

Improving polygenic prediction in ancestrally diverse populations
- PMID: 35513724
- PMCID: PMC9117455
- DOI: 10.1038/s41588-022-01054-7
Improving polygenic prediction in ancestrally diverse populations
Erratum in
-
Author Correction: Improving polygenic prediction in ancestrally diverse populations.Nat Genet. 2022 Aug;54(8):1259. doi: 10.1038/s41588-022-01144-6. Nat Genet. 2022. PMID: 35789324 No abstract available.
Abstract
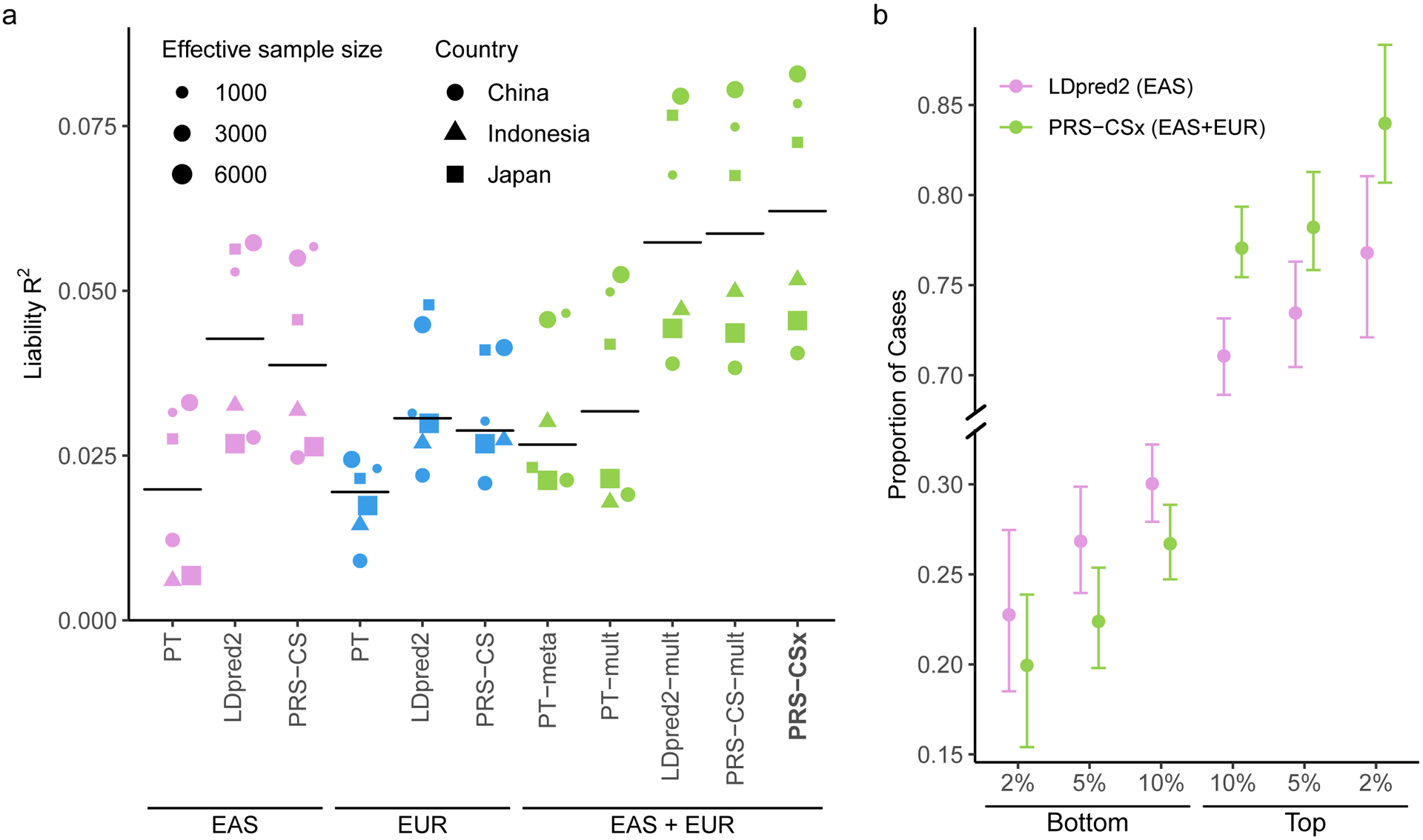
Polygenic risk scores (PRS) have attenuated cross-population predictive performance. As existing genome-wide association studies (GWAS) have been conducted predominantly in individuals of European descent, the limited transferability of PRS reduces their clinical value in non-European populations, and may exacerbate healthcare disparities. Recent efforts to level ancestry imbalance in genomic research have expanded the scale of non-European GWAS, although most remain underpowered. Here, we present a new PRS construction method, PRS-CSx, which improves cross-population polygenic prediction by integrating GWAS summary statistics from multiple populations. PRS-CSx couples genetic effects across populations via a shared continuous shrinkage (CS) prior, enabling more accurate effect size estimation by sharing information between summary statistics and leveraging linkage disequilibrium diversity across discovery samples, while inheriting computational efficiency and robustness from PRS-CS. We show that PRS-CSx outperforms alternative methods across traits with a wide range of genetic architectures, cross-population genetic overlaps and discovery GWAS sample sizes in simulations, and improves the prediction of quantitative traits and schizophrenia risk in non-European populations.
© 2022. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
COMPETING INTERESTS
C.Y.C. is an employee of Biogen. The other authors declare no competing interests.
