

Lipoprotein(a) beyond the kringle IV repeat polymorphism: The complexity of genetic variation in the LPA gene
- PMID: 35606073
- PMCID: PMC7613587
- DOI: 10.1016/j.atherosclerosis.2022.04.003
Lipoprotein(a) beyond the kringle IV repeat polymorphism: The complexity of genetic variation in the LPA gene
Abstract
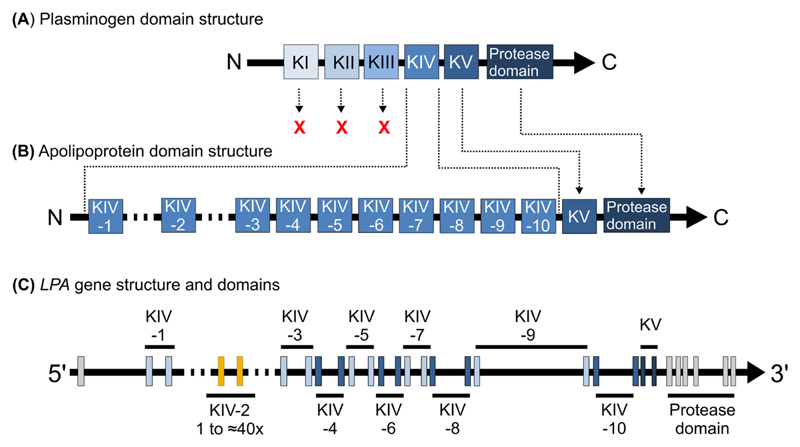
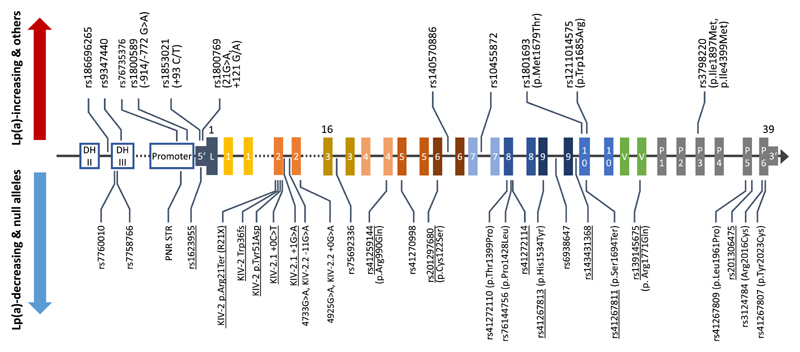
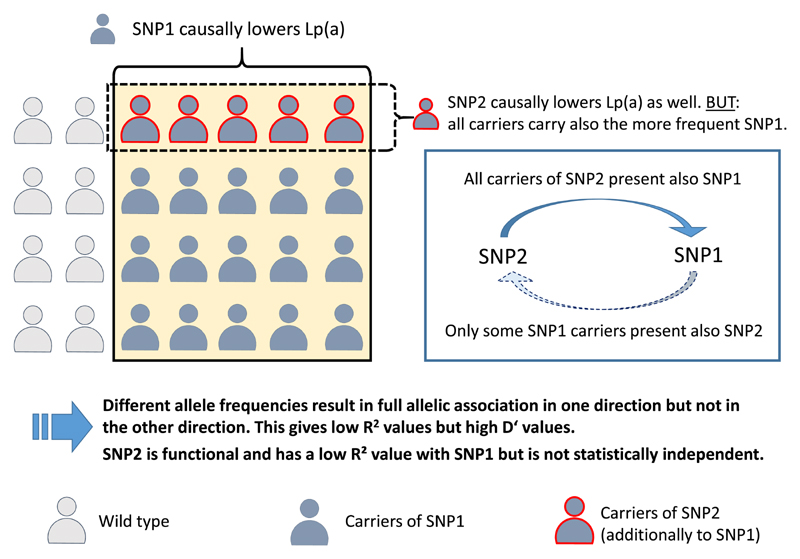
High lipoprotein(a) [Lp(a)] concentrations are one of the most important genetically determined risk factors for cardiovascular disease. Lp(a) concentrations are an enigmatic trait largely controlled by one single gene (LPA) that contains a complex interplay of several genetic elements with many surprising effects discussed in this review. A hypervariable coding copy number variation (the kringle IV type-2 repeat, KIV-2) generates >40 apolipoprotein(a) protein isoforms and determines the median Lp(a) concentrations. Carriers of small isoforms with up to 22 kringle IV domains have median Lp(a) concentrations up to 5 times higher than those with large isoforms (>22 kringle IV domains). The effect of the apo(a) isoforms are, however, modified by many functional single nucleotide polymorphisms (SNPs) distributed over the complete range of allele frequencies (<0.1% to >20%) with very pronounced effects on Lp(a) concentrations. A complex interaction is present between the apo(a) isoforms and LPA SNPs, with isoforms partially masking the effect of functional SNPs and, vice versa, SNPs lowering the Lp(a) concentrations of affected isoforms. This picture is further complicated by SNP-SNP interactions, a poorly understood role of other polymorphisms such as short tandem repeats and linkage structures that are poorly captured by common R2 values. A further layer of complexity derives from recent findings that several functional SNPs are located in the KIV-2 repeat and are thus not accessible to conventional sequencing and genotyping technologies. A critical impact of the ancestry on correlation structures and baseline Lp(a) values becomes increasingly evident. This review provides a comprehensive overview on the complex genetic architecture of the Lp(a) concentrations in plasma, a field that has made tremendous progress with the introduction of new technologies. Understanding the genetics of Lp(a) might be a key to many mysteries of Lp(a) and booster new ideas on the metabolism of Lp(a) and possible interventional targets.
