

A Graph-Transformer for Whole Slide Image Classification
- PMID: 35594209
- PMCID: PMC9670036
- DOI: 10.1109/TMI.2022.3176598
A Graph-Transformer for Whole Slide Image Classification
Abstract
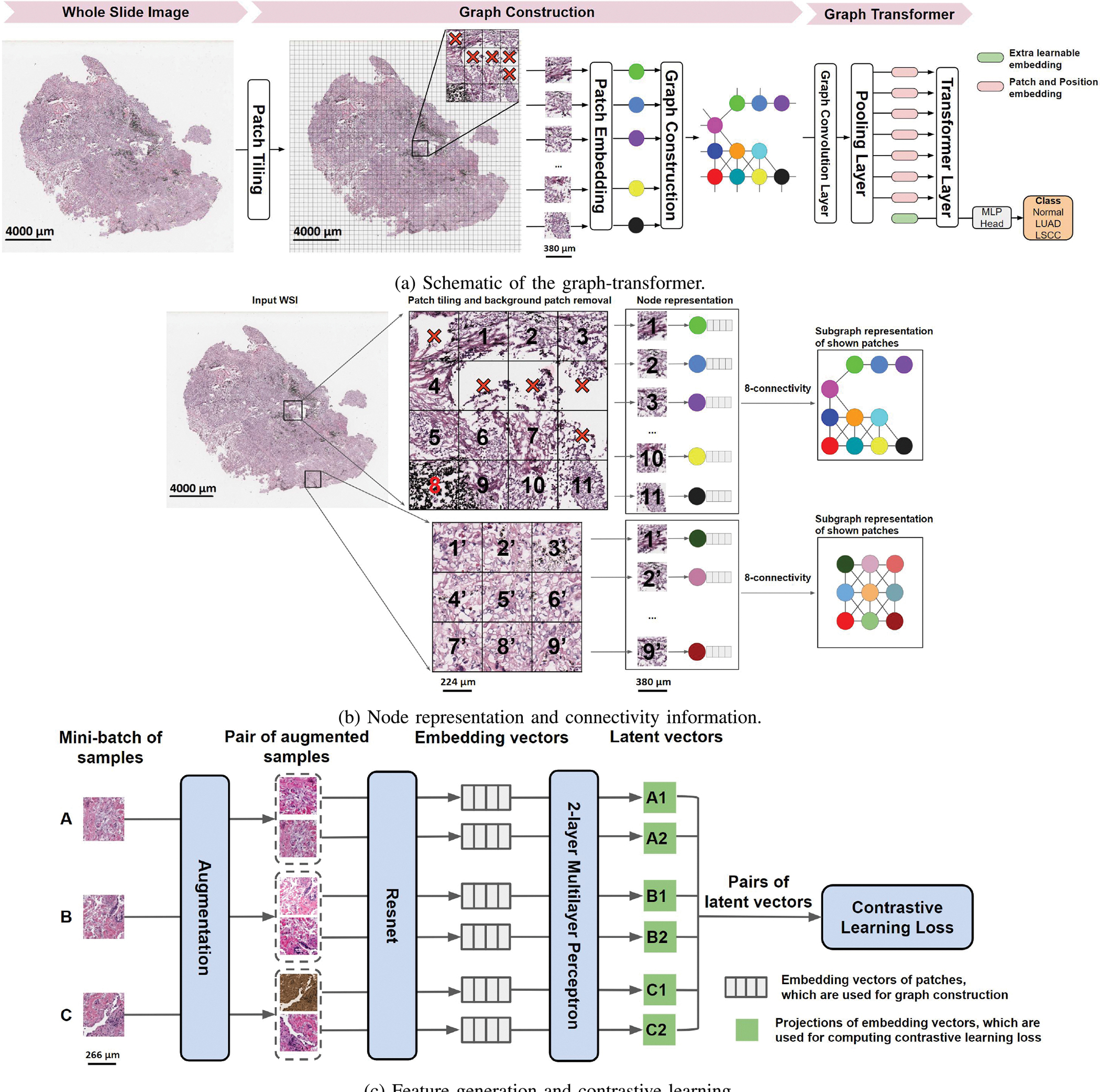
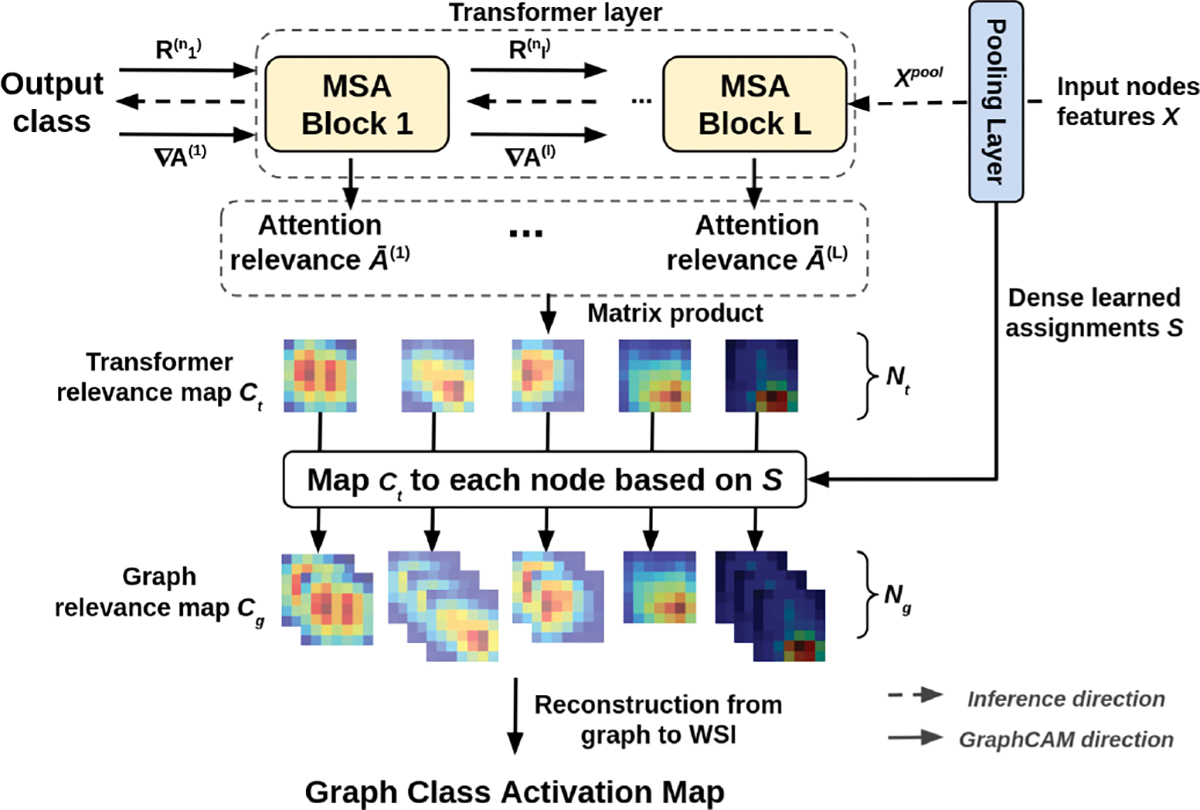
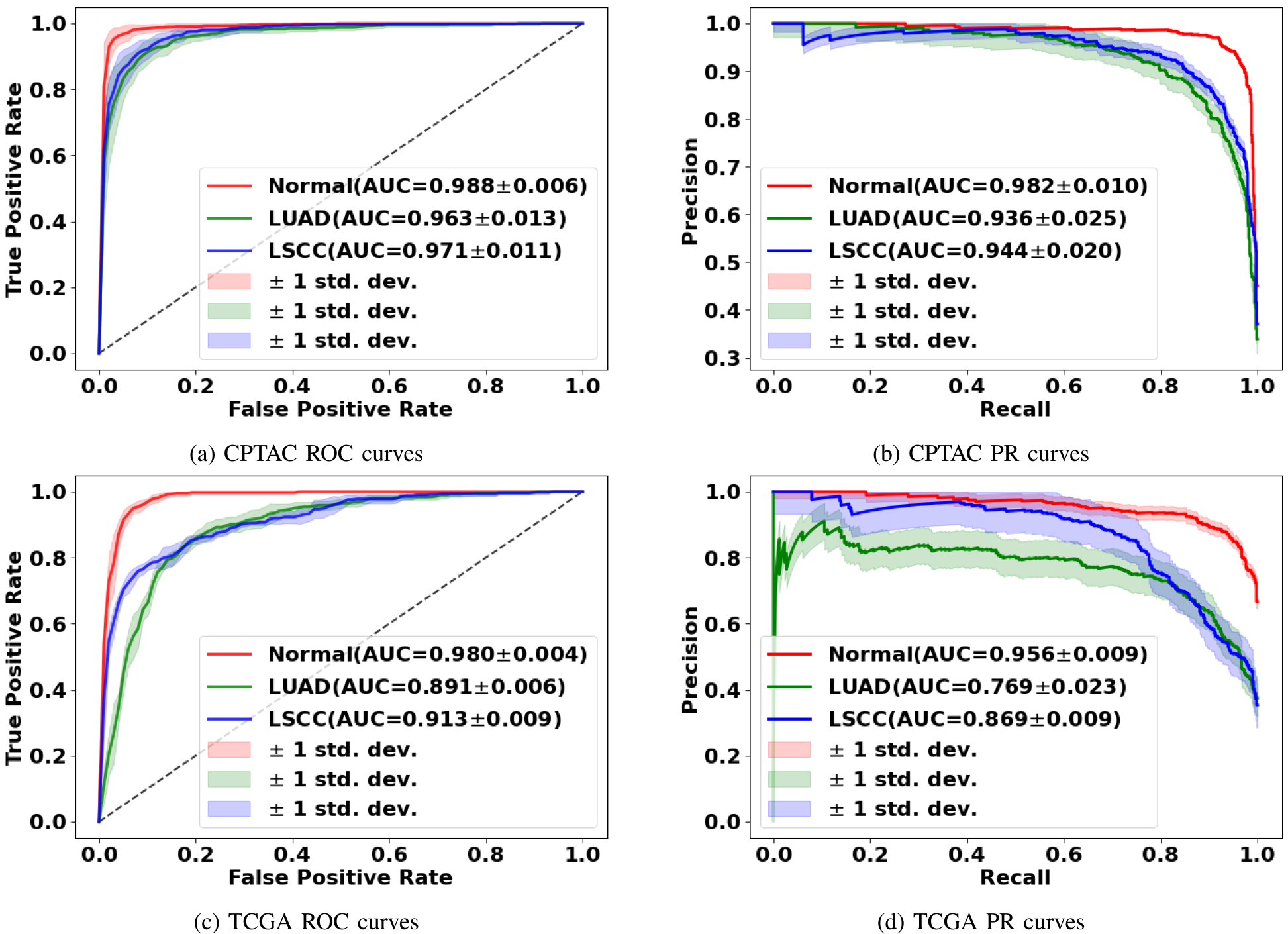
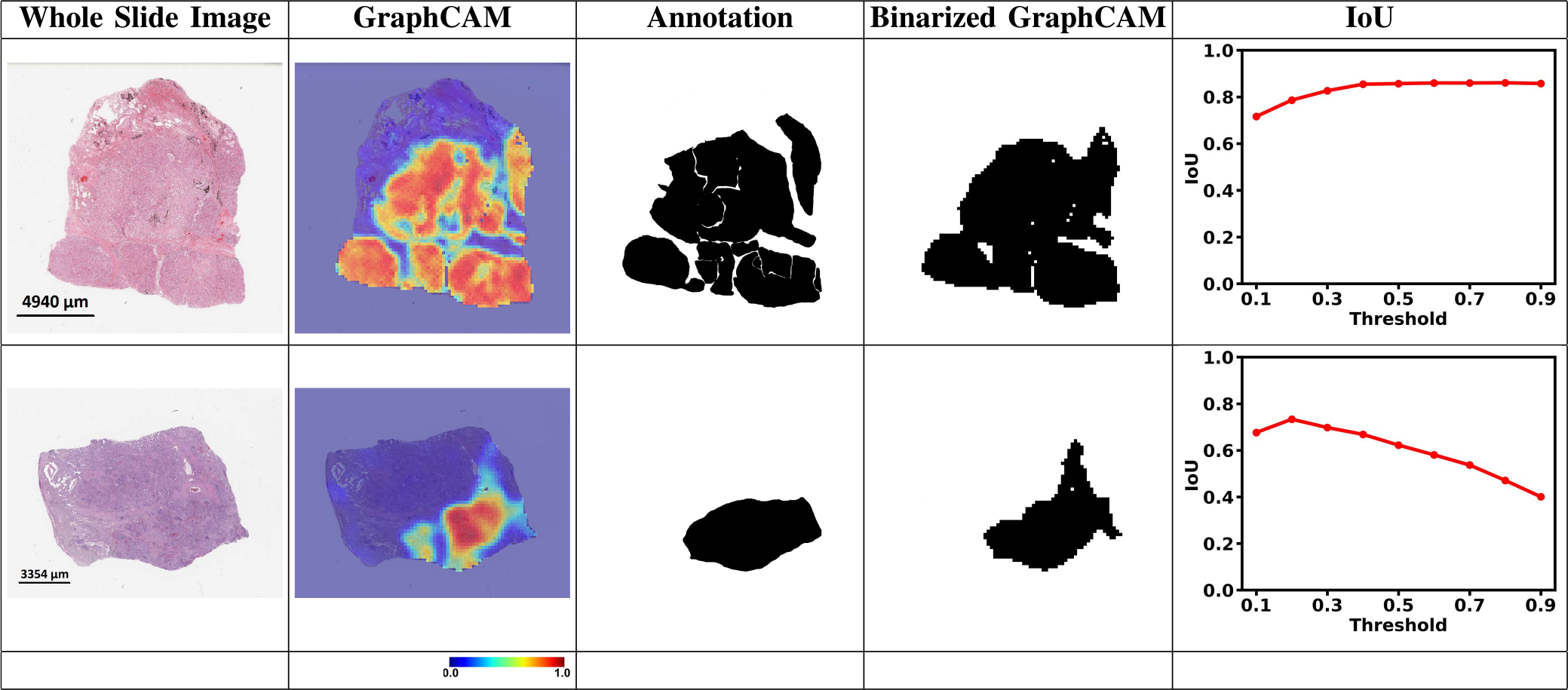
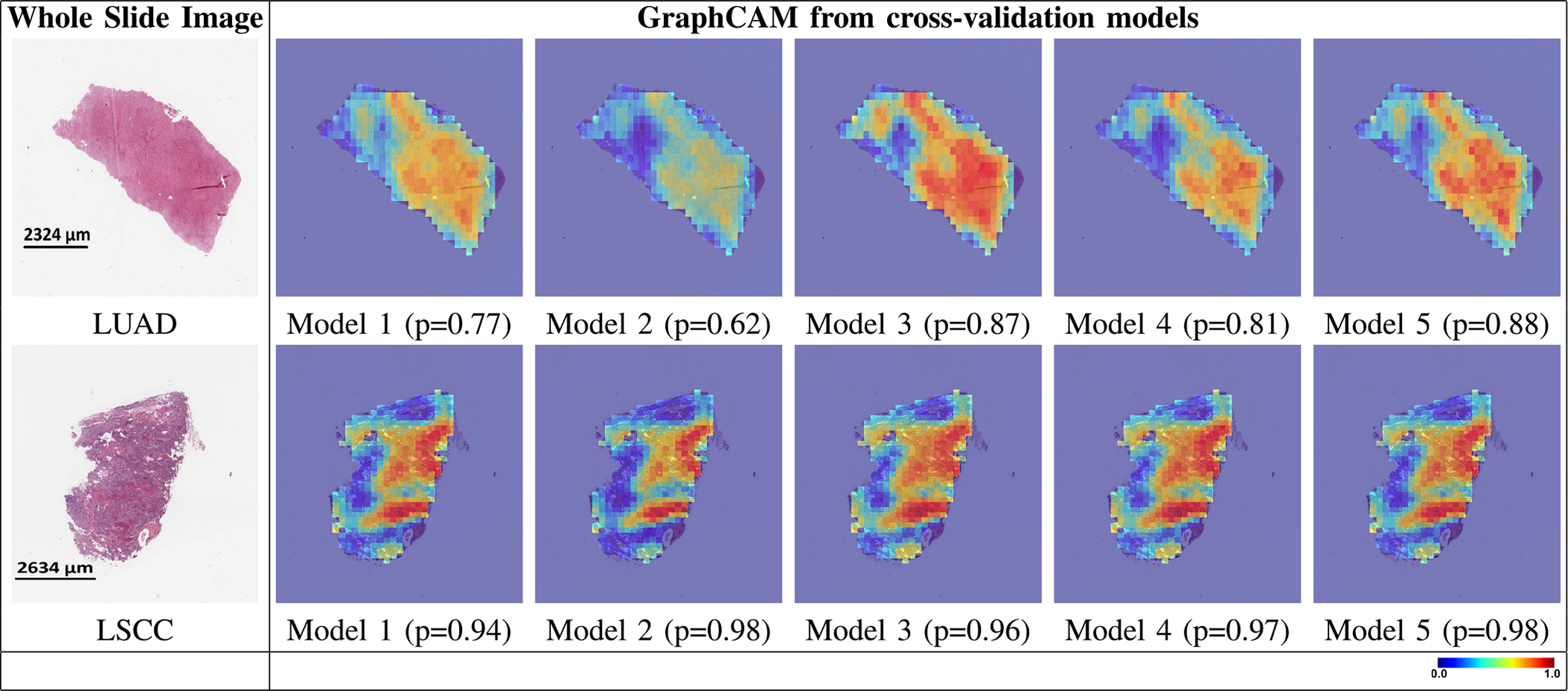
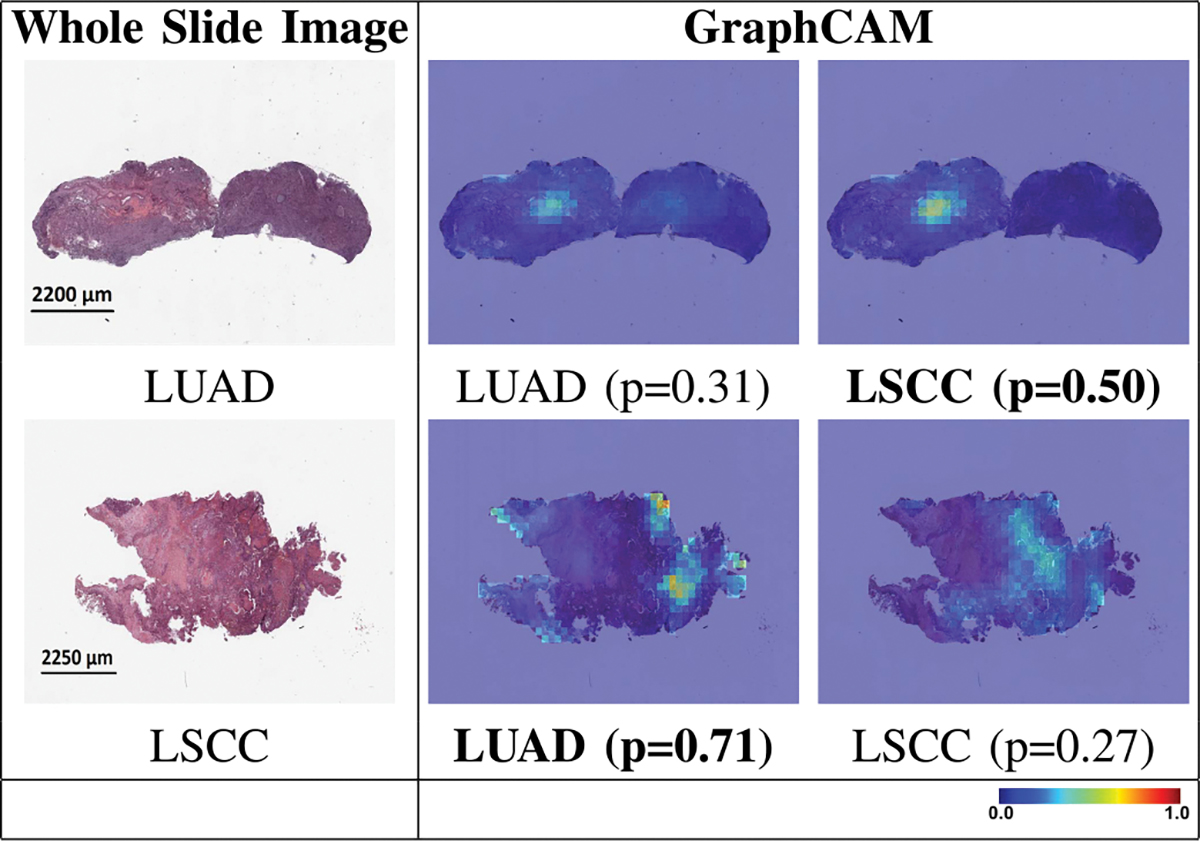
