

A comparison of strategies for generating artificial replicates in RNA-seq experiments
- PMID: 35505053
- PMCID: PMC9065086
- DOI: 10.1038/s41598-022-11302-9
A comparison of strategies for generating artificial replicates in RNA-seq experiments
Abstract
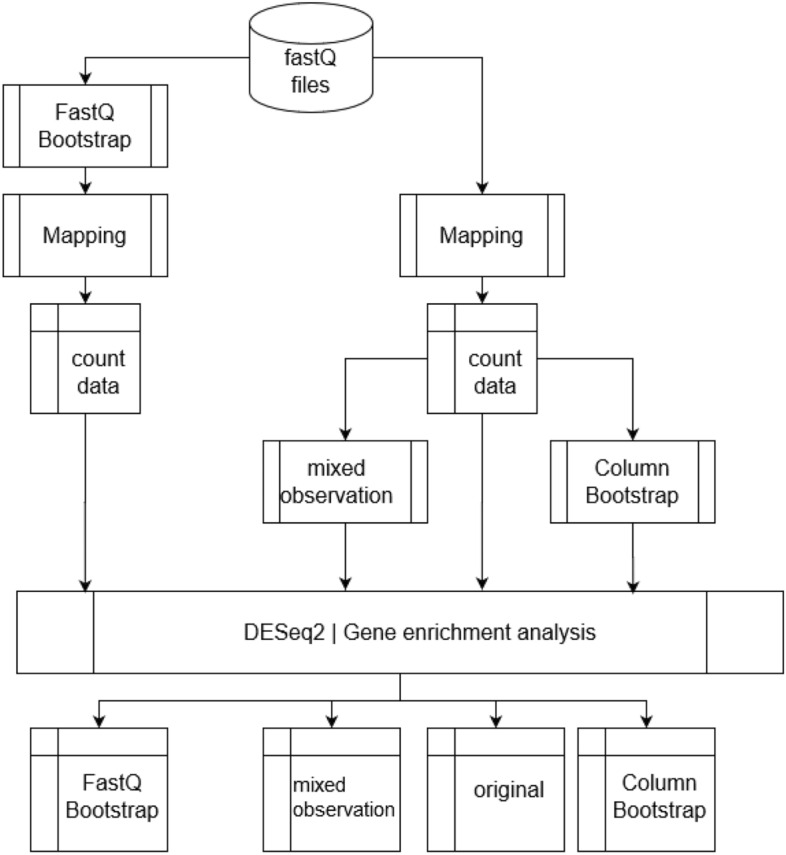
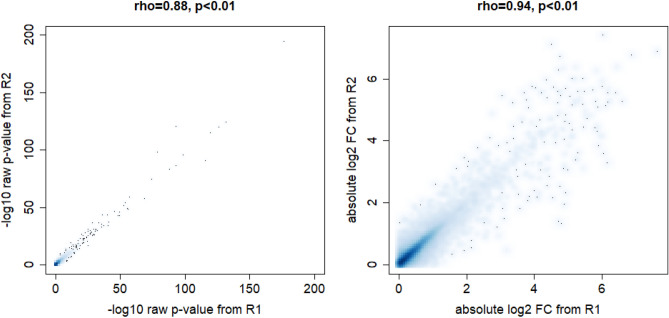
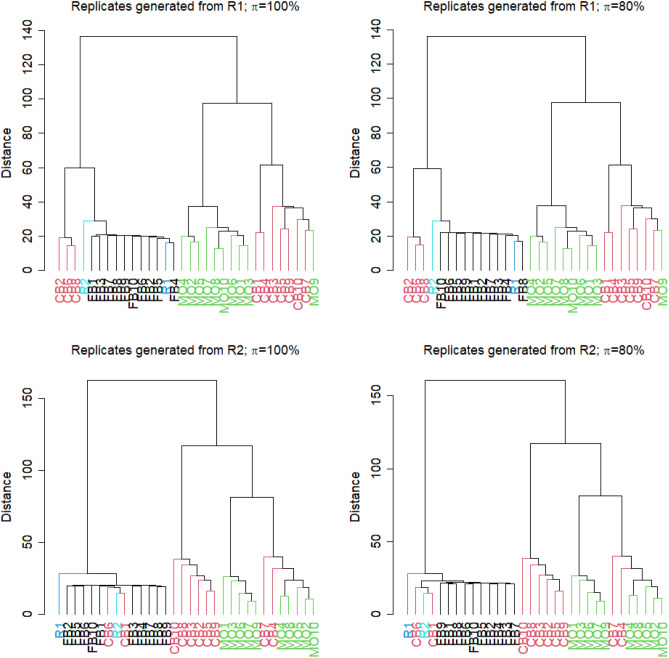
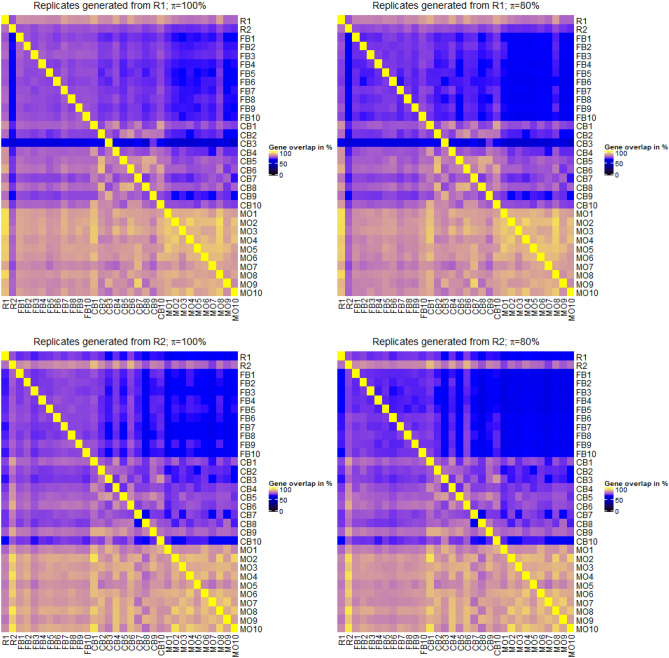
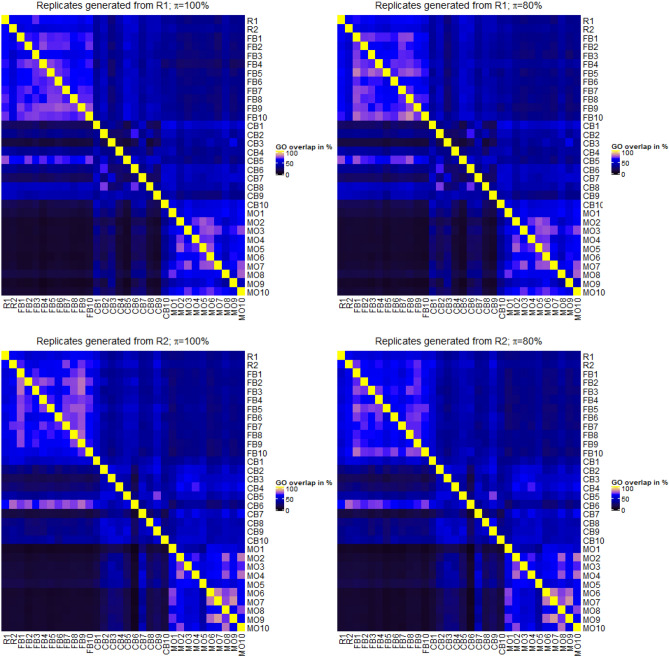
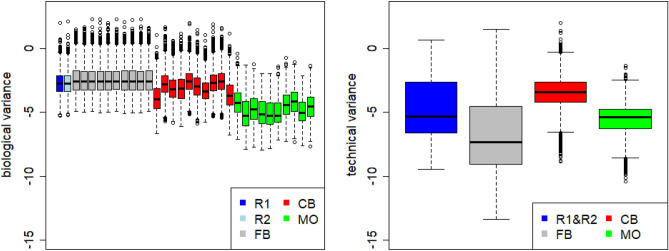
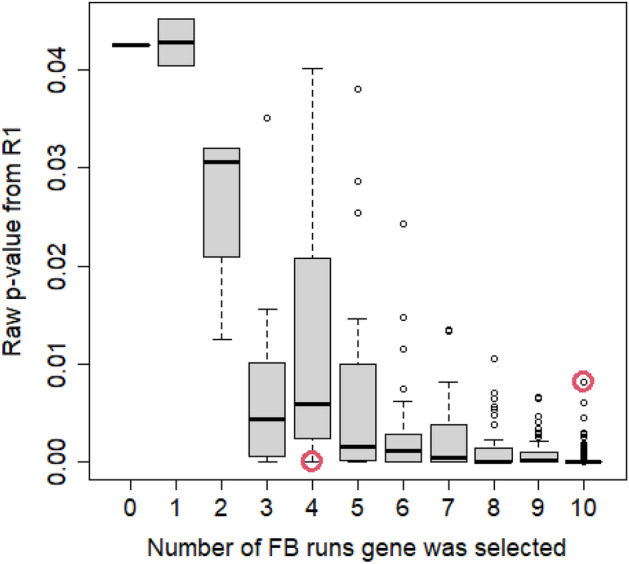
Due to the overall high costs, technical replicates are usually omitted in RNA-seq experiments, but several methods exist to generate them artificially. Bootstrapping reads from FASTQ-files has recently been used in the context of other NGS analyses and can be used to generate artificial technical replicates. Bootstrapping samples from the columns of the expression matrix has already been used for DNA microarray data and generates a new artificial replicate of the whole experiment. Mixing data of individual samples has been used for data augmentation in machine learning. The aim of this comparison is to evaluate which of these strategies are best suited to study the reproducibility of differential expression and gene-set enrichment analysis in an RNA-seq experiment. To study the approaches under controlled conditions, we performed a new RNA-seq experiment on gene expression changes upon virus infection compared to untreated control samples. In order to compare the approaches for artificial replicates, each of the samples was sequenced twice, i.e. as true technical replicates, and differential expression analysis and GO term enrichment analysis was conducted separately for the two resulting data sets. Although we observed a high correlation between the results from the two replicates, there are still many genes and GO terms that would be selected from one replicate but not from the other. Cluster analyses showed that artificial replicates generated by bootstrapping reads produce it p values and fold changes that are close to those obtained from the true data sets. Results generated from artificial replicates with the approaches of column bootstrap or mixing observations were less similar to the results from the true replicates. Furthermore, the overlap of results among replicates generated by column bootstrap or mixing observations was much stronger than among the true replicates. Artificial technical replicates generated by bootstrapping sequencing reads from FASTQ-files are better suited to study the reproducibility of results from differential expression and GO term enrichment analysis in RNA-seq experiments than column bootstrap or mixing observations. However, FASTQ-bootstrapping is computationally more expensive than the other two approaches. The FASTQ-bootstrapping may be applicable to other applications of high-throughput sequencing.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