Figures
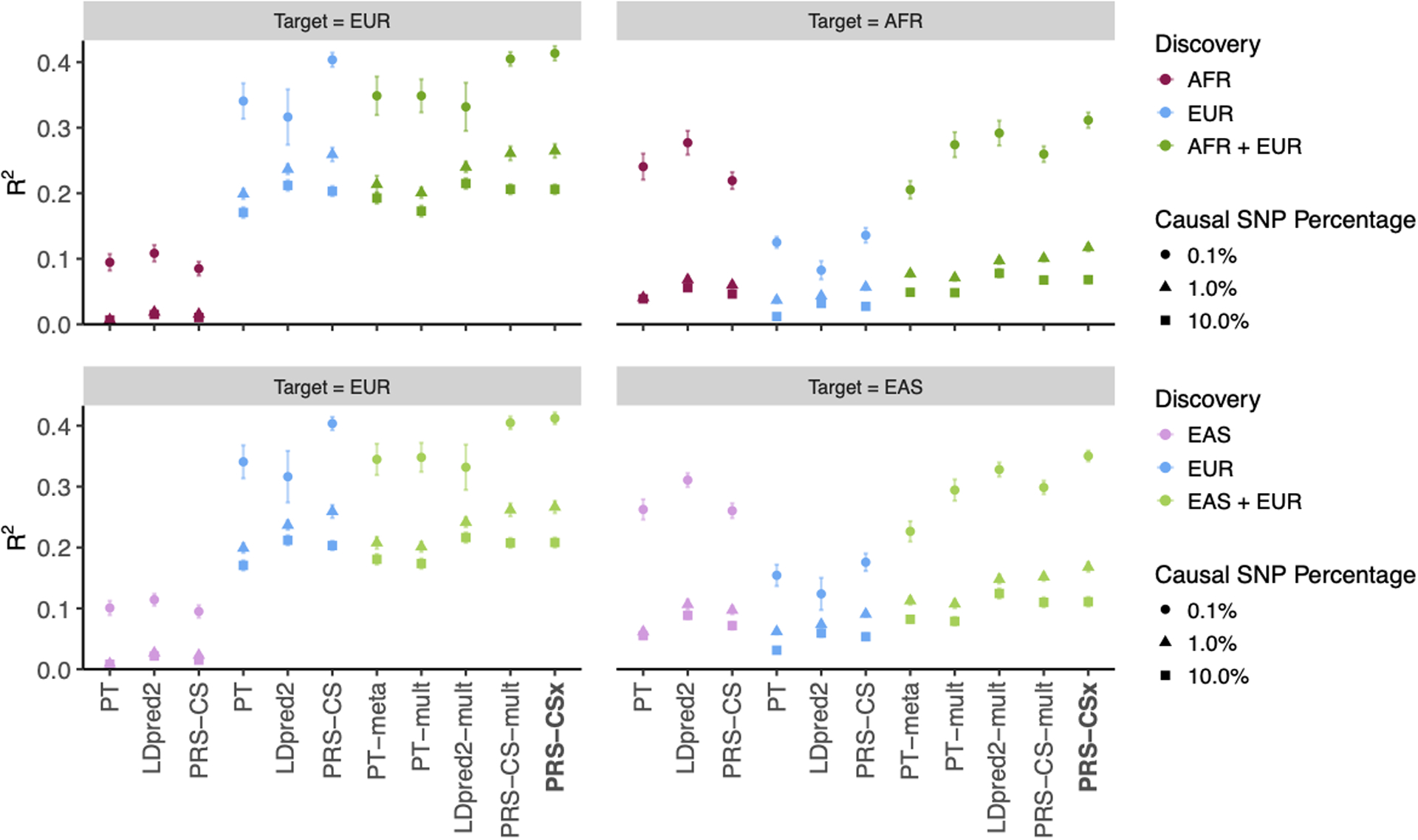
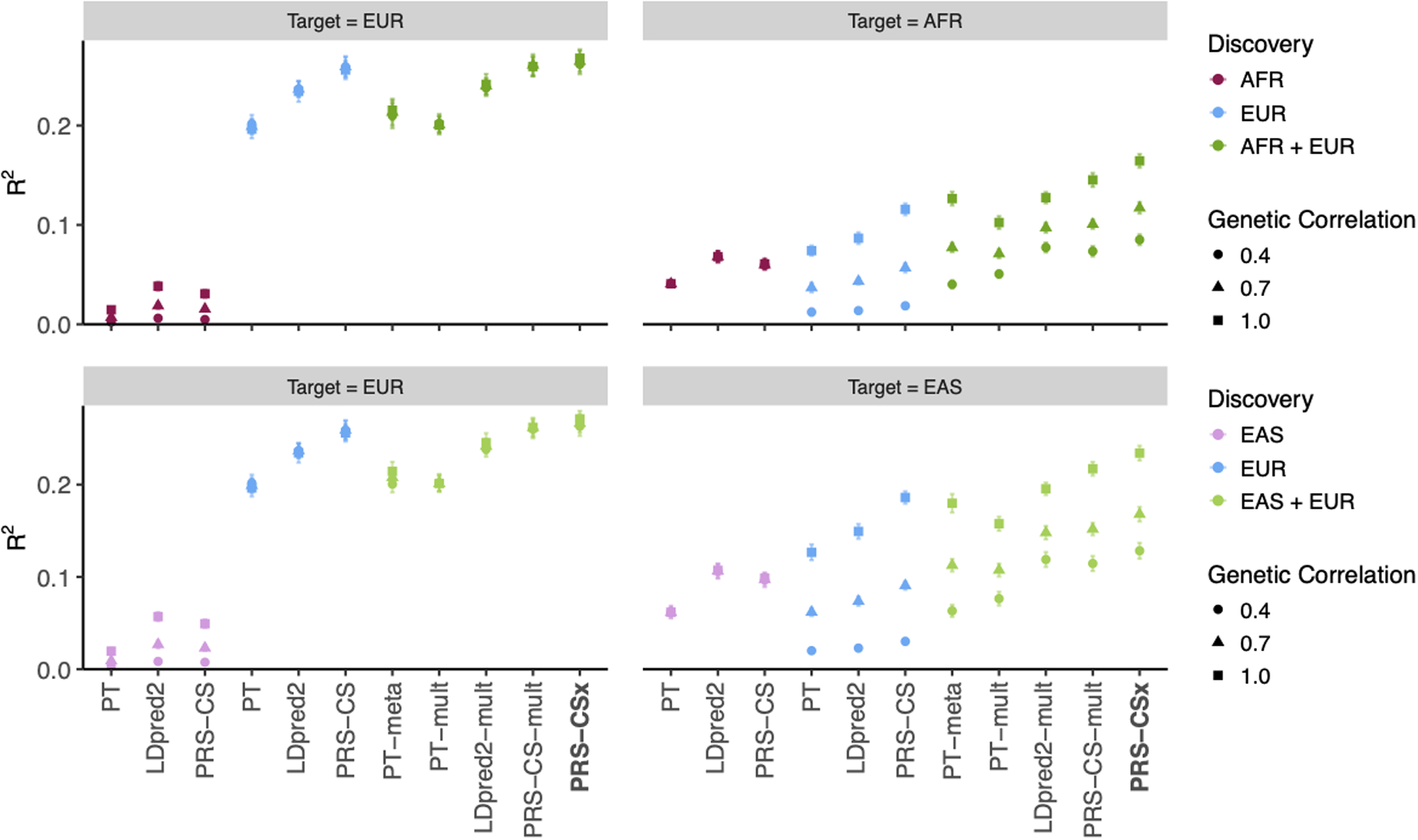
