

Supervised learning for analysing movement patterns in a virtual reality experiment
- PMID: 35601447
- PMCID: PMC9039785
- DOI: 10.1098/rsos.211594
Supervised learning for analysing movement patterns in a virtual reality experiment
Abstract
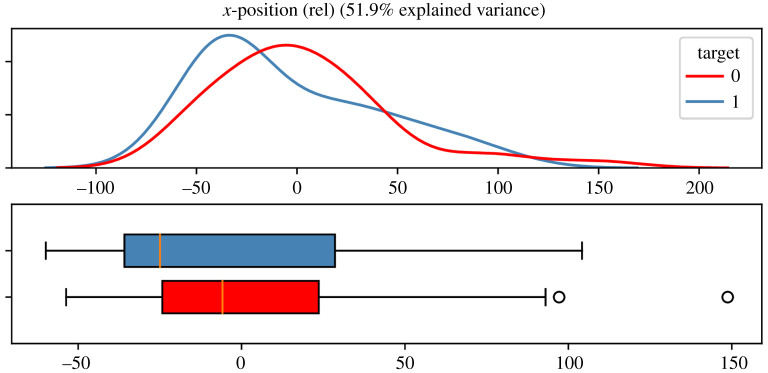
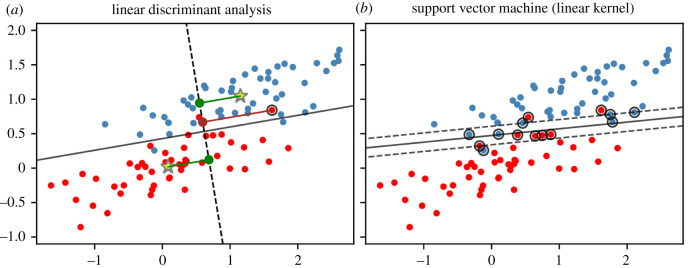
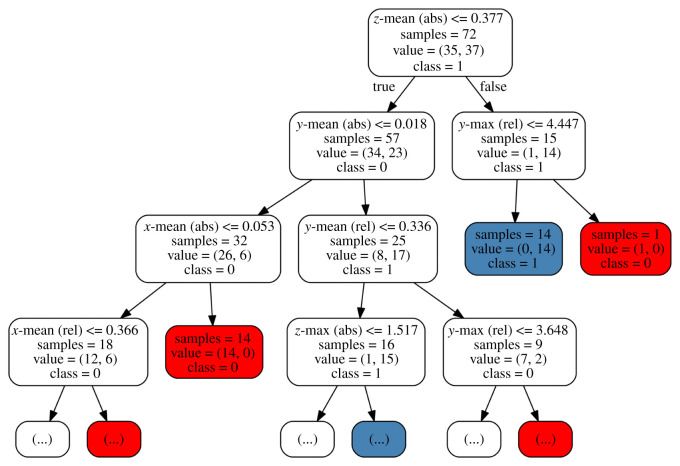
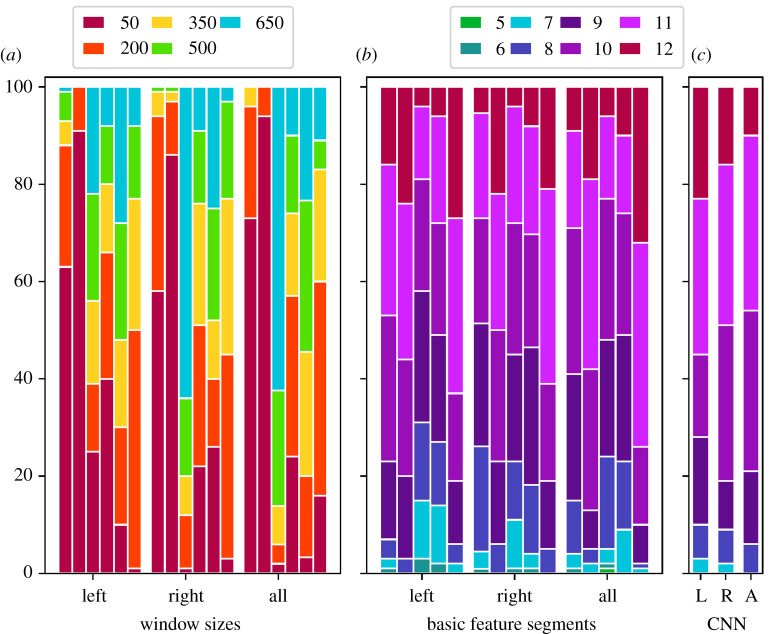
The projection into a virtual character and the concomitant illusionary body ownership can lead to transformations of one's entity. Both during and after the exposure, behavioural and attitudinal changes may occur, depending on the characteristics or stereotypes associated with the embodied avatar. In the present study, we investigated the effects on physical activity when young students experience being old. After assignment (at random) to a young or an older avatar, the participants' body movements were tracked while performing upper body exercises. We propose and discuss the use of supervised learning procedures to assign these movement patterns to the underlying avatar class in order to detect behavioural differences. This approach can be seen as an alternative to classical feature-wise testing. We found that the classification accuracy was remarkably good for support vector machines with linear kernel and deep learning by convolutional neural networks, when inserting time sub-sequences extracted at random and repeatedly from the original data. For hand movements, associated decision boundaries revealed a higher level of local, vertical positions for the young avatar group, indicating increased agility in their performances. This occurrence held for both guided movements as well as achievement-orientated exercises.
Keywords: ageing; data augmentation; deep learning; embodiment; resampling.
© 2022 The Authors.
Conflict of interest statement
We declare we have no competing interests.
Figures






References
Associated data
LinkOut - more resources
Full Text Sources