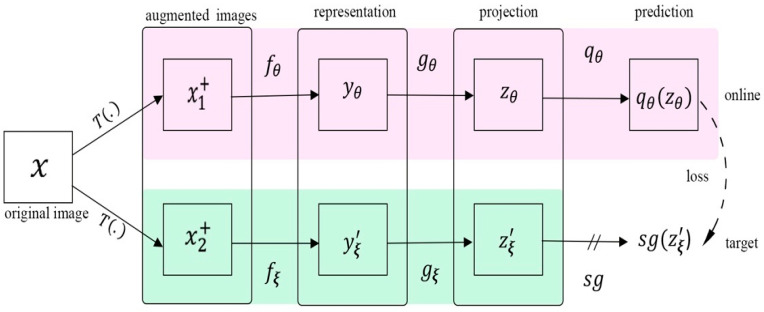
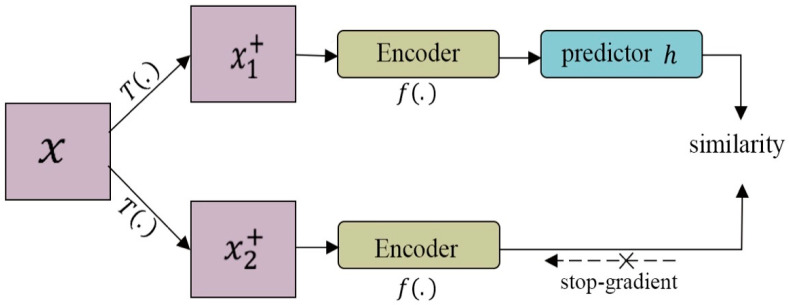
References
-
- Simonyan K., Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv. 20141409.1556
-
- He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, NV, USA. 27–30 June 2016; pp. 770–778.
-
- Liu W., Anguelov D., Erhan D., Szegedy C., Reed S., Fu C.-Y., Berg A.C. European Conference on Computer Vision. Springer; Berlin, Germany: 2016. Ssd: Single shot multibox detector; pp. 21–37.
-
- He K., Gkioxari G., Dollár P., Girshick R. Mask r-cnn; Proceedings of the IEEE International Conference on Computer Vision; Honolulu, HI, USA. 21–26 July 2017; pp. 2961–2969.
Publication types
LinkOut - more resources
Full Text Sources
