

Population heterogeneity in clinical cohorts affects the predictive accuracy of brain imaging
- PMID: 35486643
- PMCID: PMC9094526
- DOI: 10.1371/journal.pbio.3001627
Population heterogeneity in clinical cohorts affects the predictive accuracy of brain imaging
Abstract
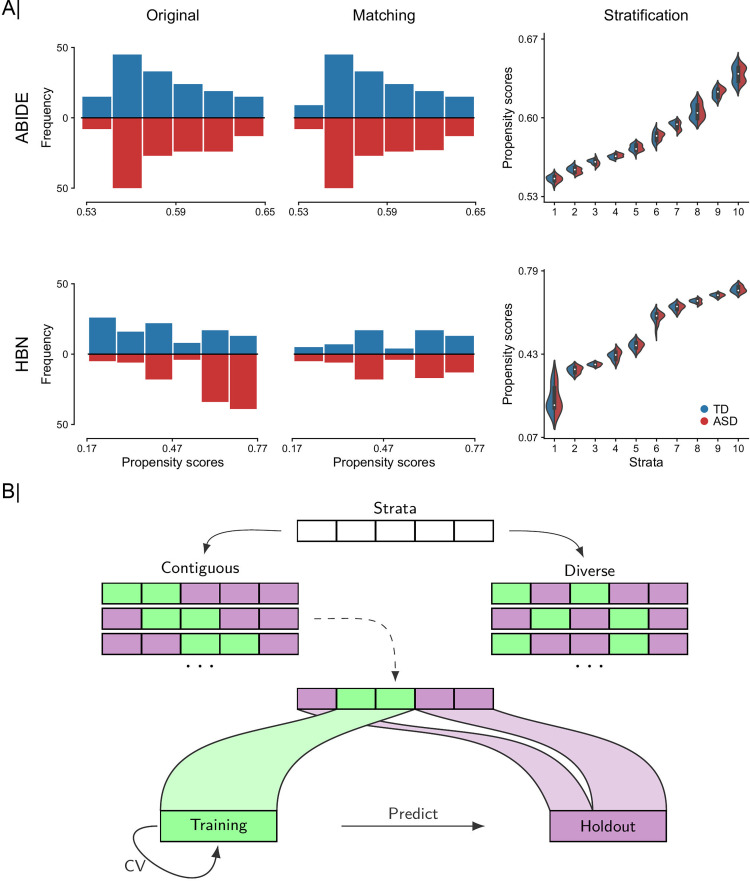
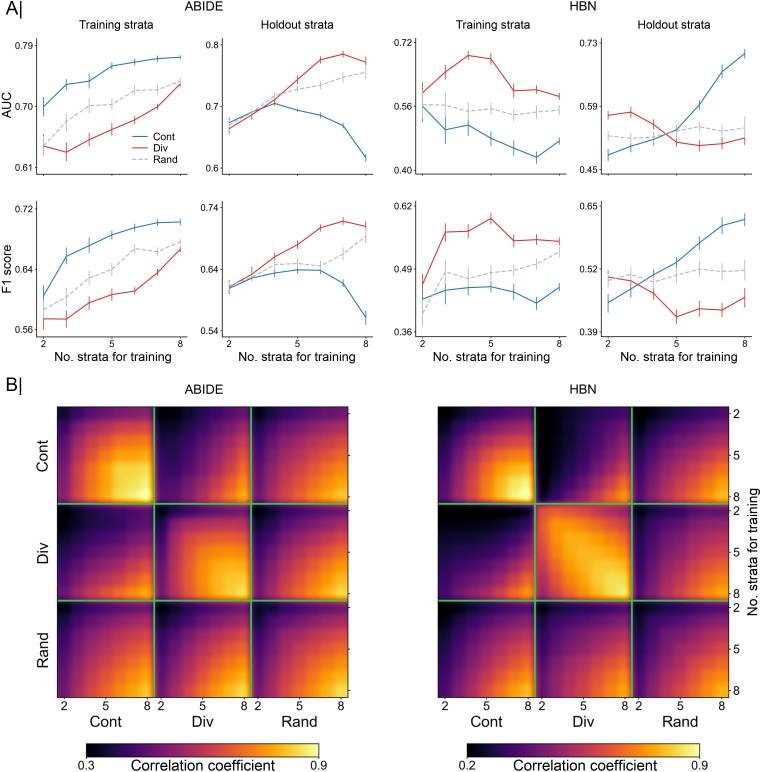
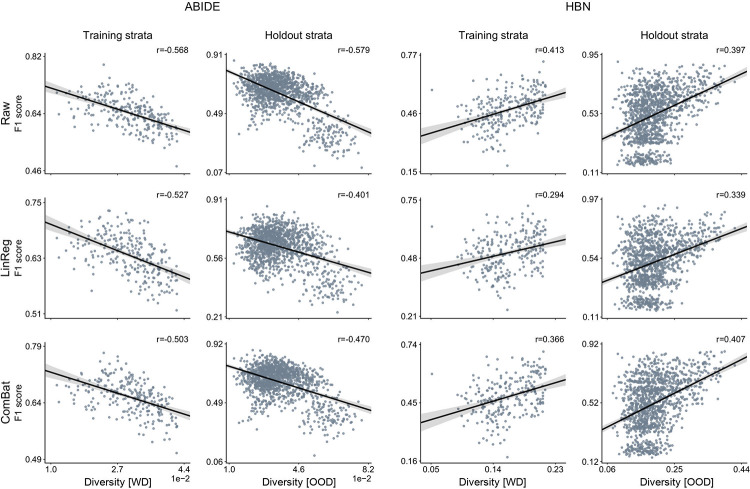
Brain imaging research enjoys increasing adoption of supervised machine learning for single-participant disease classification. Yet, the success of these algorithms likely depends on population diversity, including demographic differences and other factors that may be outside of primary scientific interest. Here, we capitalize on propensity scores as a composite confound index to quantify diversity due to major sources of population variation. We delineate the impact of population heterogeneity on the predictive accuracy and pattern stability in 2 separate clinical cohorts: the Autism Brain Imaging Data Exchange (ABIDE, n = 297) and the Healthy Brain Network (HBN, n = 551). Across various analysis scenarios, our results uncover the extent to which cross-validated prediction performances are interlocked with diversity. The instability of extracted brain patterns attributable to diversity is located preferentially in regions part of the default mode network. Collectively, our findings highlight the limitations of prevailing deconfounding practices in mitigating the full consequences of population diversity.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures




References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
