

SemClinBr - a multi-institutional and multi-specialty semantically annotated corpus for Portuguese clinical NLP tasks
- PMID: 35527259
- PMCID: PMC9080187
- DOI: 10.1186/s13326-022-00269-1
SemClinBr - a multi-institutional and multi-specialty semantically annotated corpus for Portuguese clinical NLP tasks
Abstract
Background: The high volume of research focusing on extracting patient information from electronic health records (EHRs) has led to an increase in the demand for annotated corpora, which are a precious resource for both the development and evaluation of natural language processing (NLP) algorithms. The absence of a multipurpose clinical corpus outside the scope of the English language, especially in Brazilian Portuguese, is glaring and severely impacts scientific progress in the biomedical NLP field.
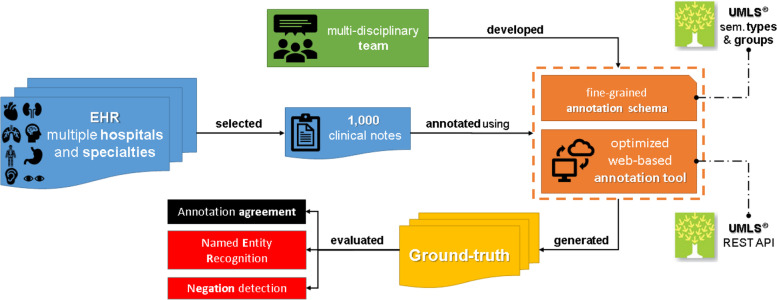
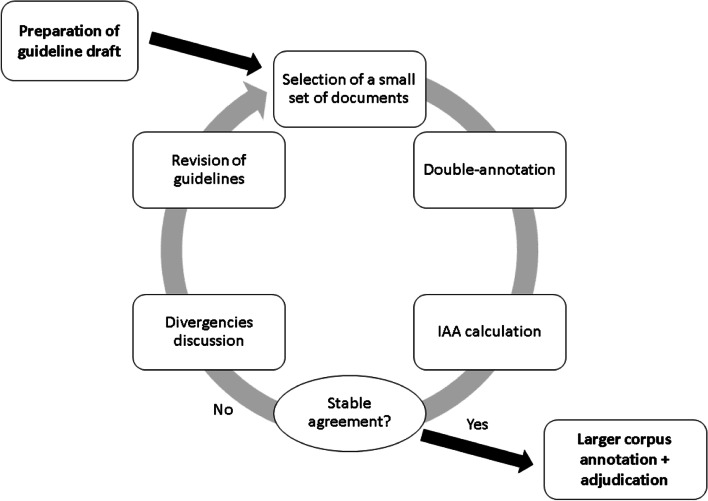
Methods: In this study, a semantically annotated corpus was developed using clinical text from multiple medical specialties, document types, and institutions. In addition, we present, (1) a survey listing common aspects, differences, and lessons learned from previous research, (2) a fine-grained annotation schema that can be replicated to guide other annotation initiatives, (3) a web-based annotation tool focusing on an annotation suggestion feature, and (4) both intrinsic and extrinsic evaluation of the annotations.
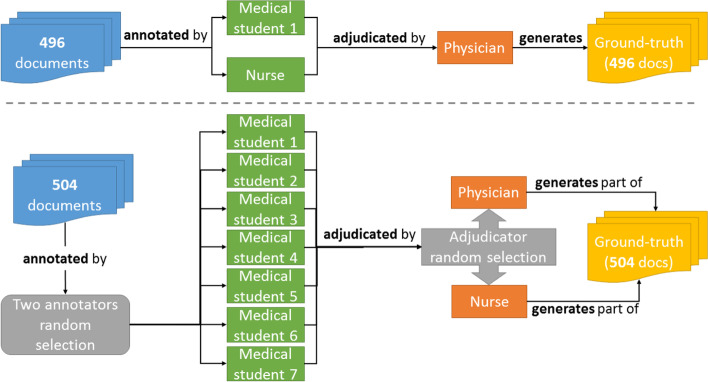
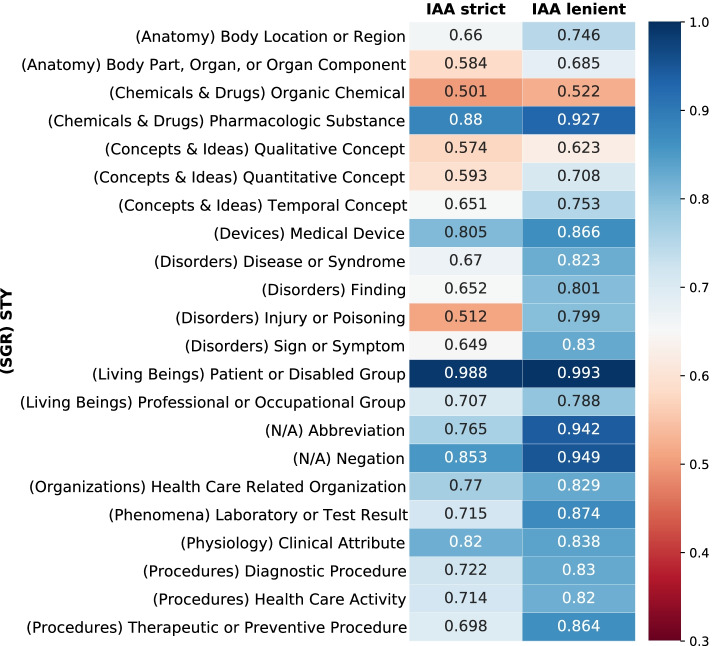
Results: This study resulted in SemClinBr, a corpus that has 1000 clinical notes, labeled with 65,117 entities and 11,263 relations. In addition, both negation cues and medical abbreviation dictionaries were generated from the annotations. The average annotator agreement score varied from 0.71 (applying strict match) to 0.92 (considering a relaxed match) while accepting partial overlaps and hierarchically related semantic types. The extrinsic evaluation, when applying the corpus to two downstream NLP tasks, demonstrated the reliability and usefulness of annotations, with the systems achieving results that were consistent with the agreement scores.
