

phastSim: Efficient simulation of sequence evolution for pandemic-scale datasets
- PMID: 35486906
- PMCID: PMC9094560
- DOI: 10.1371/journal.pcbi.1010056
phastSim: Efficient simulation of sequence evolution for pandemic-scale datasets
Abstract
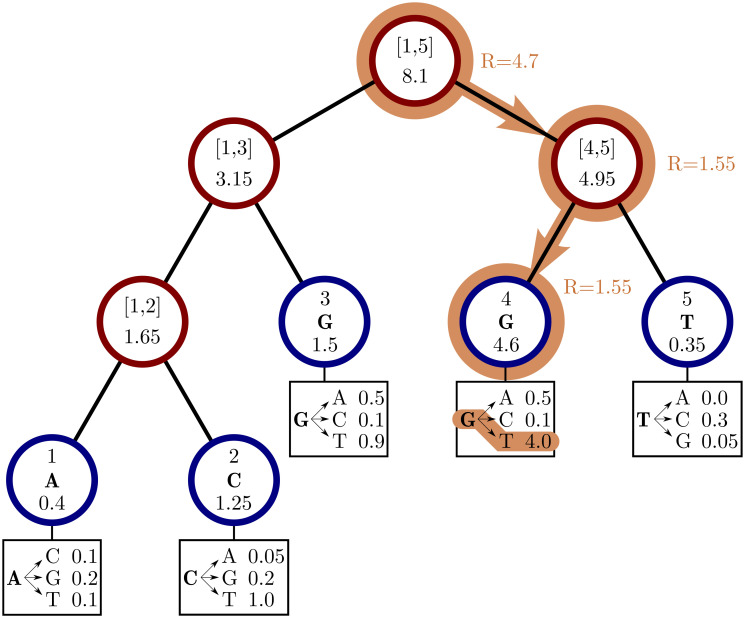
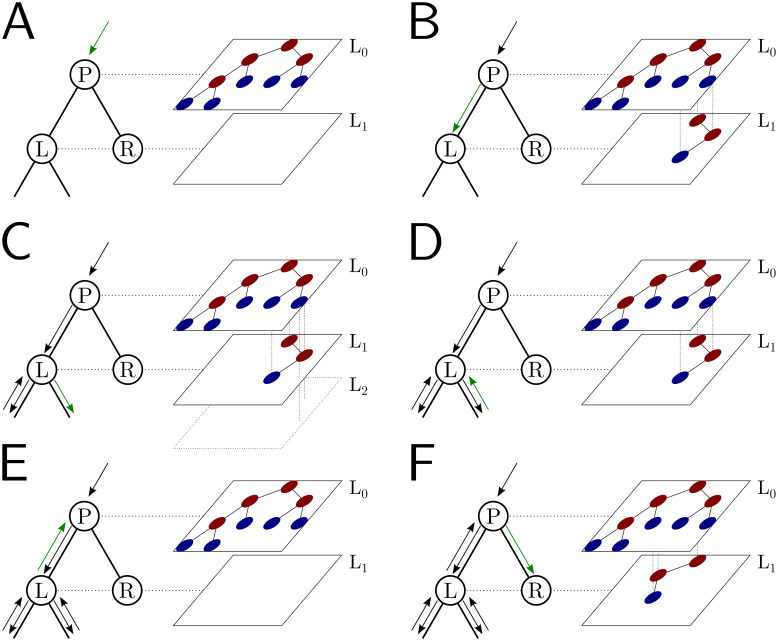
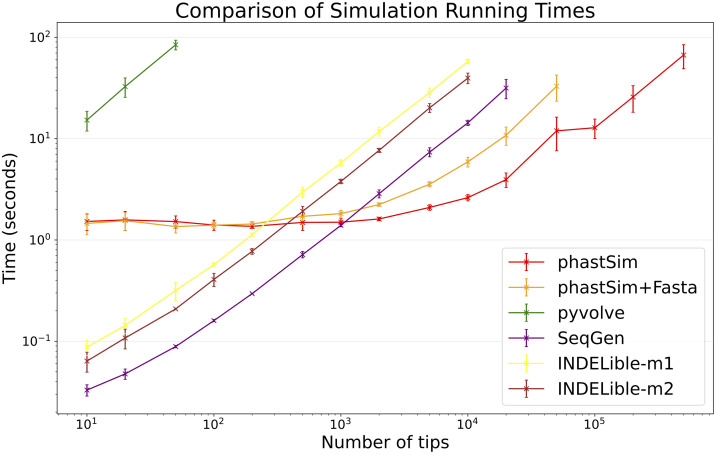
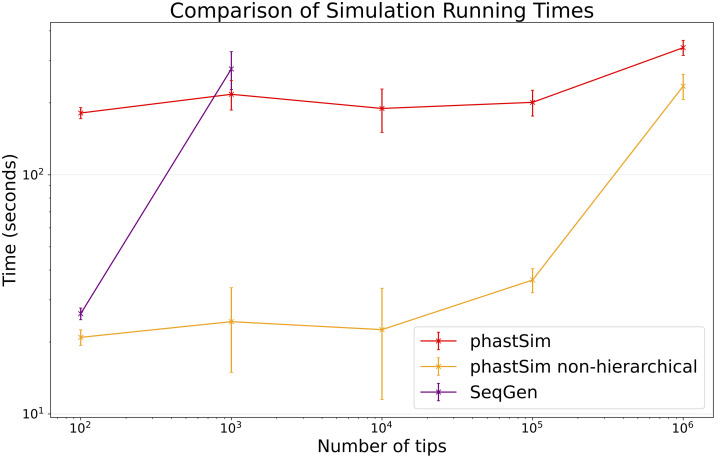
Sequence simulators are fundamental tools in bioinformatics, as they allow us to test data processing and inference tools, and are an essential component of some inference methods. The ongoing surge in available sequence data is however testing the limits of our bioinformatics software. One example is the large number of SARS-CoV-2 genomes available, which are beyond the processing power of many methods, and simulating such large datasets is also proving difficult. Here, we present a new algorithm and software for efficiently simulating sequence evolution along extremely large trees (e.g. > 100, 000 tips) when the branches of the tree are short, as is typical in genomic epidemiology. Our