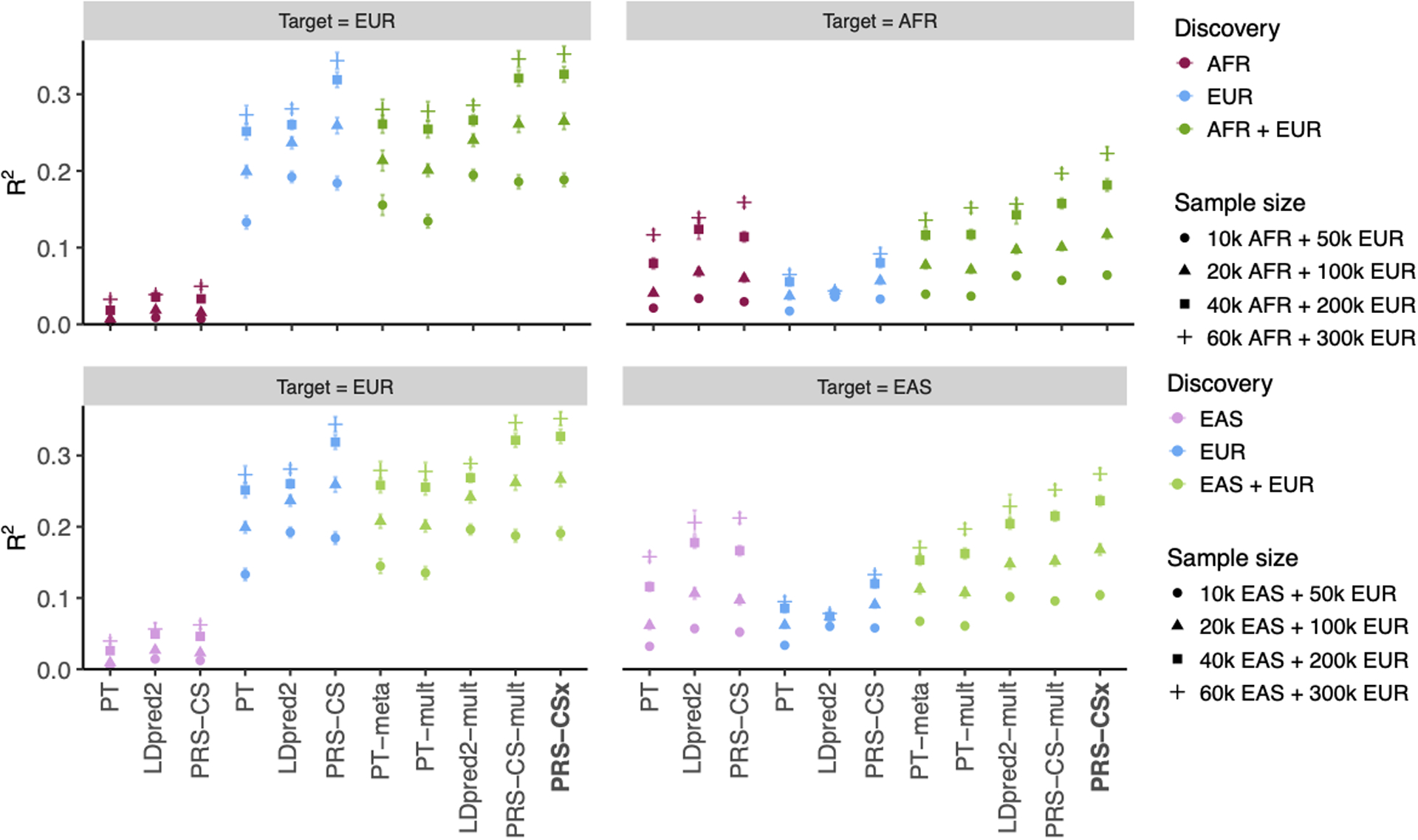
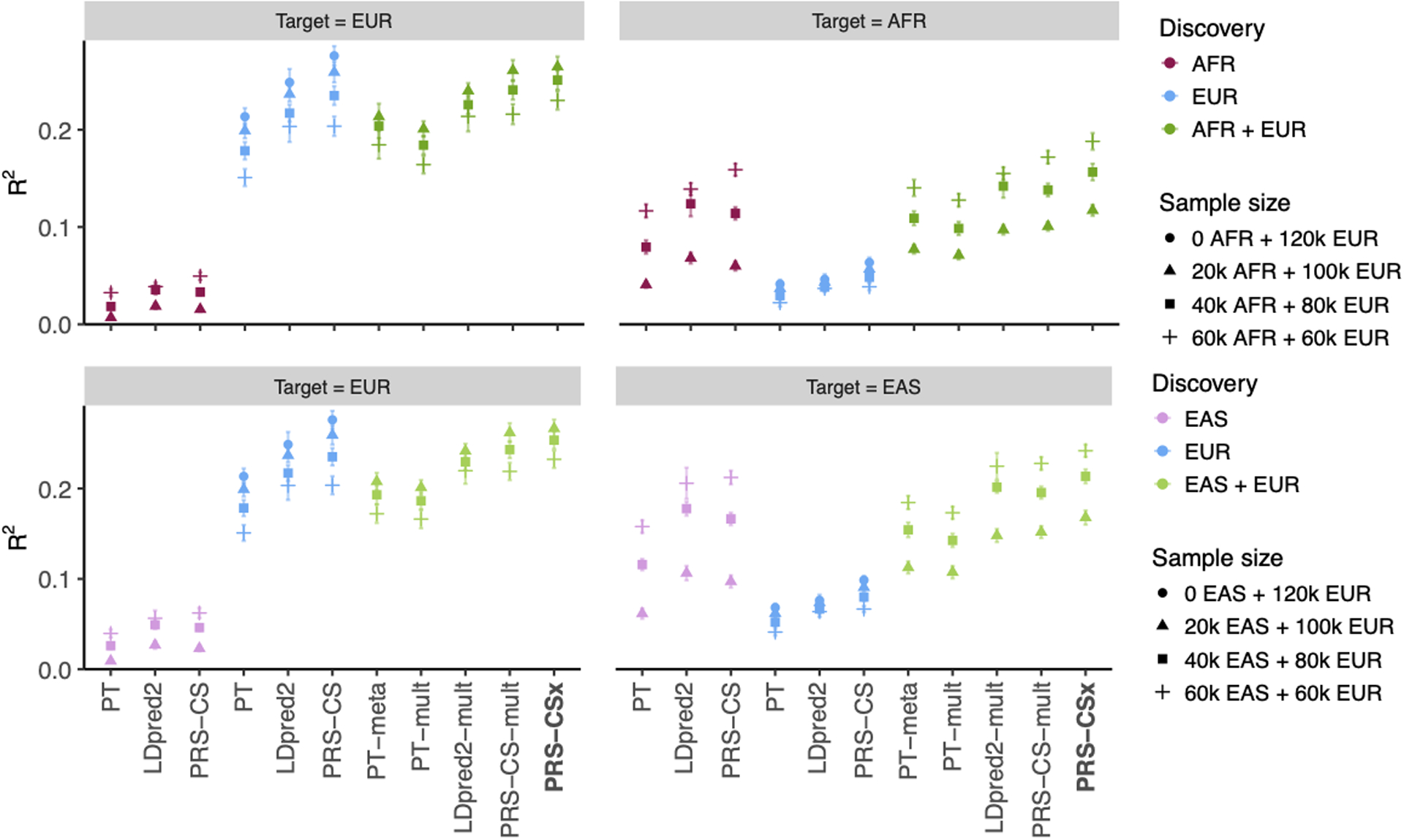
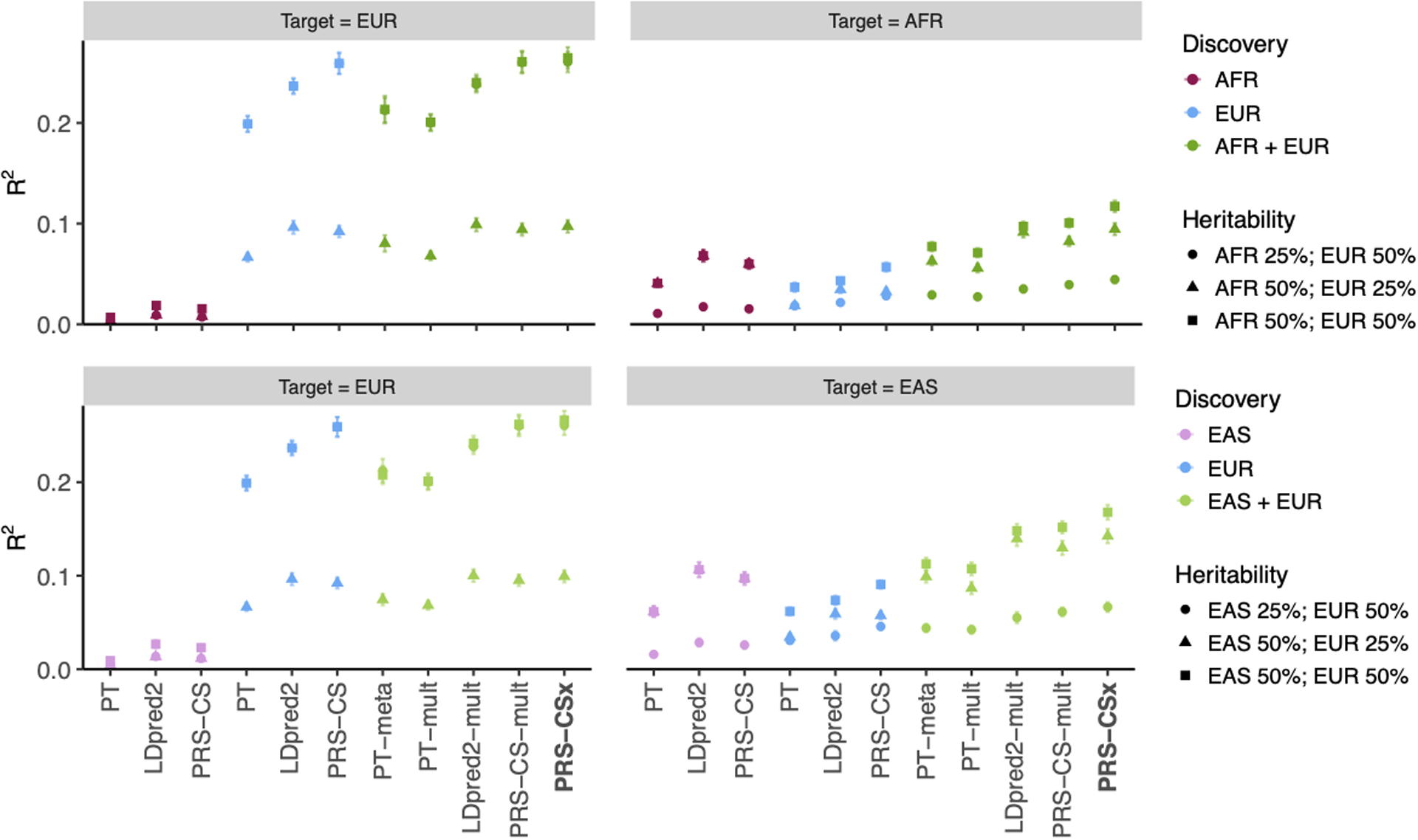
