

Revisiting the target-masker linguistic similarity hypothesis
- PMID: 35474415
- PMCID: PMC10701341
- DOI: 10.3758/s13414-022-02486-3
Revisiting the target-masker linguistic similarity hypothesis
Abstract
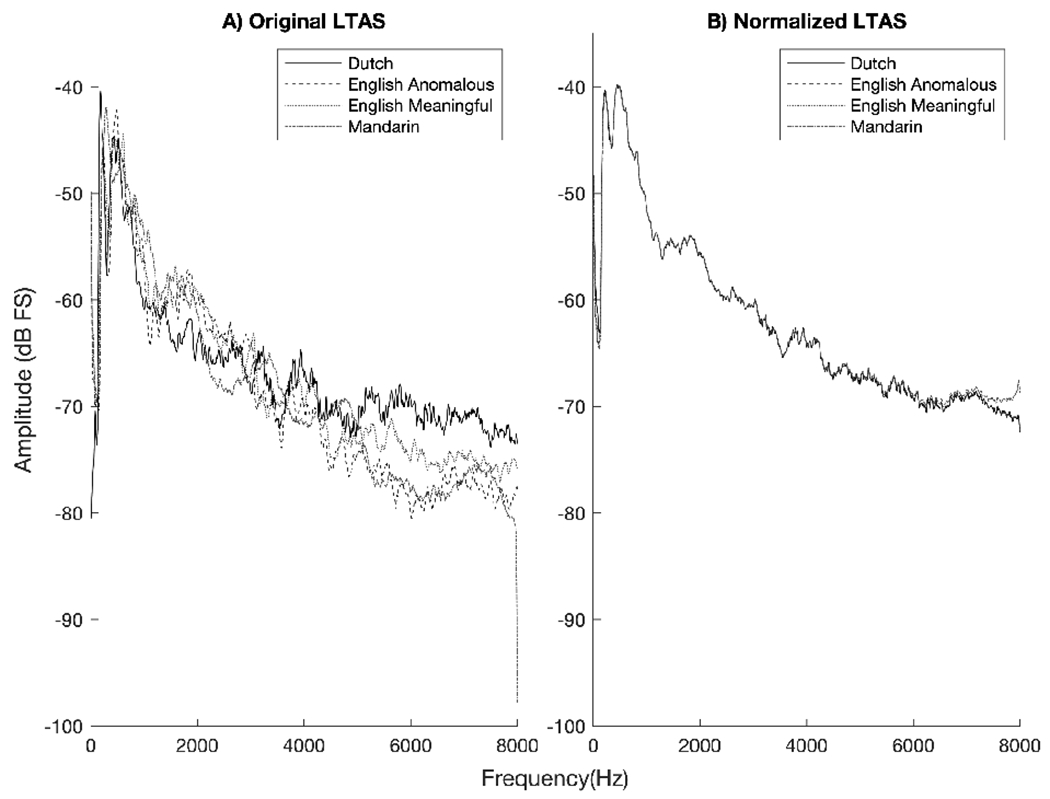
The linguistic similarity hypothesis states that it is more difficult to segregate target and masker speech when they are linguistically similar. For example, recognition of English target speech should be more impaired by the presence of Dutch masking speech than Mandarin masking speech because Dutch and English are more linguistically similar than Mandarin and English. Across four experiments, English target speech was consistently recognized more poorly when presented in English masking speech than in silence, speech-shaped noise, or an unintelligible masker (i.e., Dutch or Mandarin). However, we found no evidence for graded masking effects-Dutch did not impair performance more than Mandarin in any experiment, despite 650 participants being tested. This general pattern was consistent when using both a cross-modal paradigm (in which target speech was lipread and maskers were presented aurally; Experiments 1a and 1b) and an auditory-only paradigm (in which both the targets and maskers were presented aurally; Experiments 2a and 2b). These findings suggest that the linguistic similarity hypothesis should be refined to reflect the existing evidence: There is greater release from masking when the masker language differs from the target speech than when it is the same as the target speech. However, evidence that unintelligible maskers impair speech identification to a greater extent when they are more linguistically similar to the target language remains elusive.
Keywords: Cross-modal masking; Linguistic similarity hypothesis; Masking; Speech identification.
© 2022. The Psychonomic Society, Inc.
Figures




References
-
- Agus TR, Akeroyd MA, Gatehouse S, & Warden D (2009). Informational masking in young and elderly listeners for speech masked by simultaneous speech and noise. The Journal of the Acoustical Society of America, 126(4), 1926–1940. - PubMed
-
- Bates D, Maechler M, Bolker B, Walker S, Christensen R, Singmann H, Dai B, Scheipl F, Grothendieck G, & Green P (2014). Package “lme4” (Version 1.1-15). R foundation for statistical computing, Vienna, 12. https://github.com/lme4/lme4/
-
- Bench J, Kowal A, & Bamford J (1979). The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children. British Journal of Audiology, 13(3), 108–112. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