algorithm is based on the Gillespie approach, and it implements an efficient multi-layered search tree structure that provides high computational efficiency by taking advantage of the fact that only a small proportion of the genome is likely to mutate at each branch of the considered phylogeny. Our open source software allows easy integration with other Python packages as well as a variety of evolutionary models, including indel models and new hypermutability models that we developed to more realistically represent SARS-CoV-2 genome evolution.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
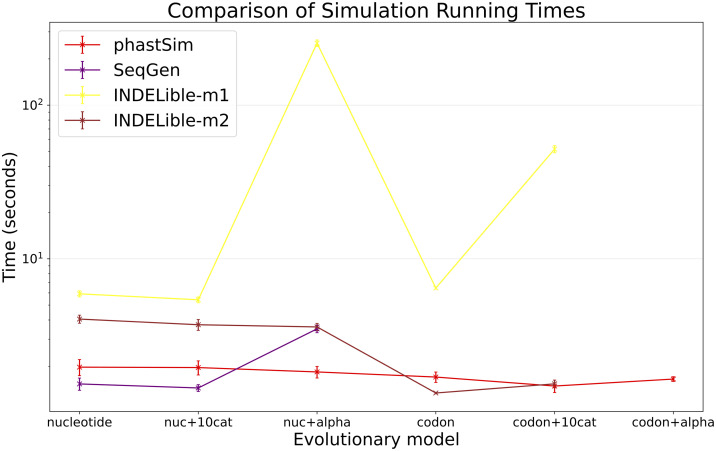
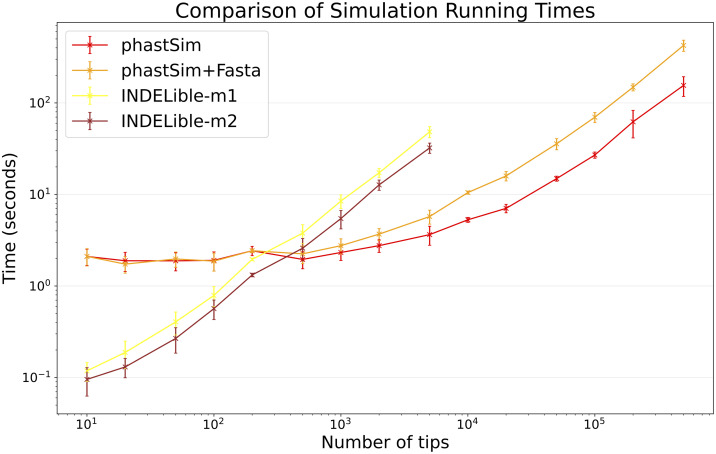
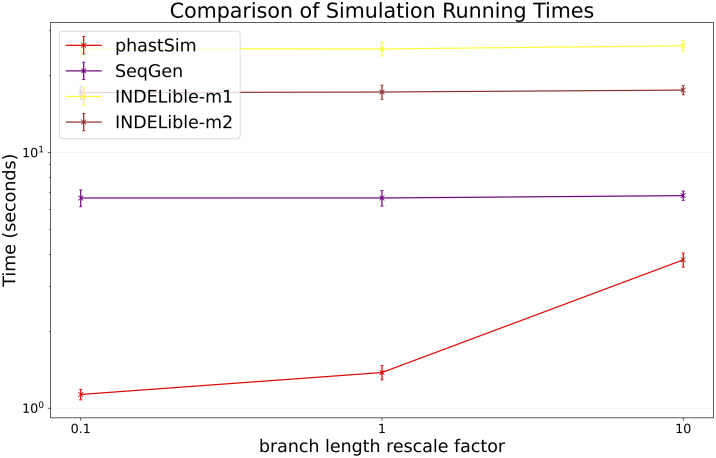
Update of
-
phastSim: efficient simulation of sequence evolution for pandemic-scale datasets.bioRxiv [Preprint]. 2021 Sep 23:2021.03.15.435416. doi: 10.1101/2021.03.15.435416. bioRxiv. 2021. Update in: PLoS Comput Biol. 2022 Apr 29;18(4):e1010056. doi: 10.1371/journal.pcbi.1010056. PMID: 33758852 Free PMC article. Updated. Preprint.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