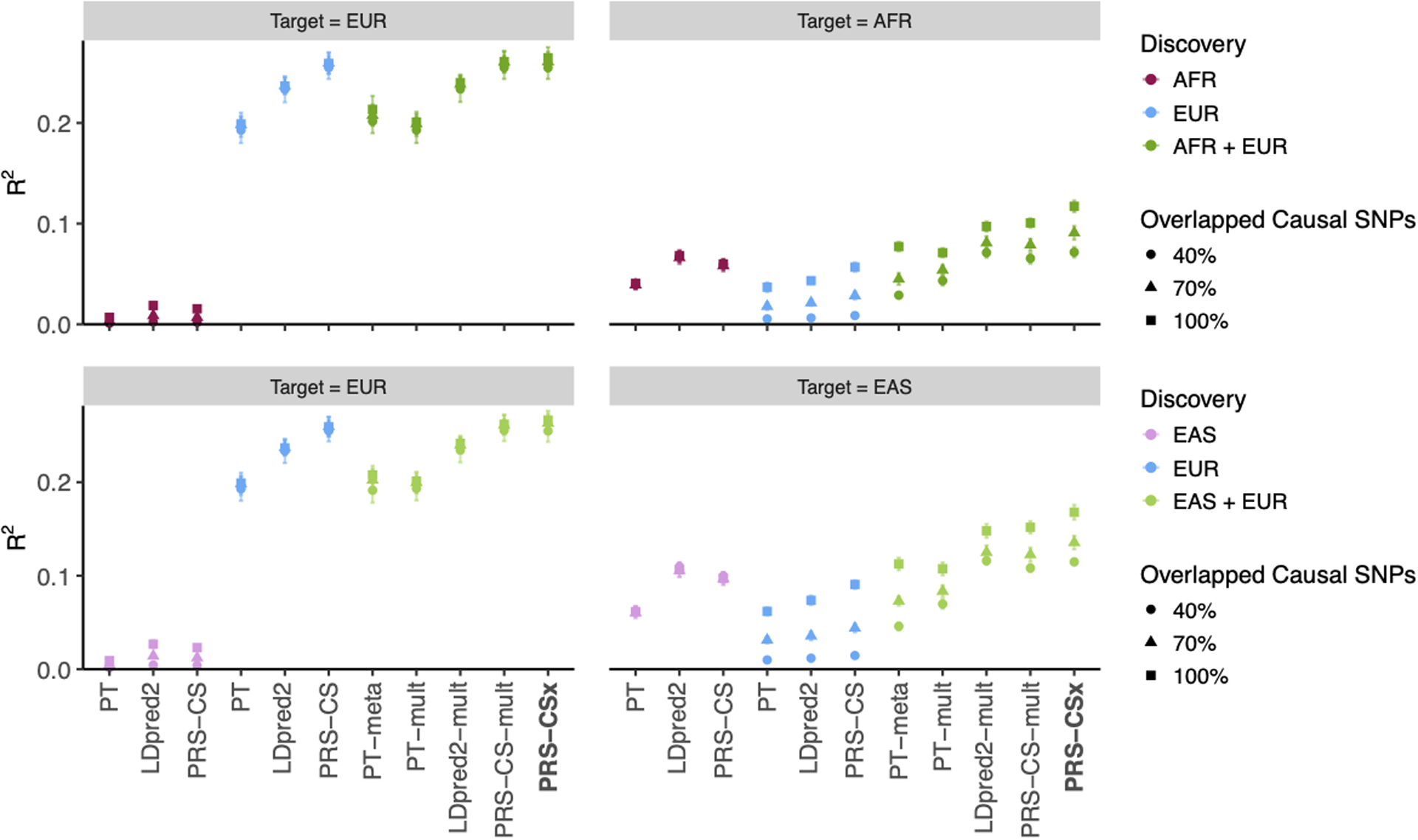
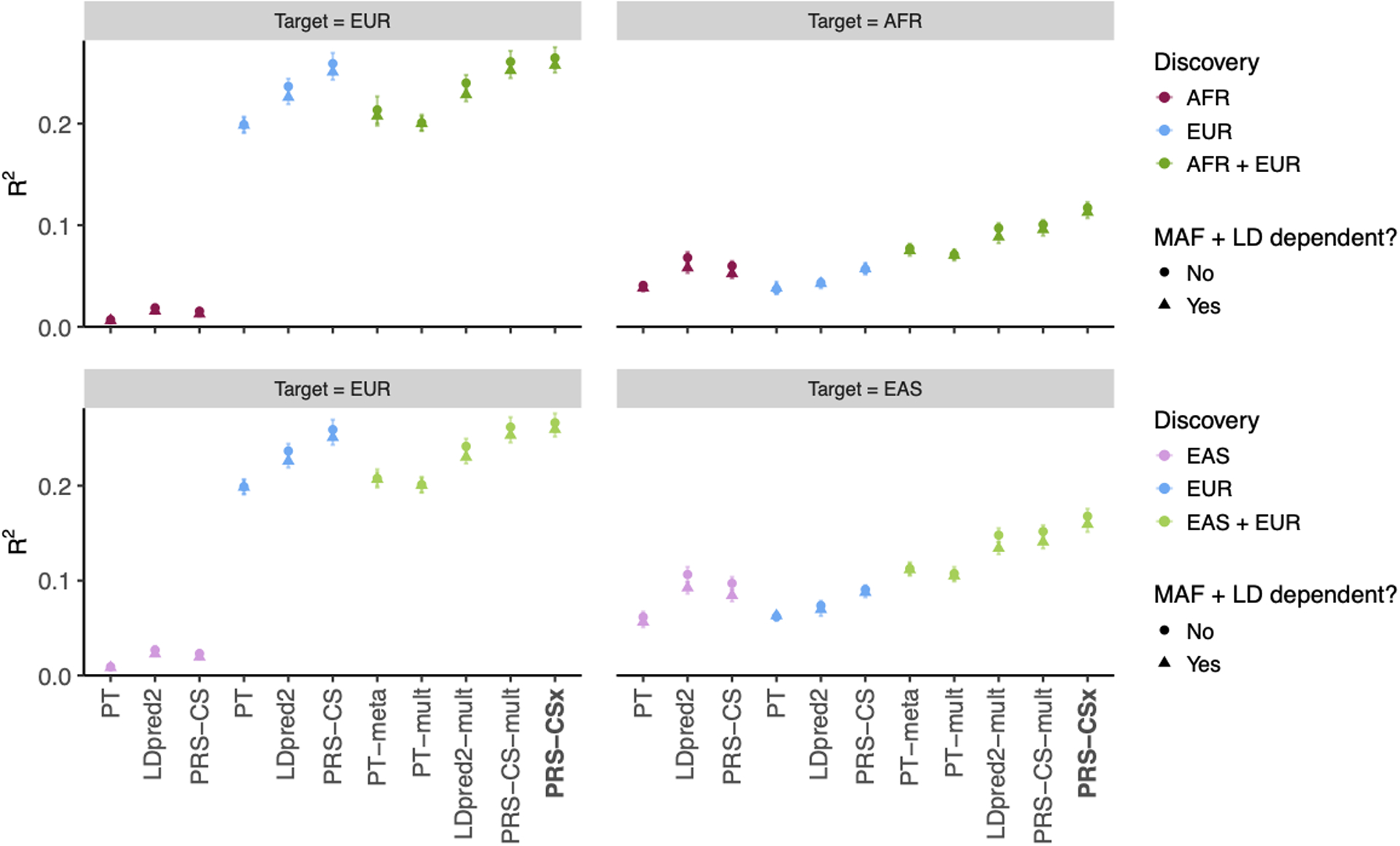
