

Swarm learning for decentralized artificial intelligence in cancer histopathology
- PMID: 35469069
- PMCID: PMC9205774
- DOI: 10.1038/s41591-022-01768-5
Swarm learning for decentralized artificial intelligence in cancer histopathology
Abstract
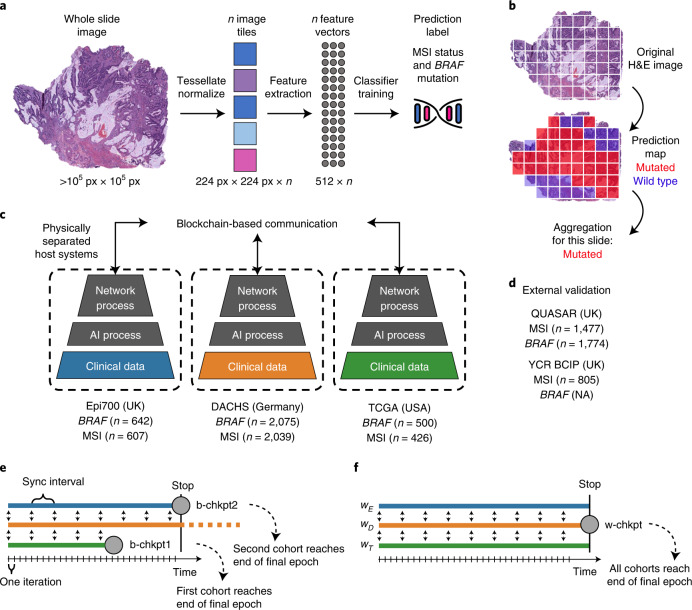
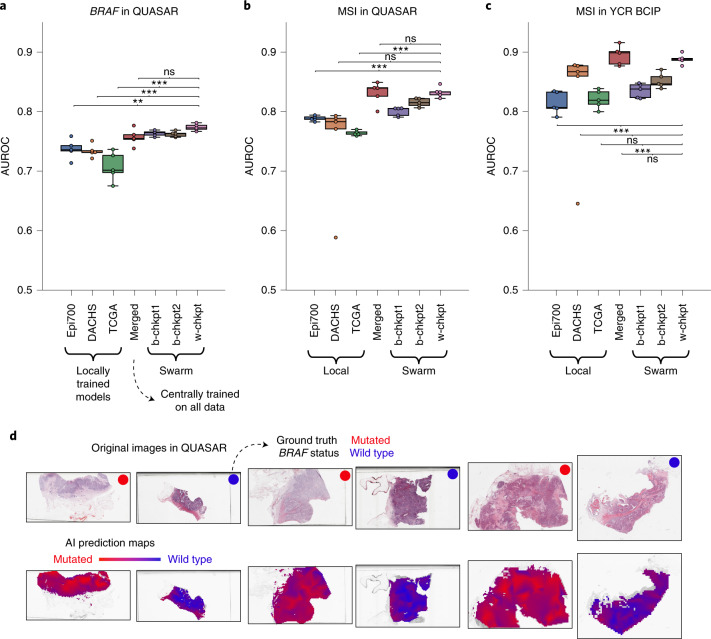
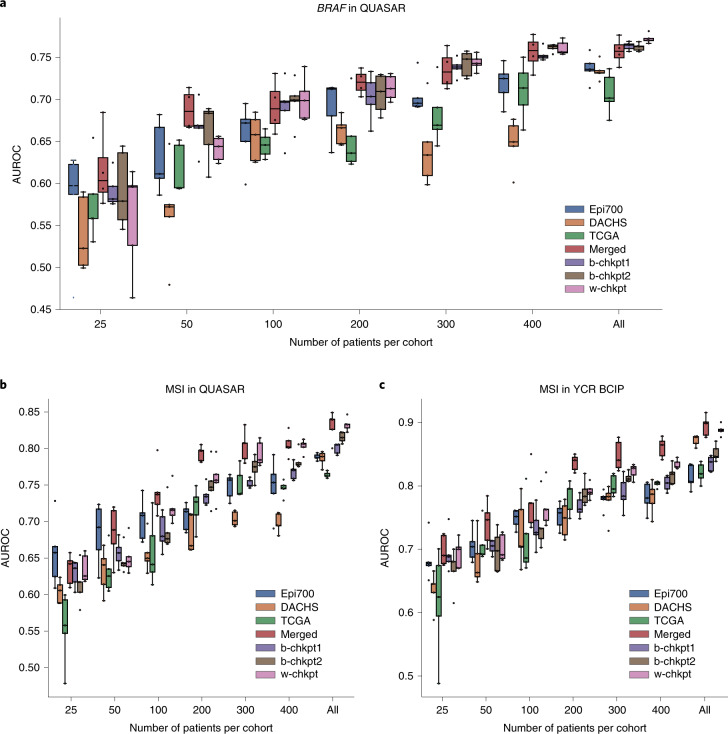
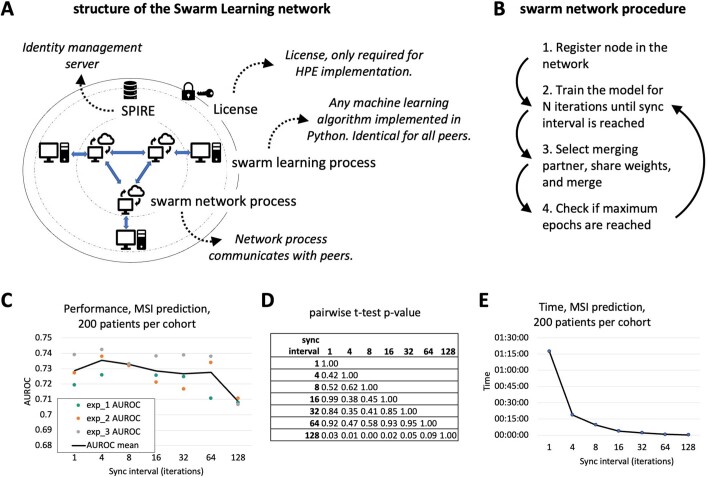
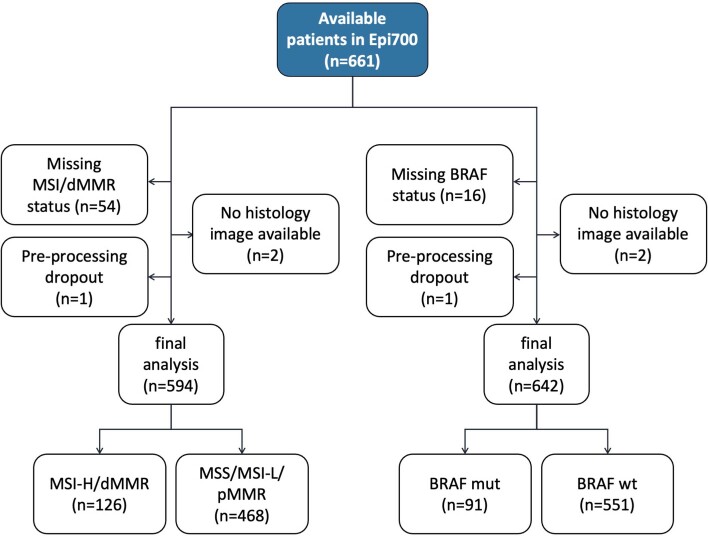
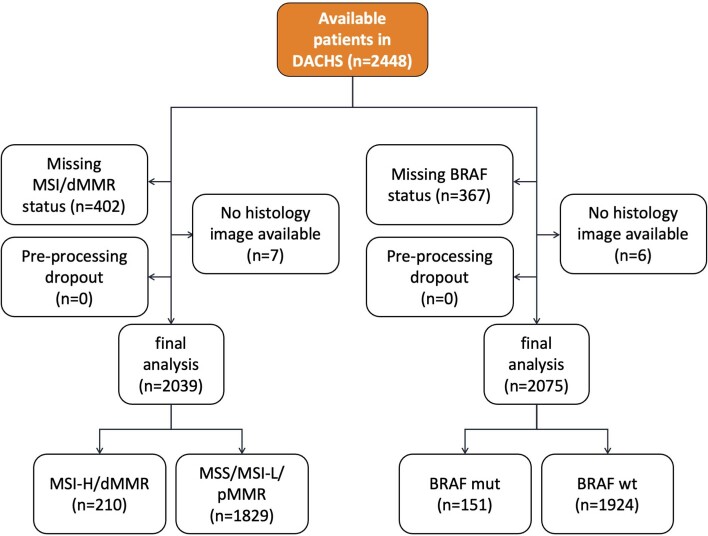
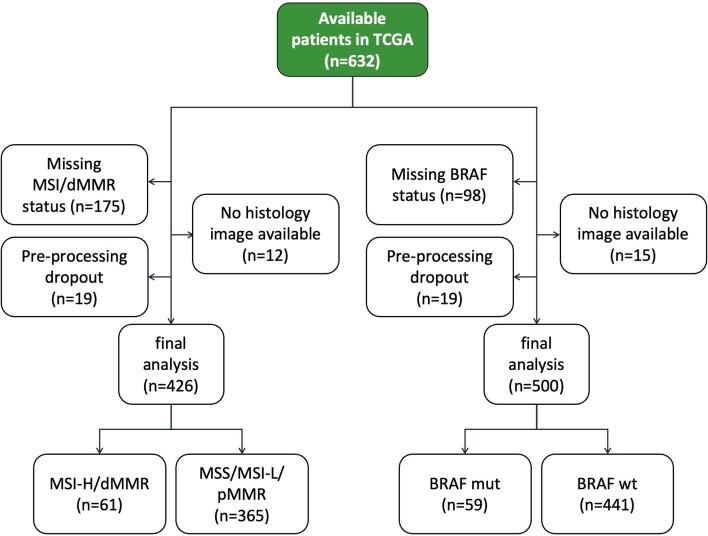
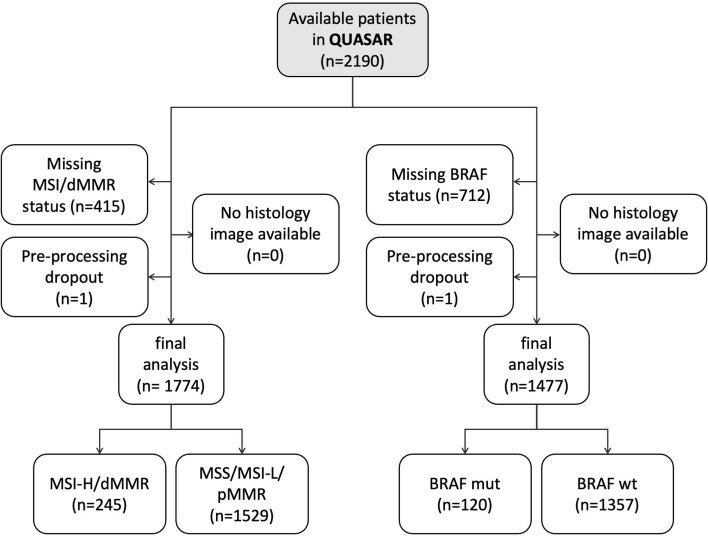
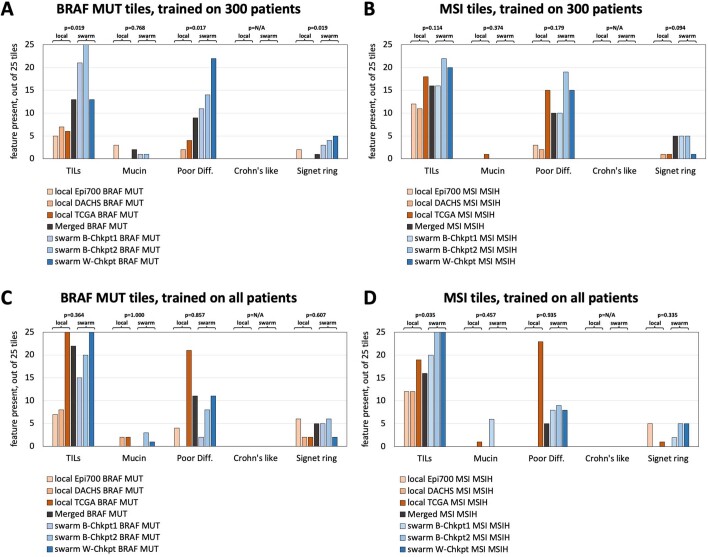
Artificial intelligence (AI) can predict the presence of molecular alterations directly from routine histopathology slides. However, training robust AI systems requires large datasets for which data collection faces practical, ethical and legal obstacles. These obstacles could be overcome with swarm learning (SL), in which partners jointly train AI models while