

How much can we differentiate at a brief glance: revealing the truer limit in conscious contents through the massive report paradigm (MRP)
- PMID: 35619998
- PMCID: PMC9128849
- DOI: 10.1098/rsos.210394
How much can we differentiate at a brief glance: revealing the truer limit in conscious contents through the massive report paradigm (MRP)
Abstract
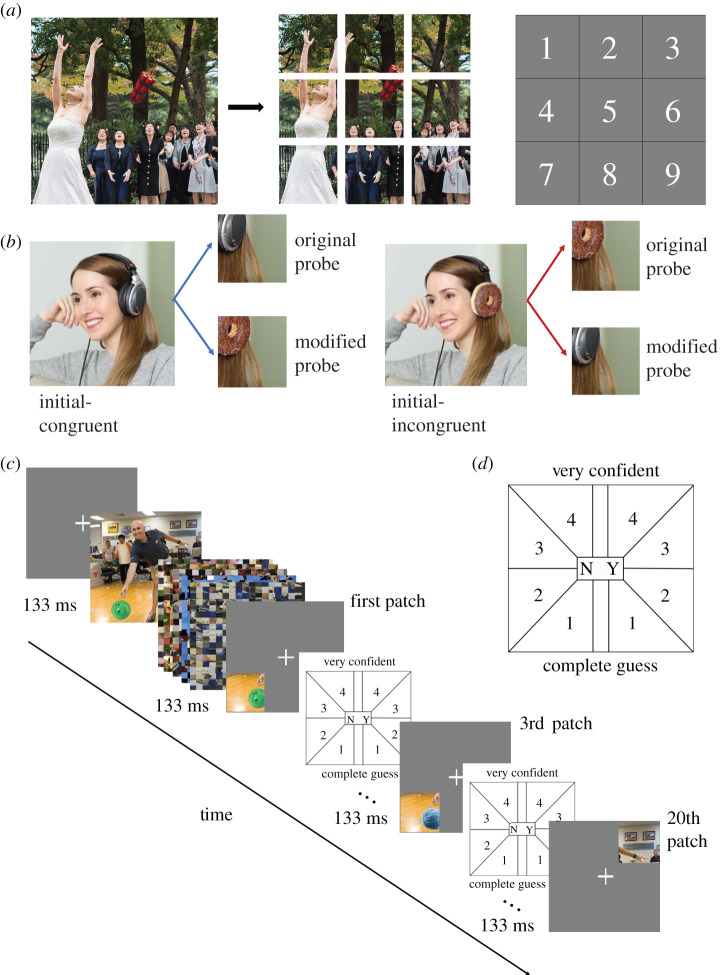
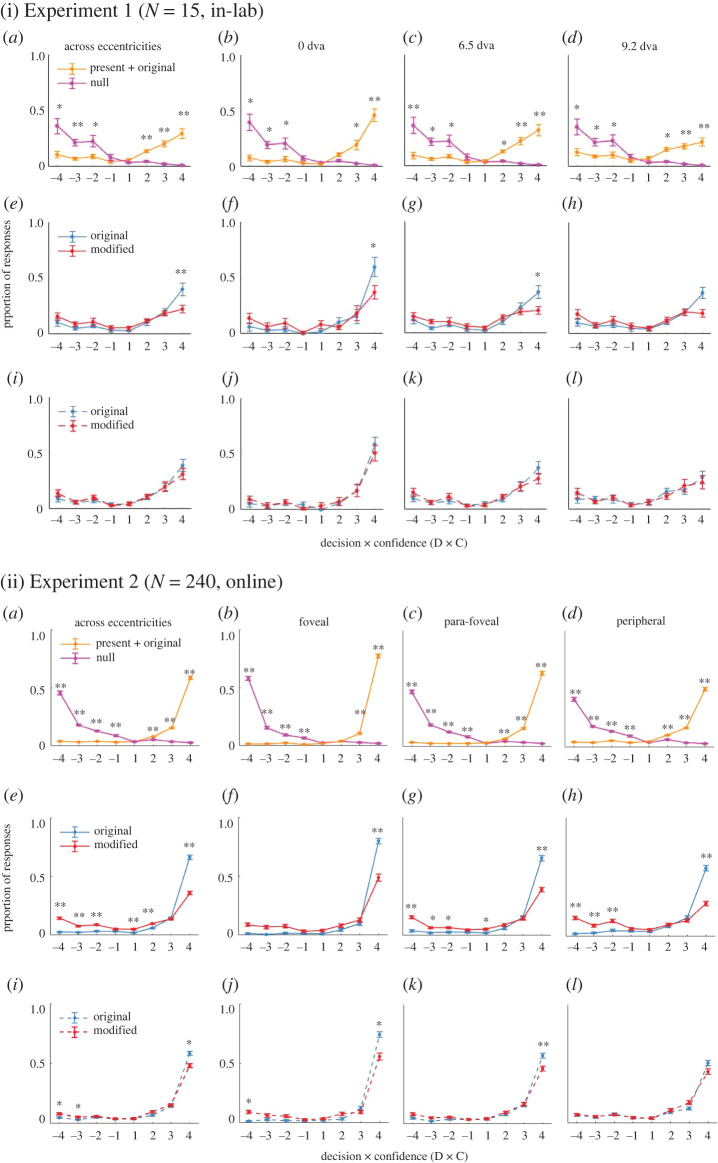
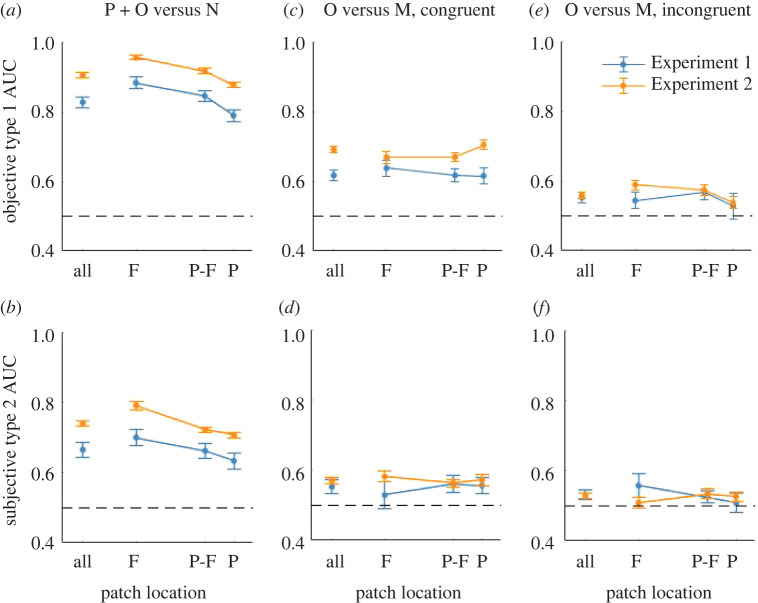
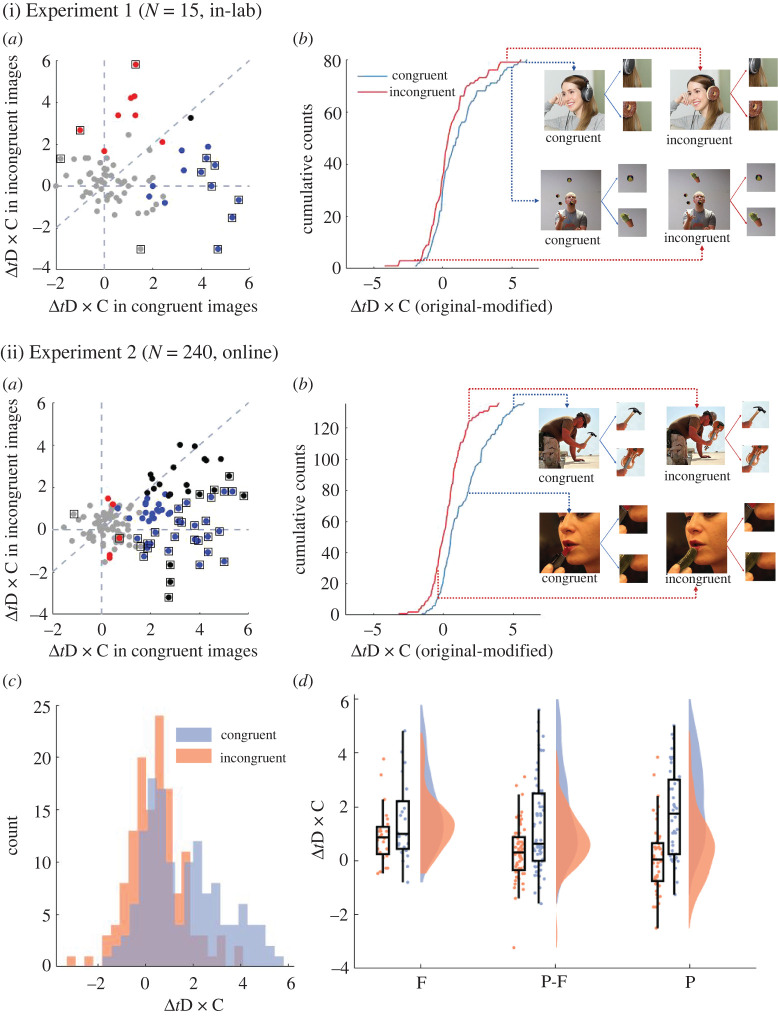
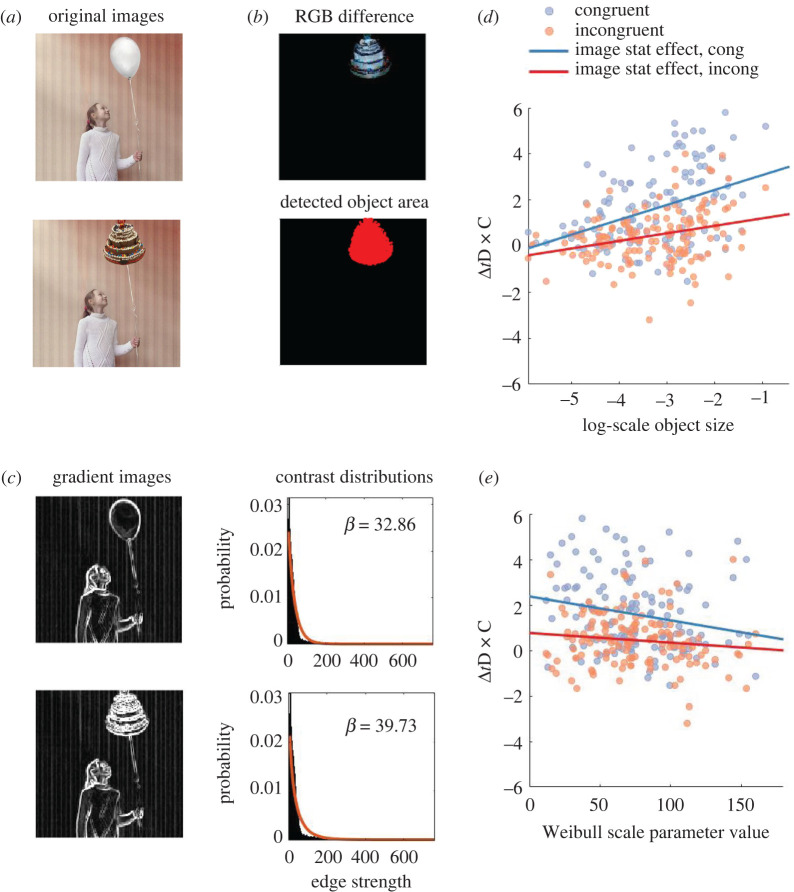
Upon a brief glance, how well can we differentiate what we see from what we do not? Previous studies answered this question as 'poorly'. This is in stark contrast with our everyday experience. Here, we consider the possibility that previous restriction in stimulus variability and response alternatives reduced what participants could express from what they consciously experienced. We introduce a novel massive report paradigm that probes the ability to differentiate what we see from what we do not. In each trial, participants viewed a natural scene image and judged whether a small image patch was a part of the original image. To examine the limit of discriminability, we also included subtler changes in the image as modification of objects. Neither the images nor patches were repeated per participant. Our results showed that participants were highly accurate (accuracy greater than 80%) in differentiating patches from the viewed images from patches that are not present. Additionally, the differentiation between original and modified objects was influenced by object sizes and/or the congruence between objects and the scene gists. Our massive report paradigm opens a door to quantitatively measure the limit of immense informativeness of a moment of consciousness.