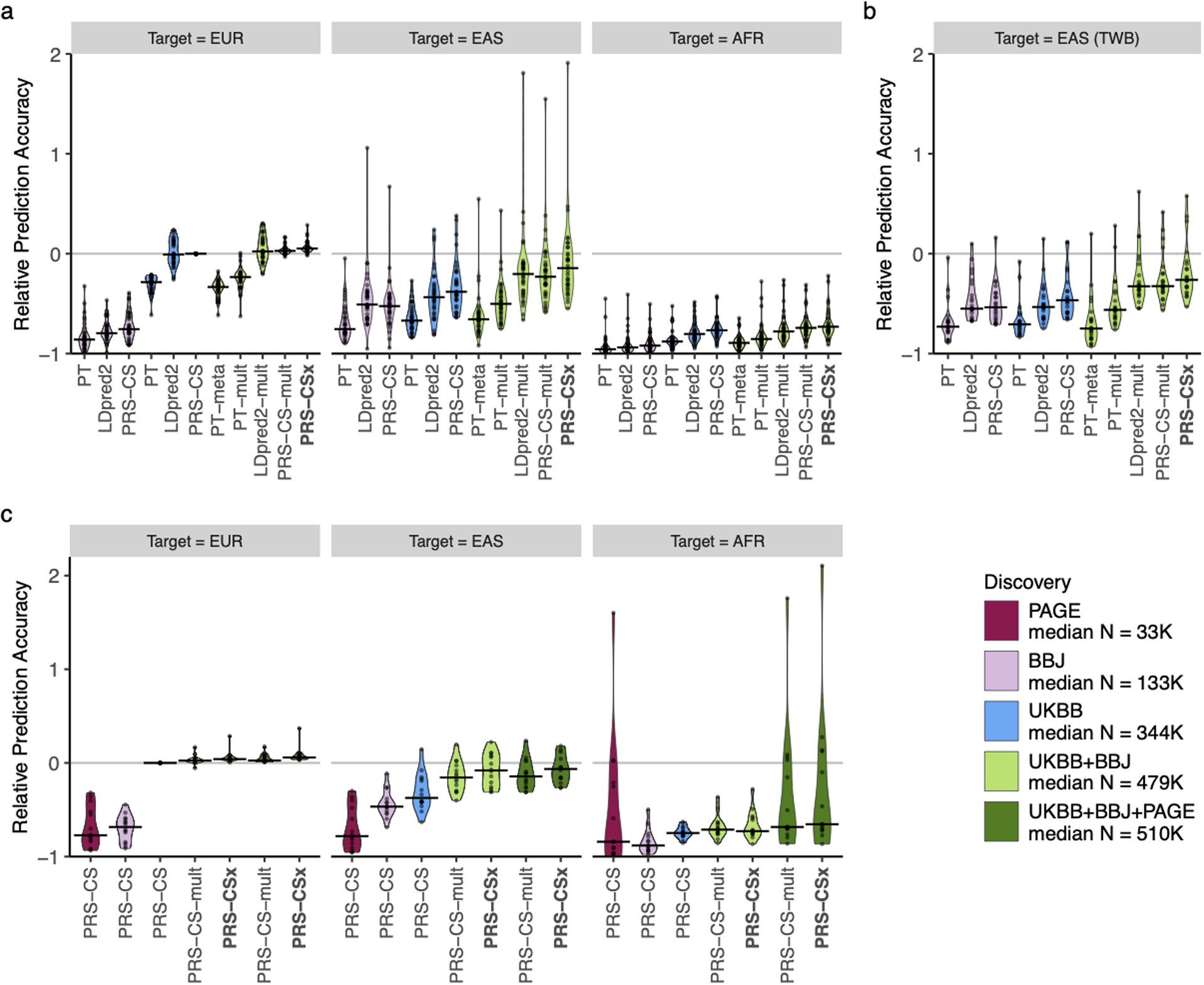
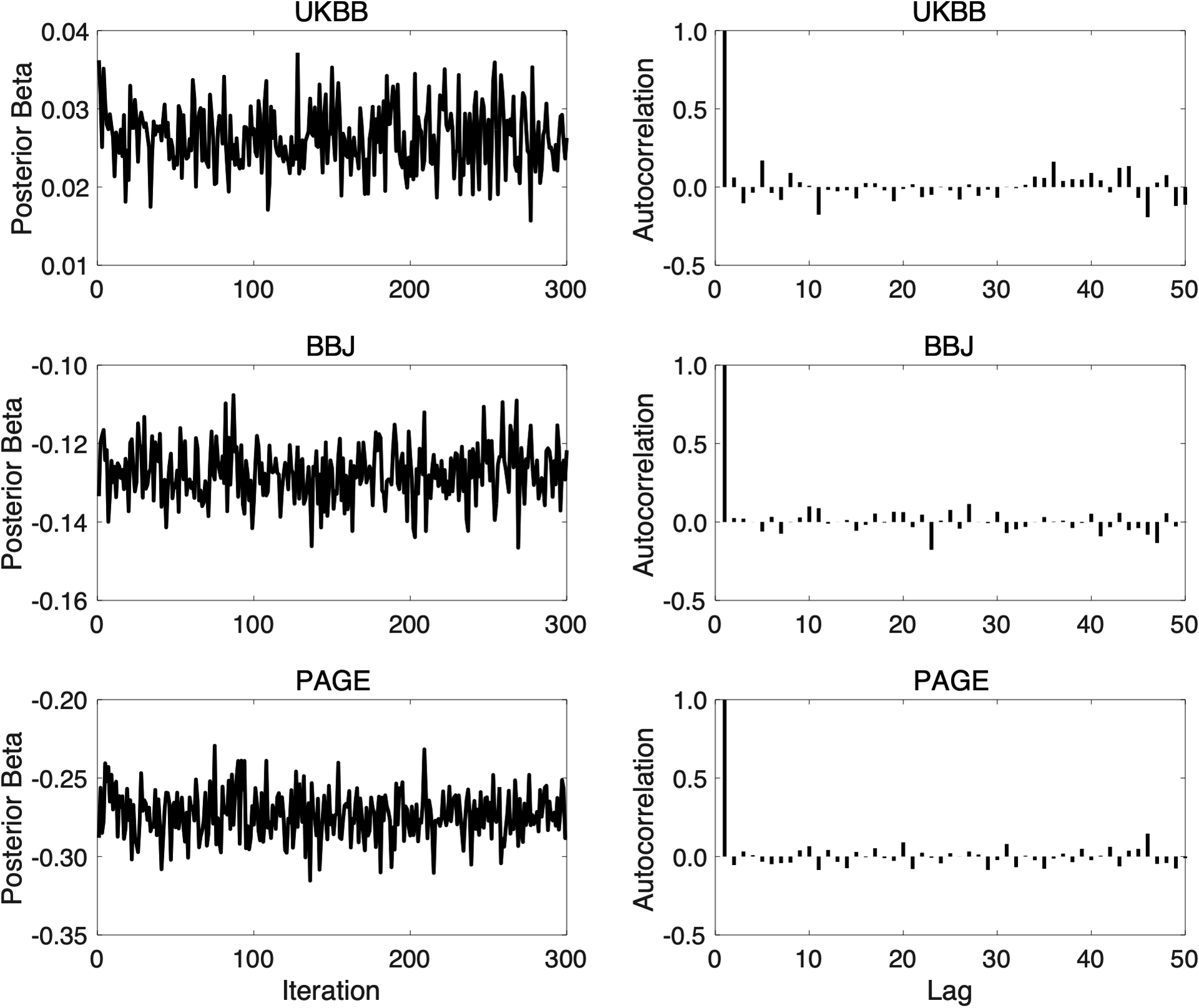
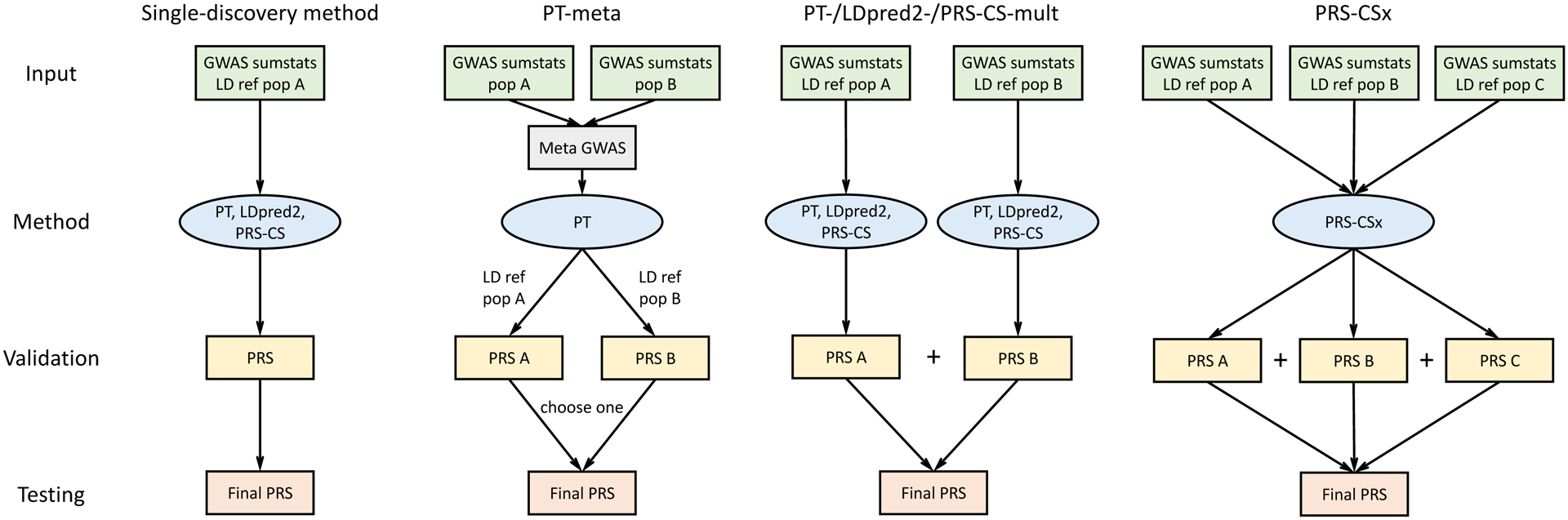