Conclusion: The SemClinBr corpus and other resources produced in this work can support clinical NLP studies, providing a common development and evaluation resource for the research community, boosting the utilization of EHRs in both clinical practice and biomedical research. To the best of our knowledge, SemClinBr is the first available Portuguese clinical corpus.
Keywords: Clinical narratives; Corpora; Gold standard; Natural language processing; Semantic annotation.
© 2022. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
Similar articles
-
Towards comprehensive syntactic and semantic annotations of the clinical narrative.J Am Med Inform Assoc. 2013 Sep-Oct;20(5):922-30. doi: 10.1136/amiajnl-2012-001317. Epub 2013 Jan 25. J Am Med Inform Assoc. 2013. PMID: 23355458 Free PMC article.
-
Web 2.0-based crowdsourcing for high-quality gold standard development in clinical natural language processing.J Med Internet Res. 2013 Apr 2;15(4):e73. doi: 10.2196/jmir.2426. J Med Internet Res. 2013. PMID: 23548263 Free PMC article.
-
Standardizing Heterogeneous Annotation Corpora Using HL7 FHIR for Facilitating their Reuse and Integration in Clinical NLP.AMIA Annu Symp Proc. 2018 Dec 5;2018:574-583. eCollection 2018. AMIA Annu Symp Proc. 2018. PMID: 30815098 Free PMC article.
-
Recent Advances in Clinical Natural Language Processing in Support of Semantic Analysis.Yearb Med Inform. 2015 Aug 13;10(1):183-93. doi: 10.15265/IY-2015-009. Yearb Med Inform. 2015. PMID: 26293867 Free PMC article. Review.
-
Natural language processing of symptoms documented in free-text narratives of electronic health records: a systematic review.J Am Med Inform Assoc. 2019 Apr 1;26(4):364-379. doi: 10.1093/jamia/ocy173. J Am Med Inform Assoc. 2019. PMID: 30726935 Free PMC article.
Cited by
-
Disambiguation of acronyms in clinical narratives with large language models.J Am Med Inform Assoc. 2024 Sep 1;31(9):2040-2046. doi: 10.1093/jamia/ocae157. J Am Med Inform Assoc. 2024. PMID: 38917444 Free PMC article.
-
Cross-lingual Natural Language Processing on Limited Annotated Case/Radiology Reports in English and Japanese: Insights from the Real-MedNLP Workshop.Methods Inf Med. 2024 Dec;63(5-06):145-163. doi: 10.1055/a-2405-2489. Epub 2024 Aug 29. Methods Inf Med. 2024. PMID: 39209296 Free PMC article.
-
Exploring the Latest Highlights in Medical Natural Language Processing across Multiple Languages: A Survey.Yearb Med Inform. 2023 Aug;32(1):230-243. doi: 10.1055/s-0043-1768726. Epub 2023 Dec 26. Yearb Med Inform. 2023. PMID: 38147865 Free PMC article.
-
Year 2022 in Medical Natural Language Processing: Availability of Language Models as a Step in the Democratization of NLP in the Biomedical Area.Yearb Med Inform. 2023 Aug;32(1):244-252. doi: 10.1055/s-0043-1768752. Epub 2023 Dec 26. Yearb Med Inform. 2023. PMID: 38147866 Free PMC article.
References
-
- Yadav P, Steinbach M, Kumar V, Simon G. Mining electronic health records (EHRs): a survey. ACM Comput Surv. 2018;50:1–40. doi: 10.1145/3127881. - DOI
-
- Summary of the HIPAA privacy rule. https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/ind.... Accessed 25 Apr 2022.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
