

Dual-Arm Robot Trajectory Planning Based on Deep Reinforcement Learning under Complex Environment
- PMID: 35457870
- PMCID: PMC9031963
- DOI: 10.3390/mi13040564
Dual-Arm Robot Trajectory Planning Based on Deep Reinforcement Learning under Complex Environment
Abstract
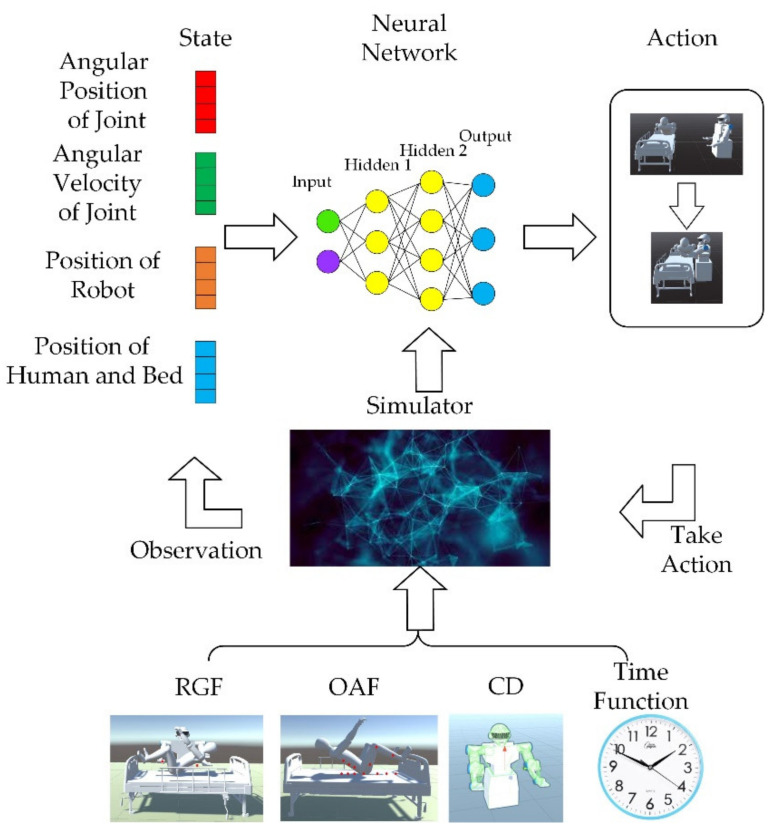
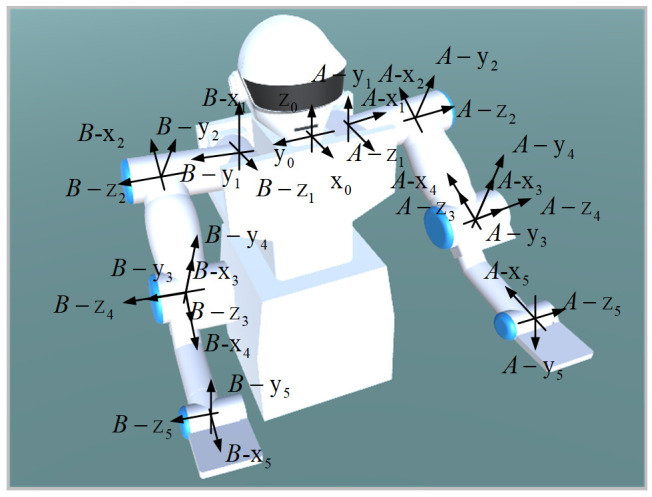
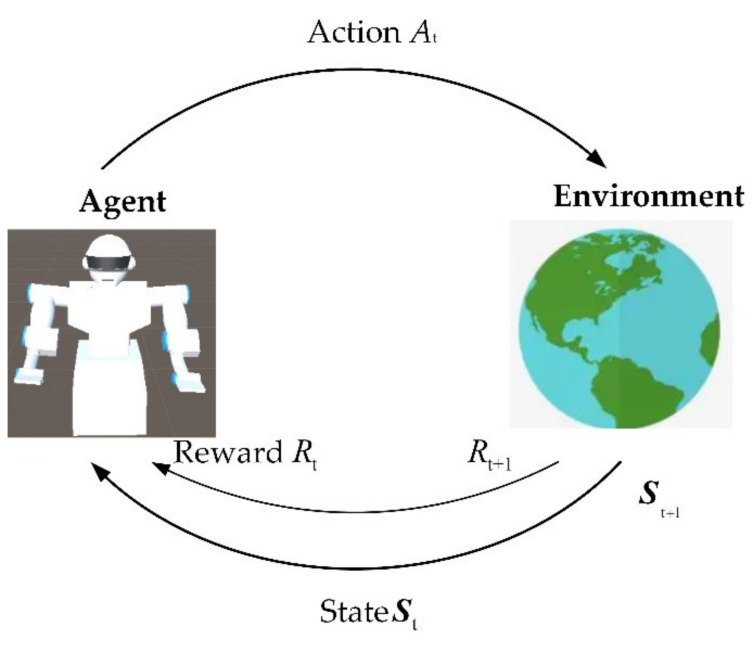
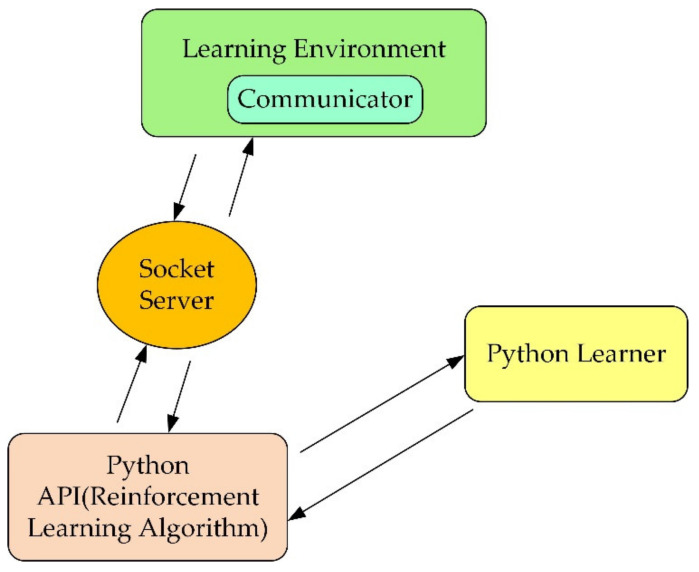
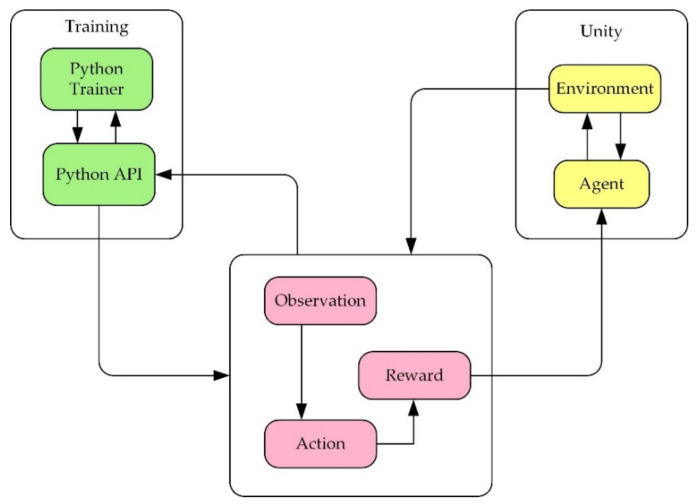
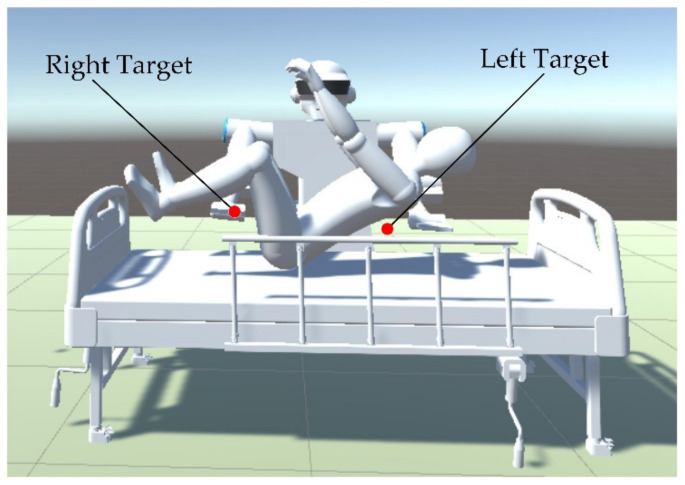
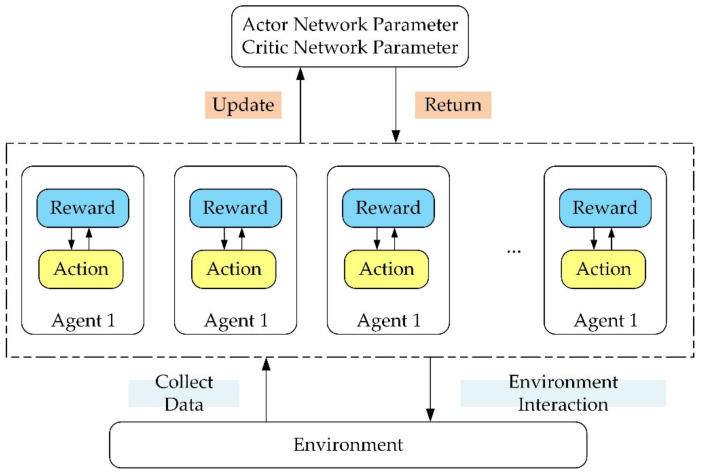
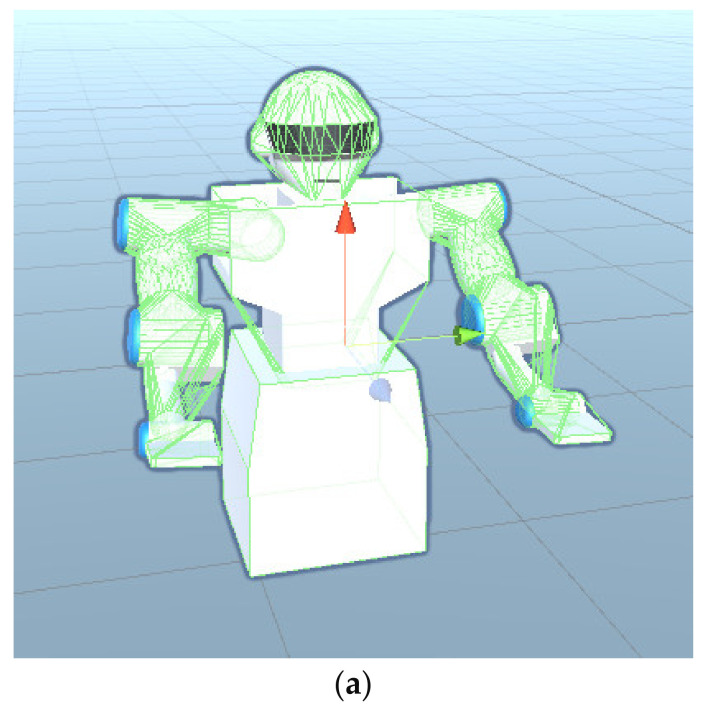
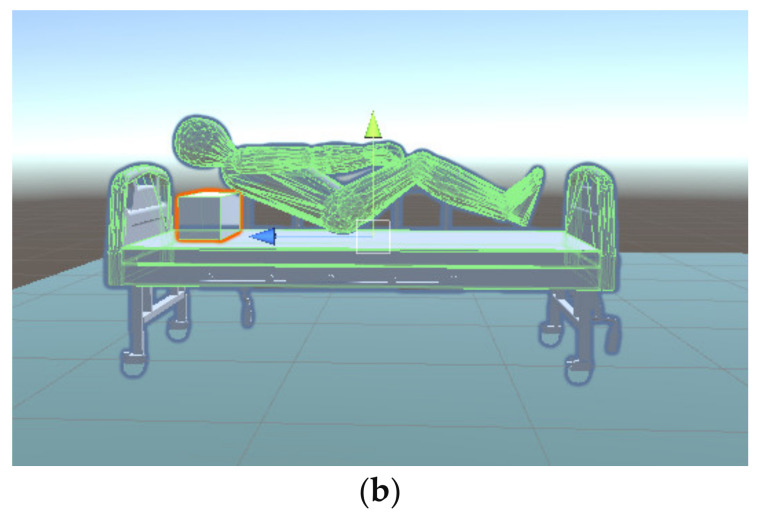
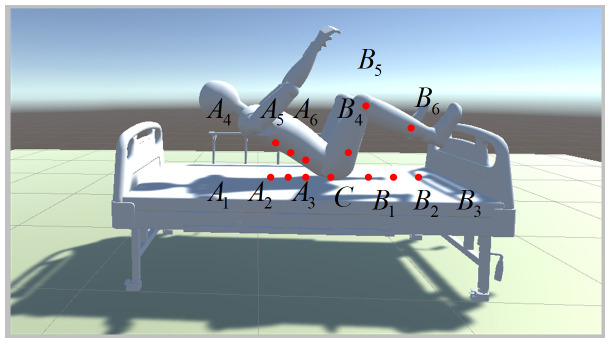
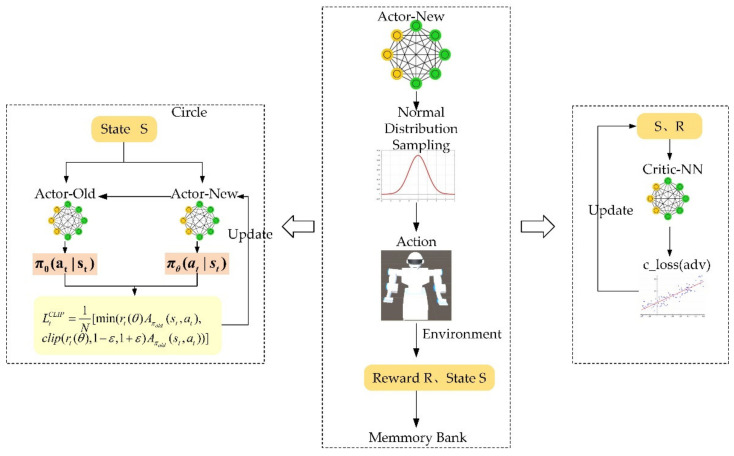
