

Innate heuristics and fast learning support escape route selection in mice
- PMID: 35617953
- PMCID: PMC9616796
- DOI: 10.1016/j.cub.2022.05.020
Innate heuristics and fast learning support escape route selection in mice
Abstract
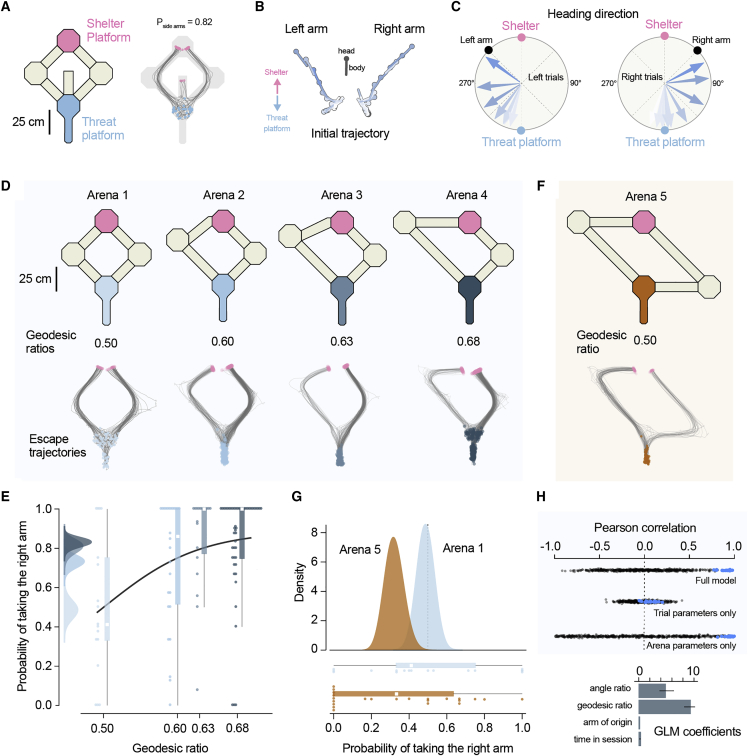
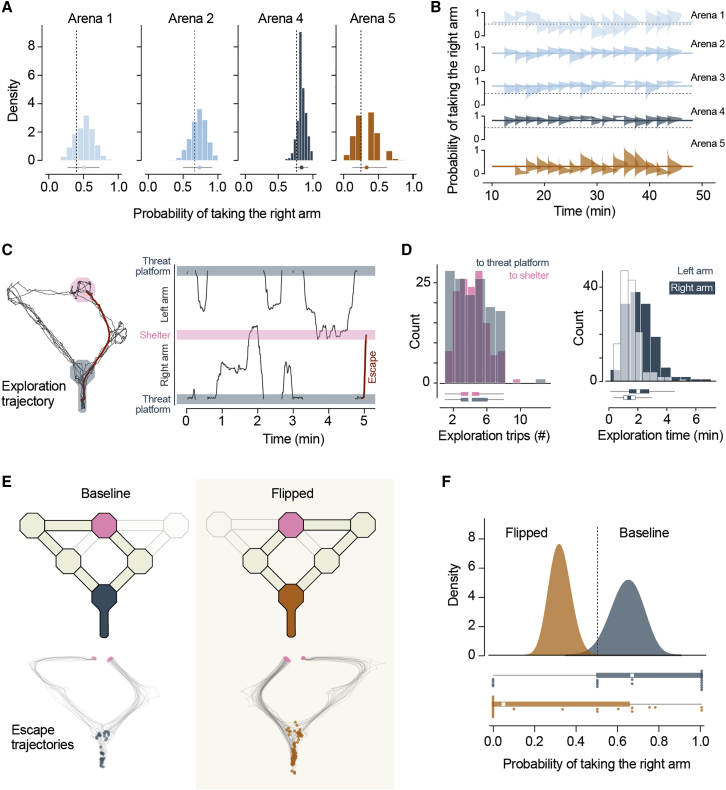
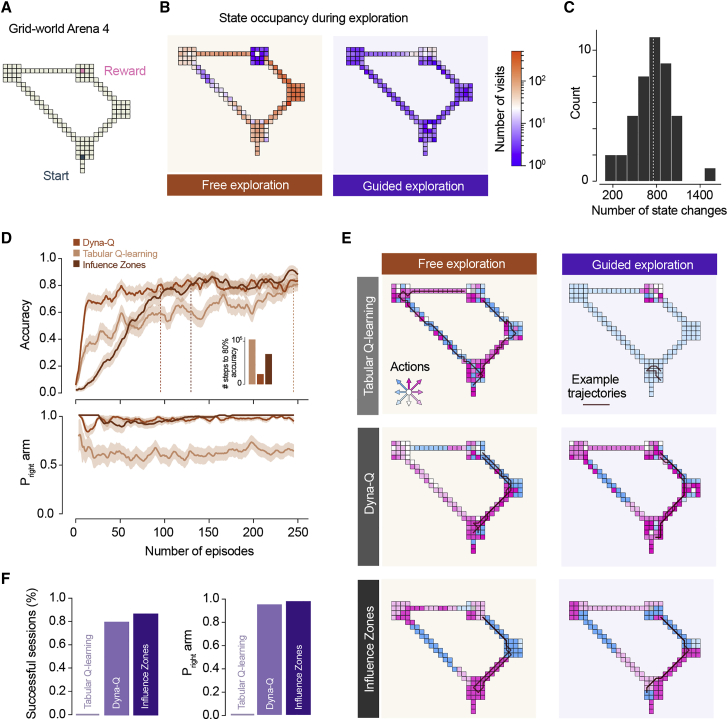
When faced with imminent danger, animals must rapidly take defensive actions to reach safety. Mice can react to threatening stimuli in ∼250 milliseconds1 and, in simple environments, use spatial memory to quickly escape to shelter.2,3 Natural habitats, however, often offer multiple routes to safety that animals must identify and choose from.4 This is challenging because although rodents can learn to navigate complex mazes,5,6 learning the value of different routes through trial and error during escape could be deadly. Here, we investigated how mice learn to choose between different escape routes. Using environments with paths to shelter of varying length and geometry, we find that mice prefer options that minimize path distance and angle relative to the shelter. This strategy is already present during the first threat encounter and after only ∼10 minutes of exploration in a novel environment, indicating that route selection does not require experience of escaping. Instead, an innate heuristic assigns survival value to each path after rapidly learning the spatial environment. This route selection process is flexible and allows quick adaptation to arenas with dynamic geometries. Computational modeling shows that model-based reinforcement learning agents replicate the observed behavior in environments where the shelter location is rewarding during exploration. These results show that mice combine fast spatial learning with innate heuristics to choose escape routes with the highest survival value. The results further suggest that integrating prior knowledge acquired through evolution with knowledge learned from experience supports adaptation to changing environments and minimizes the need for trial and error when the errors are costly.
Keywords: escape; fast learning; innate behavior; mouse; reinforcement learning; route selection; shelter.
Copyright © 2022 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures
References
-
- Cooper W., Jr., Cooper W.E., Jr., Blumstein D.T. Cambridge University Press; 2015. Escaping From Predators: An Integrative View of Escape Decisions.
-
- De Camp J.E. Relative distance as a factor in the white rat’s selection of a path. Psychobiology. 1920;2:245–253. doi: 10.1037/h0075411. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