avoiding data transfer and monopolistic data governance. Here, we demonstrate the successful use of SL in large, multicentric datasets of gigapixel histopathology images from over 5,000 patients. We show that AI models trained using SL can predict BRAF mutational status and microsatellite instability directly from hematoxylin and eosin (H&E)-stained pathology slides of colorectal cancer. We trained AI models on three patient cohorts from Northern Ireland, Germany and the United States, and validated the prediction performance in two independent datasets from the United Kingdom. Our data show that SL-trained AI models outperform most locally trained models, and perform on par with models that are trained on the merged datasets. In addition, we show that SL-based AI models are data efficient. In the future, SL can be used to train distributed AI models for any histopathology image analysis task, eliminating the need for data transfer.
© 2022. The Author(s).
Conflict of interest statement
J.N.K. declares consulting services for Owkin, France, and Panakeia, UK. P.Q. and N.P.W. declare research funding from Roche, and P.Q. declares consulting and speaker services for Roche. M.S.-T. has recently received honoraria for advisory work in relation to the following companies: Incyte, MindPeak, MSD, BMS and Sonrai; these are all unrelated to this work. No other potential conflicts of interest are reported by any of the authors. The authors received advice from the HPE customer support team when performing this study, but HPE did not have any role in study design, conducting the experiments, interpretation of the results or decision to submit for publication.
Figures

Comment in
-
When blockchain meets artificial intelligence: An application to cancer histopathology.Cell Rep Med. 2022 Jun 21;3(6):100666. doi: 10.1016/j.xcrm.2022.100666. Cell Rep Med. 2022. PMID: 35732149 Free PMC article.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