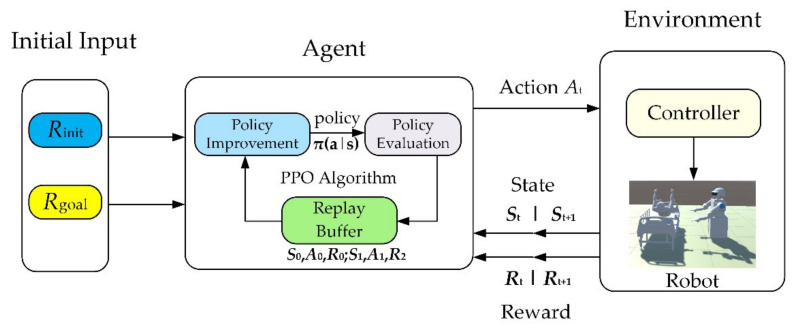
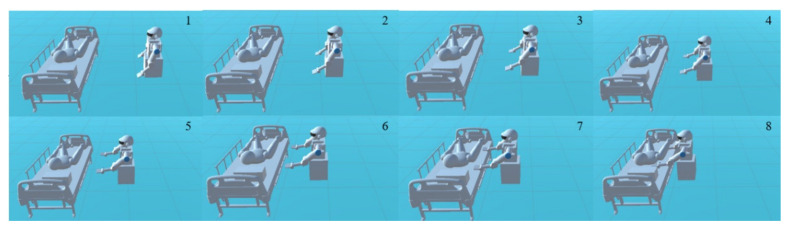
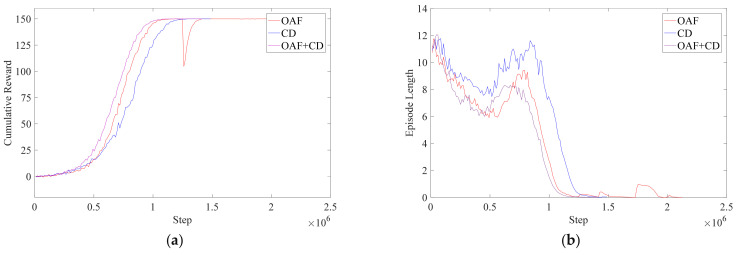
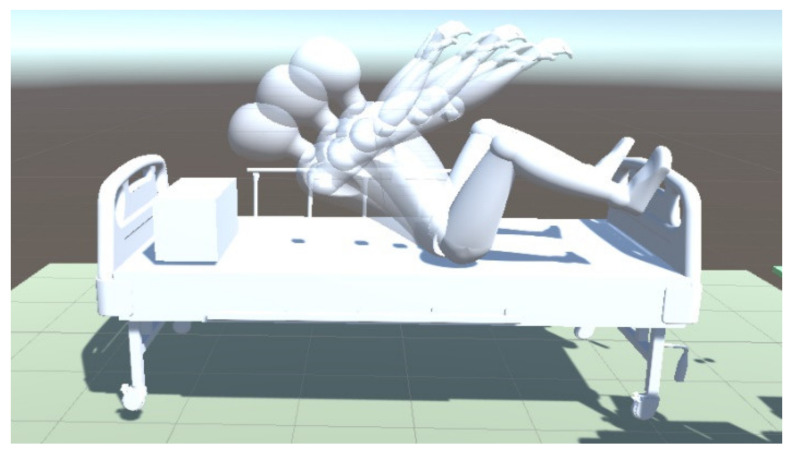
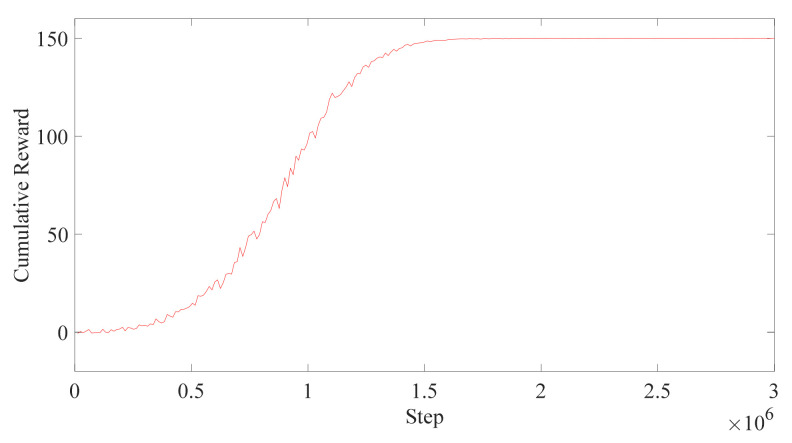
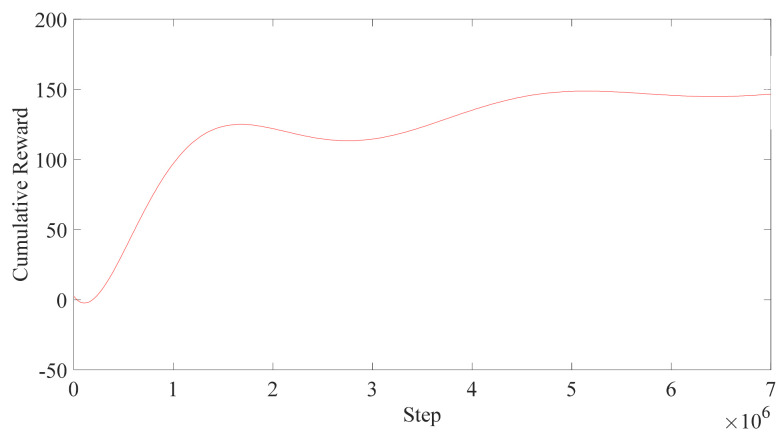
In this article, the trajectory planning of the two manipulators of the dual-arm robot is studied to approach the patient in a complex environment with deep reinforcement learning algorithms. The shape of the human body and bed is complex which may lead to the collision between the human and the robot. Because the sparse reward the robot obtains from the environment may not support the robot to accomplish the task, a neural network is trained to control the manipulators of the robot to