

PhyloMissForest: a random forest framework to construct phylogenetic trees with missing data
- PMID: 35585494
- PMCID: PMC9116704
- DOI: 10.1186/s12864-022-08540-6
PhyloMissForest: a random forest framework to construct phylogenetic trees with missing data
Abstract
Background: In the pursuit of a better understanding of biodiversity, evolutionary biologists rely on the study of phylogenetic relationships to illustrate the course of evolution. The relationships among natural organisms, depicted in the shape of phylogenetic trees, not only help to understand evolutionary history but also have a wide range of additional applications in science. One of the most challenging problems that arise when building phylogenetic trees is the presence of missing biological data. More specifically, the possibility of inferring wrong phylogenetic trees increases proportionally to the amount of missing values in the input data. Although there are methods proposed to deal with this issue, their applicability and accuracy is often restricted by different constraints.
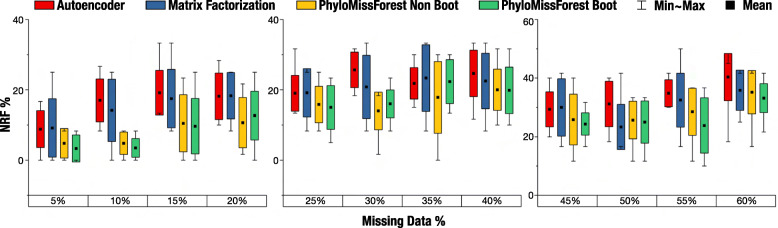
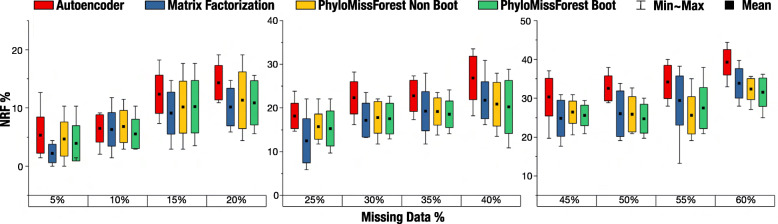
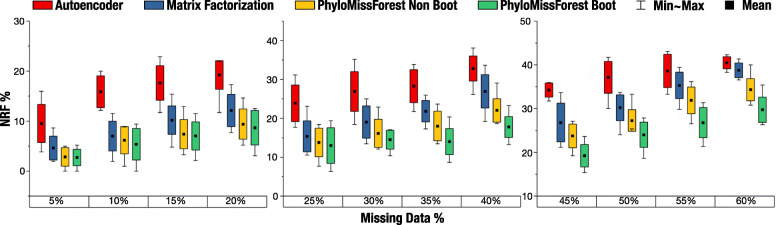
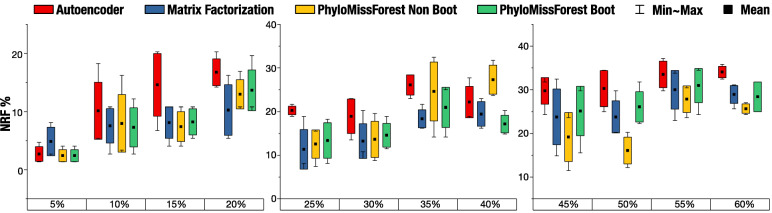
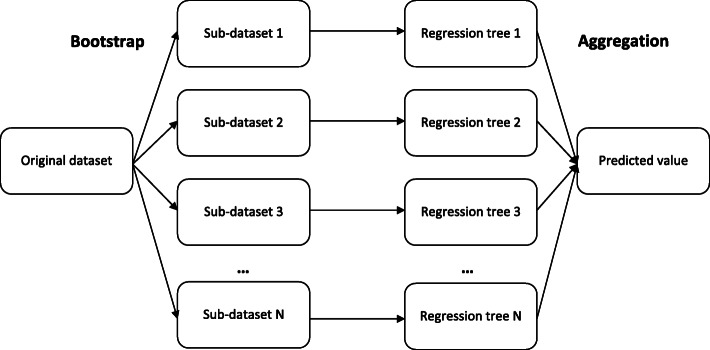
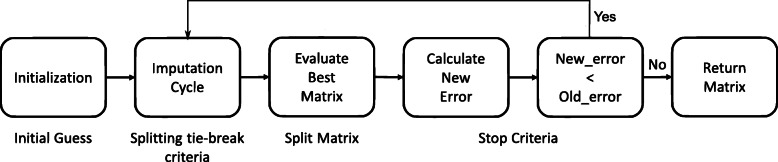
Results: We propose a framework, called PhyloMissForest, to impute missing entries in phylogenetic distance matrices and infer accurate evolutionary relationships. PhyloMissForest is built upon a random forest structure that infers the missing entries of the input data, based on the known parts of it. PhyloMissForest contributes with a robust and configurable framework that incorporates multiple search strategies and machine learning, complemented by phylogenetic techniques, to provide a more accurate inference of lost phylogenetic distances. We evaluate our framework by examining three real-world datasets, two DNA-based sequence alignments and one containing amino acid data, and two additional instances with simulated DNA data. Moreover, we follow a design of experiments methodology to define the hyperparameter values of our algorithm, which is a concise method, preferable in comparison to the well-known exhaustive parameters search. By varying the percentages of missing data from 5% to 60%, we generally outperform the state-of-the-art alternative imputation techniques in the tests conducted on real DNA data. In addition, significant improvements in execution time are observed for the amino acid instance. The results observed on simulated data also denote the attainment of improved imputations when dealing with large percentages of missing data.
Conclusions: By merging multiple search strategies, machine learning, and phylogenetic techniques, PhyloMissForest provides a highly customizable and robust framework for phylogenetic missing data imputation, with significant topological accuracy and effective speedups over the state of the art.
Keywords: Machine learning; Missing data imputation; Phylogenetic tree; Random forest.
© 2022. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures


References
-
- Lemey P, Salemi M, Vandamme A-M. The Phylogenetic Handbook: A Practical Approach to Phylogenetic Analysis and Hypothesis Testing. Cambridge: Cambridge University Press; 2009.
-
- Fernández-García JL. Phylogenetics for wildlife conservation. In: Phylogenetics. IntechOpen: 2017. p. 27–46.
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