Keywords: consciousness; contents of consciousness; expectation; massive report paradigms; natural scene perception; qualia.
© 2022 The Authors.
Figures
Similar articles
-
What can we experience and report on a rapidly presented image? Intersubjective measures of specificity of freely reported contents of consciousness.F1000Res. 2022 Jan 20;11:69. doi: 10.12688/f1000research.75364.3. eCollection 2022. F1000Res. 2022. PMID: 36176545 Free PMC article.
-
Conscious interpretation: A distinct aspect for the neural markers of the contents of consciousness.Conscious Cogn. 2023 Feb;108:103471. doi: 10.1016/j.concog.2023.103471. Epub 2023 Feb 1. Conscious Cogn. 2023. PMID: 36736210 Review.
-
Consciousness, biology and quantum hypotheses.Phys Life Rev. 2012 Sep;9(3):285-94. doi: 10.1016/j.plrev.2012.07.001. Epub 2012 Jul 10. Phys Life Rev. 2012. PMID: 22925839 Review.
-
Unconscious categorization of sub-millisecond complex images.PLoS One. 2020 Aug 12;15(8):e0236467. doi: 10.1371/journal.pone.0236467. eCollection 2020. PLoS One. 2020. PMID: 32785238 Free PMC article.
-
A new no-report paradigm reveals that face cells encode both consciously perceived and suppressed stimuli.Elife. 2020 Nov 11;9:e58360. doi: 10.7554/eLife.58360. Elife. 2020. PMID: 33174836 Free PMC article.
Cited by
-
Is episodic-like memory like episodic memory?Philos Trans R Soc Lond B Biol Sci. 2024 Nov 4;379(1913):20230397. doi: 10.1098/rstb.2023.0397. Epub 2024 Sep 16. Philos Trans R Soc Lond B Biol Sci. 2024. PMID: 39278246 Free PMC article. Review.
-
Dimensions of corvid consciousness.Anim Cogn. 2025 May 2;28(1):35. doi: 10.1007/s10071-025-01949-y. Anim Cogn. 2025. PMID: 40316871 Free PMC article. Review.
-
Eurasian jays (Garrulus glandarius) show episodic-like memory through the incidental encoding of information.PLoS One. 2024 May 15;19(5):e0301298. doi: 10.1371/journal.pone.0301298. eCollection 2024. PLoS One. 2024. PMID: 38748646 Free PMC article.
-
How much can children see and report about their experience of a brief glance at a natural scene?Neurosci Conscious. 2025 Aug 7;2025(1):niaf019. doi: 10.1093/nc/niaf019. eCollection 2025. Neurosci Conscious. 2025. PMID: 40799209 Free PMC article.
-
More than words: can free reports adequately measure the richness of perception?Neurosci Conscious. 2024 Oct 23;2024(1):niae035. doi: 10.1093/nc/niae035. eCollection 2024. Neurosci Conscious. 2024. PMID: 39445136 Free PMC article.
References
-
- Rensink RA, O'regan JK, Clark JJ. 1997. To see or not to see: the need for attention to perceive changes in scenes. Psychol. Sci. 8, 368-373. (10.1111/j.1467-9280.1997.tb00427.x) - DOI
-
- Simons DJ, Ambinder MS. 2005. Change blindness: theory and consequences. Curr. Dir. Psychol. Sci. 14, 44-48. (10.1111/j.0963-7214.2005.00332.x) - DOI
Associated data
LinkOut - more resources
Full Text Sources
