

GANterfactual-Counterfactual Explanations for Medical Non-experts Using Generative Adversarial Learning
- PMID: 35464995
- PMCID: PMC9024220
- DOI: 10.3389/frai.2022.825565
GANterfactual-Counterfactual Explanations for Medical Non-experts Using Generative Adversarial Learning
Abstract
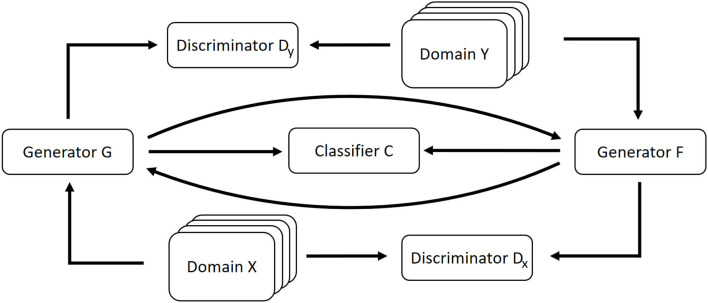
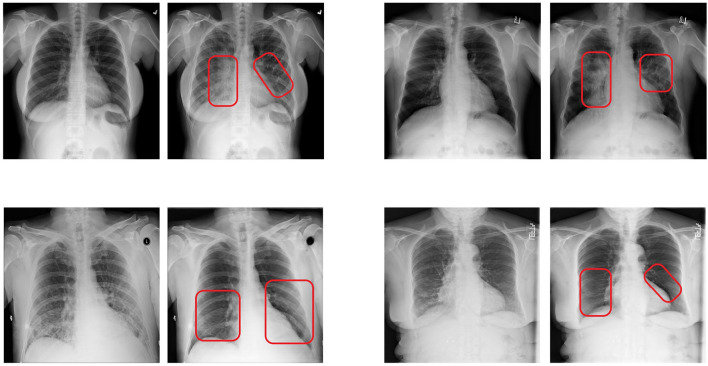
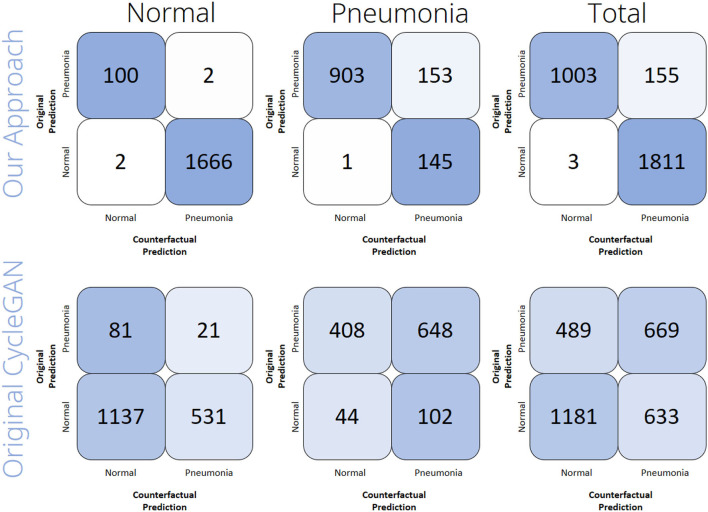
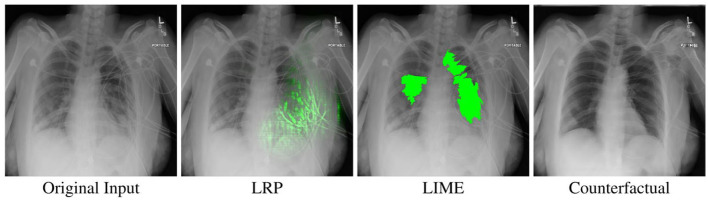
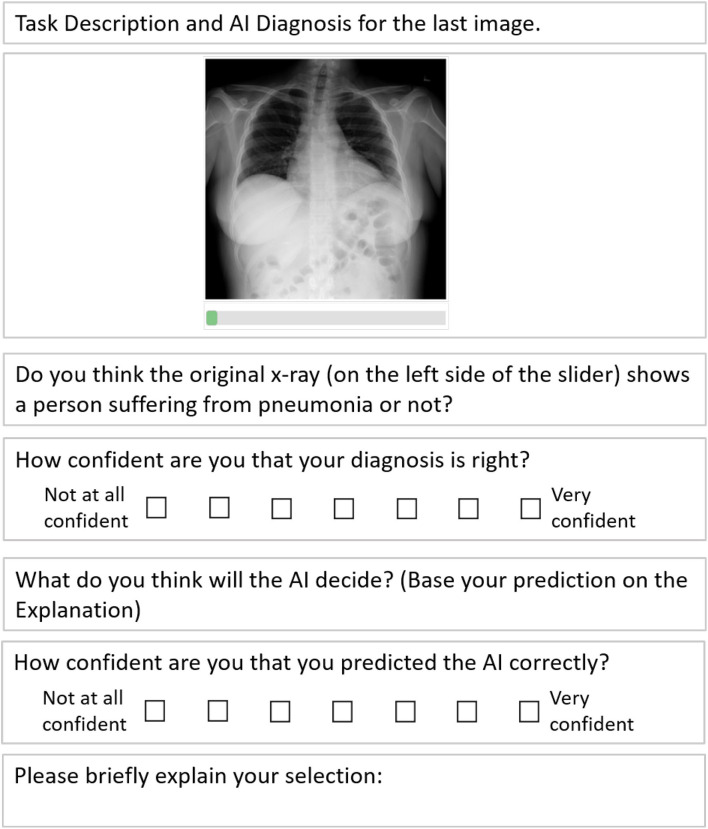
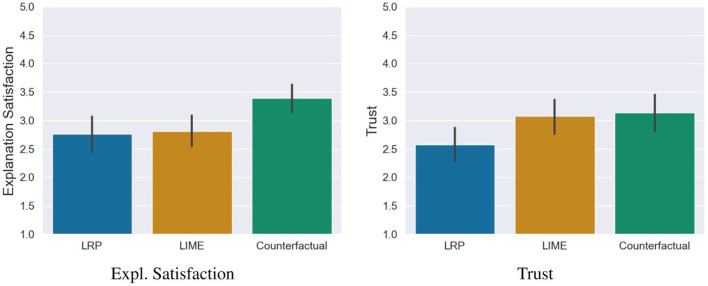
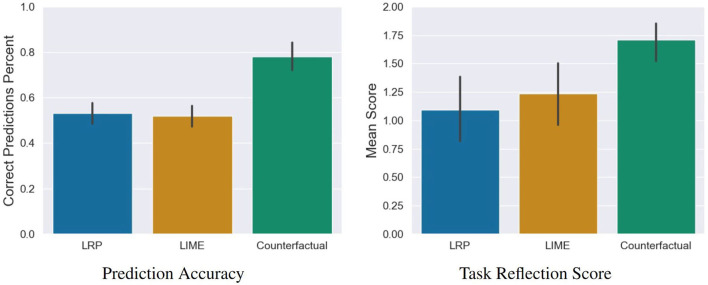
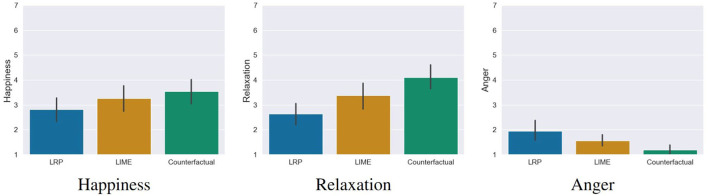
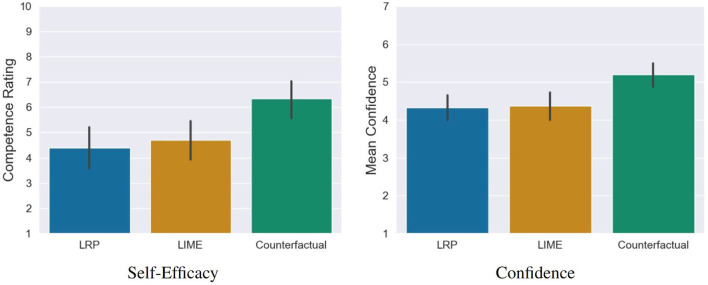
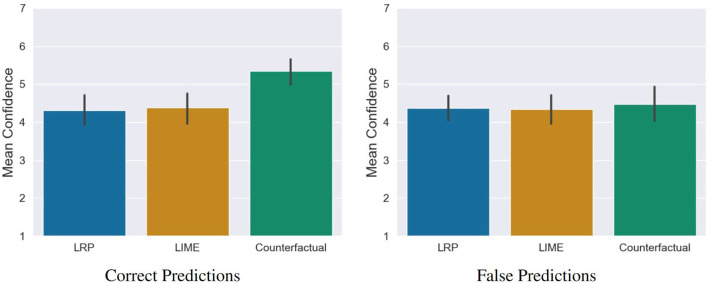
With the ongoing rise of machine learning, the need for methods for explaining decisions made by artificial intelligence systems is becoming a more and more important topic. Especially for image classification tasks, many state-of-the-art tools to explain such classifiers rely on visual highlighting of important areas of the input data. Contrary, counterfactual explanation systems try to enable a counterfactual reasoning by modifying the input image in a way such that the classifier would have made a different prediction. By doing so, the users of counterfactual explanation systems are equipped with a completely different kind of explanatory information. However, methods for generating realistic counterfactual explanations for image classifiers are still rare. Especially in medical contexts, where relevant information often consists of textural and structural information, high-quality counterfactual images have the potential to give meaningful insights into decision processes. In this work, we present GANterfactual, an approach to generate such counterfactual image explanations based on adversarial image-to-image translation techniques. Additionally, we conduct a user study to evaluate our approach in an exemplary medical use case. Our results show that, in the chosen medical use-case, counterfactual explanations lead to significantly better results regarding mental models, explanation satisfaction, trust, emotions, and self-efficacy than two state-of-the art systems that work with saliency maps, namely LIME and LRP.