prepare to hold the patient up by using a proximal policy optimization algorithm with a continuous reward function. Firstly, considering the realistic scene, the 3D simulation environment is built to conduct the research. Secondly, inspired by the idea of the artificial potential field, a new reward and punishment function was proposed to help the robot obtain enough rewards to explore the environment. The function is consisting of four parts which include the reward guidance function, collision detection, obstacle avoidance function, and time function. Where the reward guidance function is used to guide the robot to approach the targets to hold the patient, the collision detection and obstacle avoidance function are complementary to each other and are used to avoid obstacles, and the time function is used to reduce the number of training episode. Finally, after the robot is trained to reach the targets, the training results are analyzed. Compared with the DDPG algorithm, the PPO algorithm reduces about 4 million steps for training to converge. Moreover, compared with the other reward and punishment functions, the function used in this paper will obtain many more rewards at the same training time. Apart from that, it will take much less time to converge, and the episode length will be shorter; so, the advantage of the algorithm used in this paper is verified.
Keywords: complex environment; deep reinforcement learning; dual-arm robot; reward; trajectory planning.
Conflict of interest statement
The authors declare no conflict of interest.
Figures

References
-
- Kusuma M., Machbub C. Humanoid robot path planning and rerouting using A-Star search algorithm; Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys); Bandung, Indonesia. 16–18 July 2019.
-
- Liu W.H., Zheng X., Deng Z.H. Dynamic collision avoidance for cooperative fixed-wing UAV swarm based on normalized artificial potential field optimization. J. Cent. South Univ. 2021;28:3159–3172. doi: 10.1007/s11771-021-4840-5. - DOI
-
- Lee S.J., Baek S.H., Kim J.H. Arm trajectory generation based on rrt* for humanoid robot. Robot Intell. Technol. Appl. 2015;3:373–383.
LinkOut - more resources
Full Text Sources