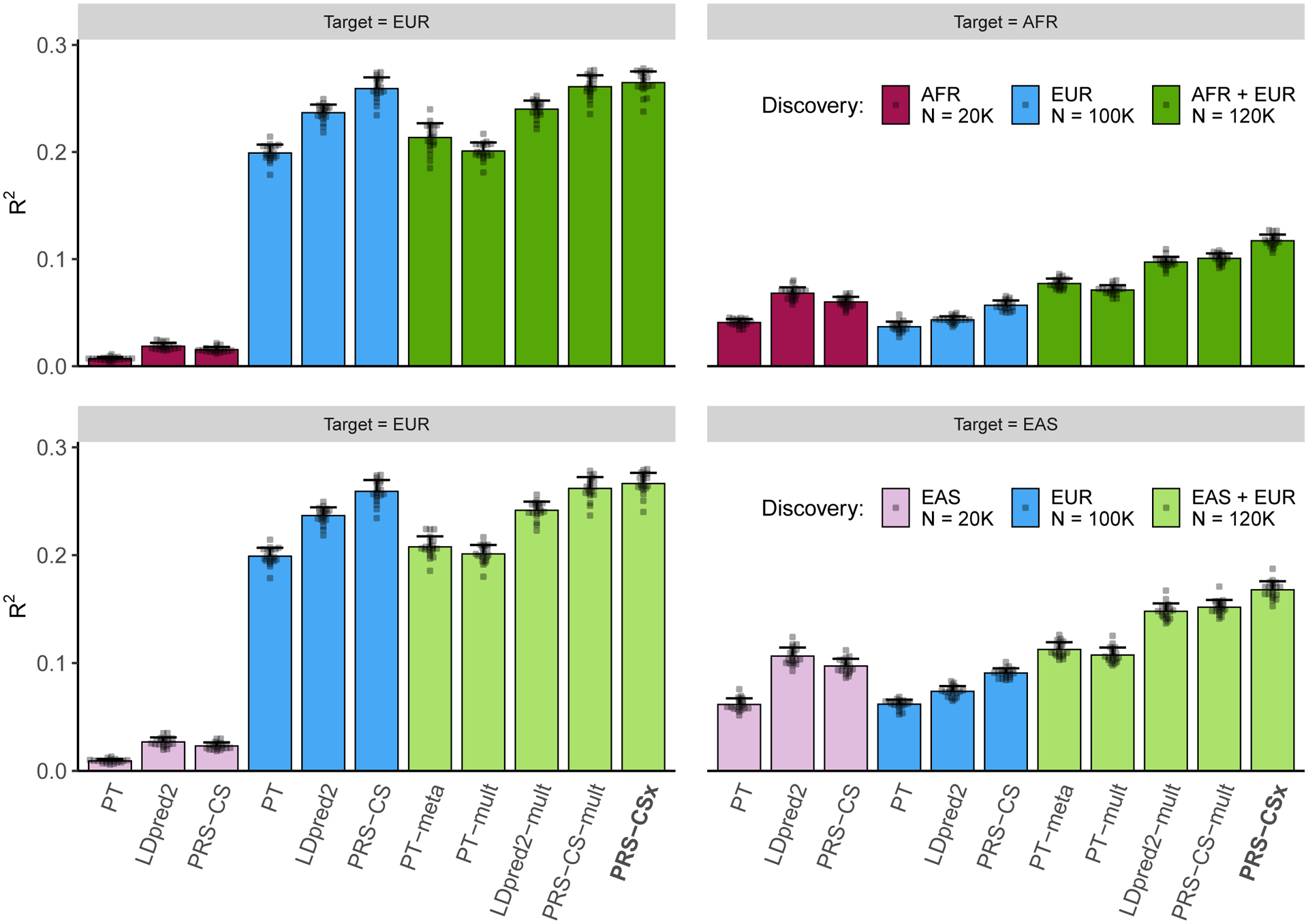
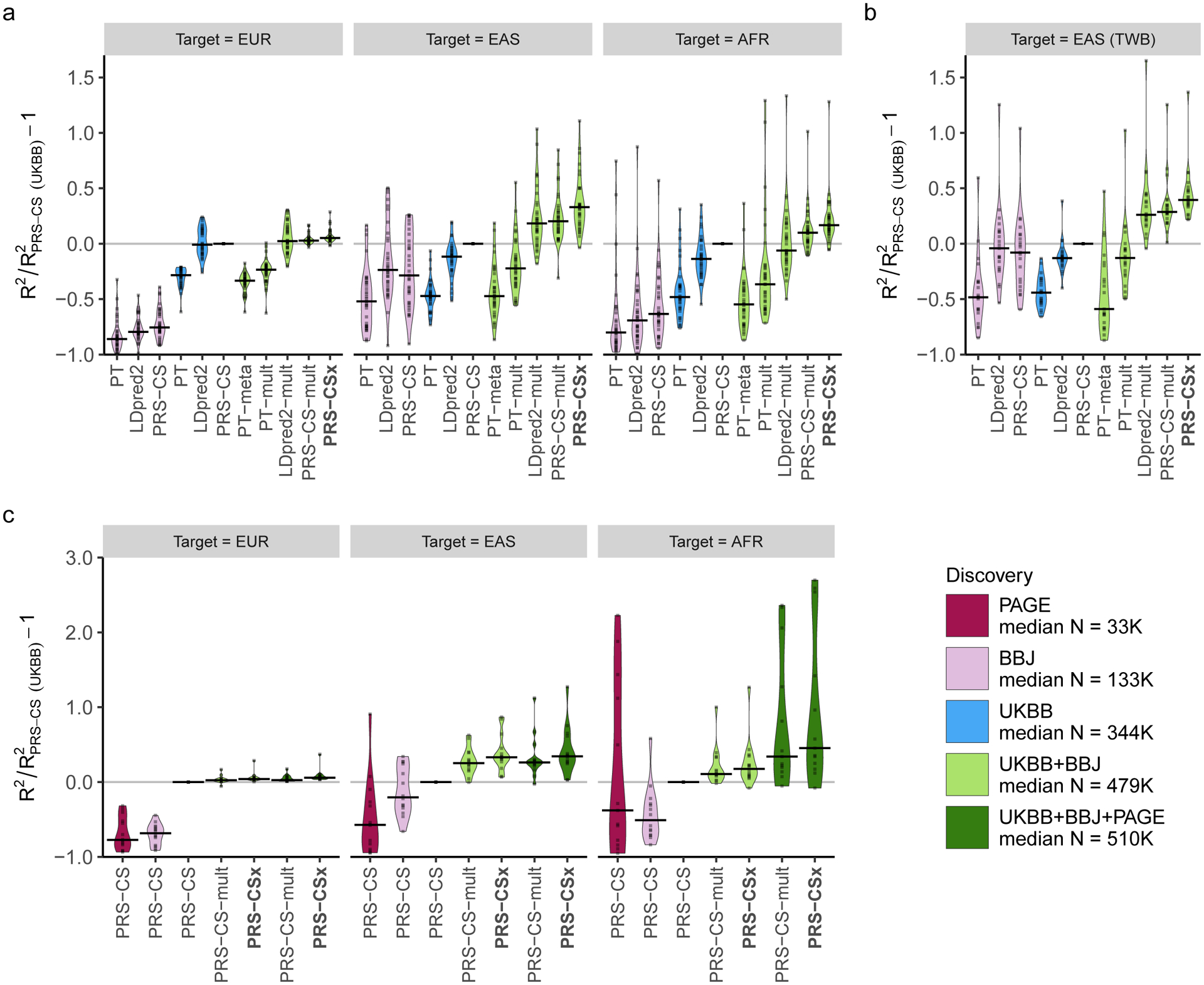
References
-
- Torkamani A, Wineinger NE & Topol EJ The personal and clinical utility of polygenic risk scores. Nat. Rev. Genet 19, 581–590 (2018). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