Keywords: Ancestry; Ethnicity; Genetics; Kringle IV polymorphism; Kringle IV-2; LPA; Lipoprotein(a).
Copyright © 2022 The Author(s). Published by Elsevier B.V. All rights reserved.
Conflict of interest statement
The authors declare the following financial interests/personal relationships which may be considered as potential competing interests:
Dr. Kronenberg has served on the advisory boards and has received lecture fees from Novartis and Amgen.
Figures





Similar articles
-
The kringle IV type 2 domain variant 4925G>A causes the elusive association signal of the LPA pentanucleotide repeat.J Lipid Res. 2022 Dec;63(12):100306. doi: 10.1016/j.jlr.2022.100306. Epub 2022 Oct 26. J Lipid Res. 2022. PMID: 36309064 Free PMC article.
-
Comprehensive analysis of genomic variation in the LPA locus and its relationship to plasma lipoprotein(a) in South Asians, Chinese, and European Caucasians.Circ Cardiovasc Genet. 2010 Feb;3(1):39-46. doi: 10.1161/CIRCGENETICS.109.907642. Epub 2009 Dec 30. Circ Cardiovasc Genet. 2010. PMID: 20160194
-
A novel but frequent variant in LPA KIV-2 is associated with a pronounced Lp(a) and cardiovascular risk reduction.Eur Heart J. 2017 Jun 14;38(23):1823-1831. doi: 10.1093/eurheartj/ehx174. Eur Heart J. 2017. PMID: 28444229 Free PMC article.
-
Lipoprotein (a): impact by ethnicity and environmental and medical conditions.J Lipid Res. 2016 Jul;57(7):1111-25. doi: 10.1194/jlr.R051904. Epub 2015 Dec 4. J Lipid Res. 2016. PMID: 26637279 Free PMC article. Review.
-
Assessment of Apolipoprotein(a) Isoform Size Using Phenotypic and Genotypic Methods.Int J Mol Sci. 2023 Sep 9;24(18):13886. doi: 10.3390/ijms241813886. Int J Mol Sci. 2023. PMID: 37762189 Free PMC article. Review.
Cited by
-
Lipoprotein apheresis affects the concentration of extracellular vesicles in patients with elevated lipoprotein (a).Sci Rep. 2024 Feb 2;14(1):2762. doi: 10.1038/s41598-024-51782-5. Sci Rep. 2024. PMID: 38307884 Free PMC article.
-
Impact of anti-oestrogen therapy on lipoprotein(a) in postmenopausal women: a systematic review and meta-analysis of double-blind placebo-controlled clinical studies.Endocrine. 2023 May;80(2):292-302. doi: 10.1007/s12020-022-03287-2. Epub 2022 Dec 21. Endocrine. 2023. PMID: 36542268
-
Lipoprotein(a): a Case for Universal Screening in Youth.Curr Atheroscler Rep. 2023 Aug;25(8):487-493. doi: 10.1007/s11883-023-01120-3. Epub 2023 Jul 5. Curr Atheroscler Rep. 2023. PMID: 37405555 Review.
-
Lipoprotein(a) as a Stroke Biomarker: Pathophysiological Pathways and Therapeutic Implications.J Clin Med. 2025 Apr 25;14(9):2990. doi: 10.3390/jcm14092990. J Clin Med. 2025. PMID: 40364021 Free PMC article. Review.
-
Nanopore sequencing with unique molecular identifiers enables accurate mutation analysis and haplotyping in the complex lipoprotein(a) KIV-2 VNTR.Genome Med. 2024 Oct 8;16(1):117. doi: 10.1186/s13073-024-01391-8. Genome Med. 2024. PMID: 39380090 Free PMC article.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