Deep learning is a powerful tool for whole slide image (WSI) analysis. Typically, when performing supervised deep learning, a WSI is divided into small patches, trained and the outcomes are aggregated to estimate disease grade. However, patch-based methods introduce label noise during training by assuming that each patch is independent with the same label as the WSI and neglect overall WSI-level information that is significant in disease grading. Here we present a Graph-Transformer (GT) that fuses a graph-based representation of an WSI and a vision transformer for processing pathology images, called GTP, to predict disease grade. We selected 4,818 WSIs from the Clinical Proteomic Tumor Analysis Consortium (CPTAC), the National Lung Screening Trial (NLST), and The Cancer Genome Atlas (TCGA), and used GTP to distinguish adenocarcinoma (LUAD) and squamous cell carcinoma (LSCC) from adjacent non-cancerous tissue (normal). First, using NLST data, we developed a contrastive learning framework to generate a feature extractor. This allowed us to compute feature vectors of individual WSI patches, which were used to represent the nodes of the graph followed by construction of the GTP framework. Our model trained on the CPTAC data achieved consistently high performance on three-label classification (normal versus LUAD versus LSCC: mean accuracy = 91.2 ± 2.5%) based on five-fold cross-validation, and mean accuracy = 82.3 ± 1.0% on external test data (TCGA). We also introduced a graph-based saliency mapping technique, called GraphCAM, that can identify regions that are highly associated with the class label. Our findings demonstrate GTP as an interpretable and effective deep learning framework for WSI-level classification.
Figures
References
-
- Louis DN et al., “Computational pathology: An emerging definition,” Arch. Pathol. Lab. Med, vol. 138, no. 9, pp. 1133–1138, Sep. 2014. - PubMed
-
- Fuchs TJ and Buhmann JM, “Computational pathology: Challenges and promises for tissue analysis,” Computerized Med. Imag. Graph, vol. 35, nos. 7–8, pp. 515–530, Oct./Dec. 2011. - PubMed
-
- Wang X et al., “Weakly supervised deep learning for whole slide lung cancer image analysis,” IEEE Trans. Cybern, vol. 50, no. 9, pp. 3950–3962, Sep. 2020. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