Keywords: counterfactual explanations; explainable AI; generative adversarial networks; image-to-image translation; interpretable machine learning; machine learning.
Copyright © 2022 Mertes, Huber, Weitz, Heimerl and André.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Explaining the black-box smoothly-A counterfactual approach.Med Image Anal. 2023 Feb;84:102721. doi: 10.1016/j.media.2022.102721. Epub 2022 Dec 13. Med Image Anal. 2023. PMID: 36571975 Free PMC article.
-
Counterfactual Explanation of Brain Activity Classifiers Using Image-To-Image Transfer by Generative Adversarial Network.Front Neuroinform. 2022 Mar 16;15:802938. doi: 10.3389/fninf.2021.802938. eCollection 2021. Front Neuroinform. 2022. PMID: 35369003 Free PMC article.
-
Unveiling the decision making process in Alzheimer's disease diagnosis: A case-based counterfactual methodology for explainable deep learning.J Neurosci Methods. 2025 Jan;413:110318. doi: 10.1016/j.jneumeth.2024.110318. Epub 2024 Nov 9. J Neurosci Methods. 2025. PMID: 39528206
-
Artificial intelligence in molecular imaging.Ann Transl Med. 2021 May;9(9):824. doi: 10.21037/atm-20-6191. Ann Transl Med. 2021. PMID: 34268437 Free PMC article. Review.
-
The Next Generation of Medical Decision Support: A Roadmap Toward Transparent Expert Companions.Front Artif Intell. 2020 Sep 24;3:507973. doi: 10.3389/frai.2020.507973. eCollection 2020. Front Artif Intell. 2020. PMID: 33733193 Free PMC article. Review.
Cited by
-
Exploring interpretability in deep learning prediction of successful ablation therapy for atrial fibrillation.Front Physiol. 2023 Mar 14;14:1054401. doi: 10.3389/fphys.2023.1054401. eCollection 2023. Front Physiol. 2023. PMID: 36998987 Free PMC article.
-
MiMICRI: Towards Domain-centered Counterfactual Explanations of Cardiovascular Image Classification Models.FACCT 24 (2024). 2024 Jun;2024:1861-1874. doi: 10.1145/3630106.3659011. Epub 2024 Jun 5. FACCT 24 (2024). 2024. PMID: 39877054 Free PMC article.
-
A novel method to derive personalized minimum viable recommendations for type 2 diabetes prevention based on counterfactual explanations.PLoS One. 2022 Nov 17;17(11):e0272825. doi: 10.1371/journal.pone.0272825. eCollection 2022. PLoS One. 2022. PMID: 36395096 Free PMC article.
-
FUTURE-AI: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare.BMJ. 2025 Feb 5;388:e081554. doi: 10.1136/bmj-2024-081554. BMJ. 2025. PMID: 39909534 Free PMC article.
-
Dissection of medical AI reasoning processes via physician and generative-AI collaboration.medRxiv [Preprint]. 2023 May 16:2023.05.12.23289878. doi: 10.1101/2023.05.12.23289878. medRxiv. 2023. PMID: 37292705 Free PMC article. Preprint.
References
-
- Ahsan M. M., Gupta K. D., Islam M., Sen S., Rahman M. L., Hossain M. (2020). Study of different deep learning approach with explainable AI for screening patients with COVID-19 symptoms: using CT scan and chest x-ray image dataset. CoRR. Available online at: https://arxiv.org/abs/2007.12525
-
- Alqaraawi A., Schuessler M., Weiß P., Costanza E., Berthouze N. (2020). Evaluating saliency map explanations for convolutional neural networks: a user study, in IUI '20: 25th International Conference on Intelligent User Interfaces (Cagliari: ), 275–285. 10.1145/3377325.3377519 - DOI
-
- Anderson A., Dodge J., Sadarangani A., Juozapaitis Z., Newman E., Irvine J., et al. . (2019). Explaining reinforcement learning to mere mortals: an empirical study, in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19 (Macao: ), 1328–1334. 10.24963/ijcai.2019/184 - DOI
-
- Arrieta A. B., Díaz-Rodríguez N., Del Ser J., Bennetot A., Tabik S., Barbado A., et al. . (2020). Explainable artificial intelligence (XAI): concepts, taxonomies, opportunities and challenges toward responsible AI. Inform. Fus. 58, 82–115. 10.1016/j.inffus.2019.12.012 - DOI
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous