

Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection
- PMID: 35626570
- PMCID: PMC9140774
- DOI: 10.3390/e24050687
Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection
Abstract
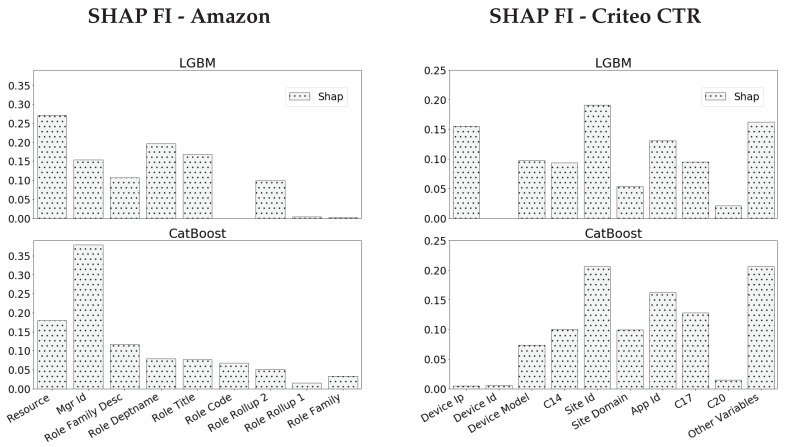
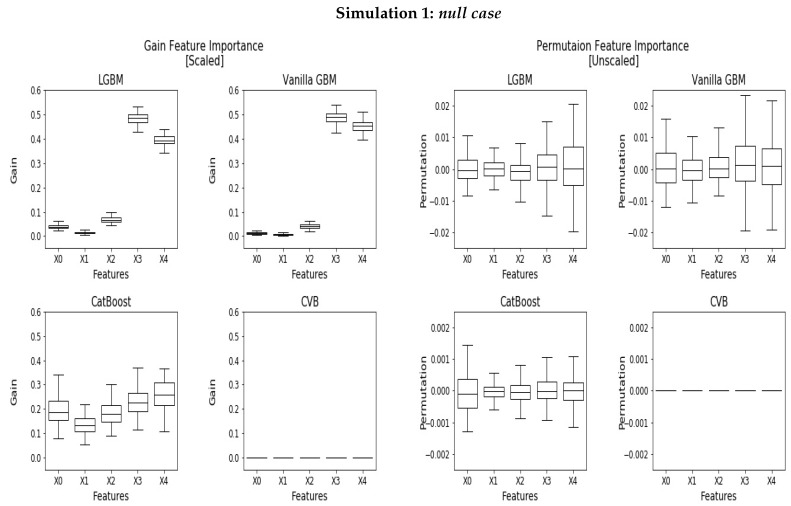
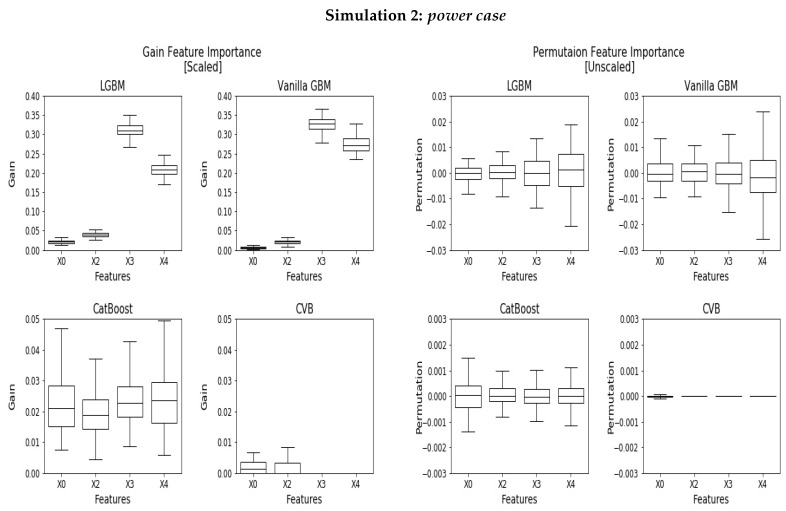
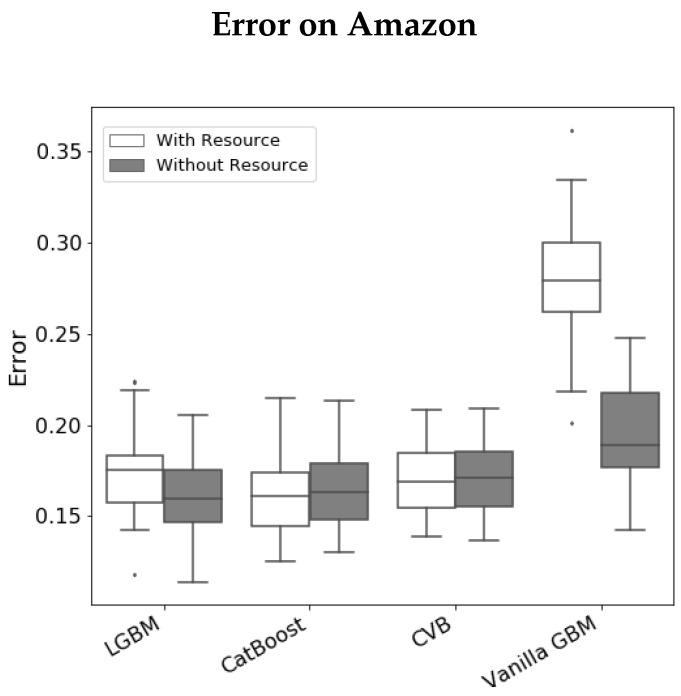
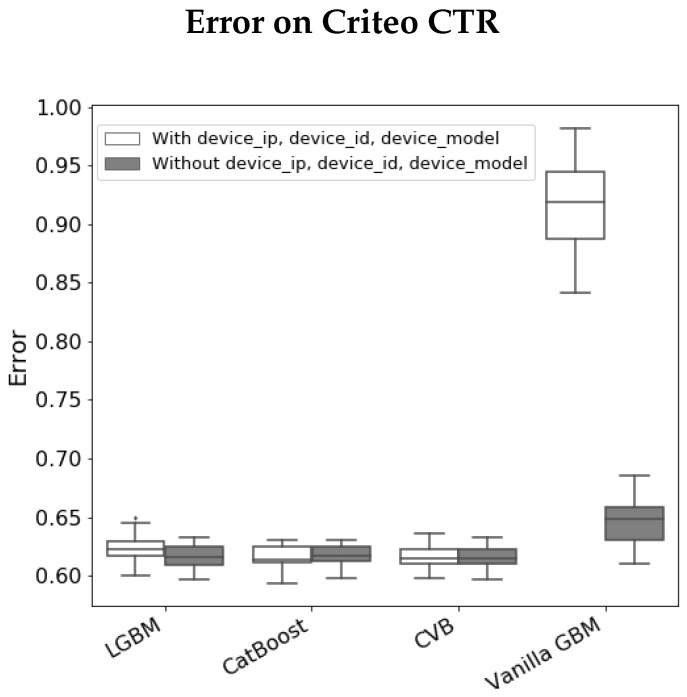
Gradient Boosting Machines (GBM) are among the go-to algorithms on tabular data, which produce state-of-the-art results in many prediction tasks. Despite its popularity, the GBM framework suffers from a fundamental flaw in its base learners. Specifically, most implementations utilize decision trees that are typically biased towards categorical variables with large cardinalities. The effect of this bias was extensively studied over the years, mostly in terms of predictive performance. In this work, we extend the scope and study the effect of biased base learners on GBM feature importance (FI) measures. We demonstrate that although these implementation demonstrate highly competitive predictive performance, they still, surprisingly, suffer from bias in FI. By utilizing cross-validated (CV) unbiased base learners, we fix this flaw at a relatively low computational cost. We demonstrate the suggested framework in a variety of synthetic and real-world setups, showing a significant improvement in all GBM FI measures while maintaining relatively the same level of prediction accuracy.
Keywords: classification and regression trees; feature importance; gradient boosting; tree-based methods.
Conflict of interest statement
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Figures
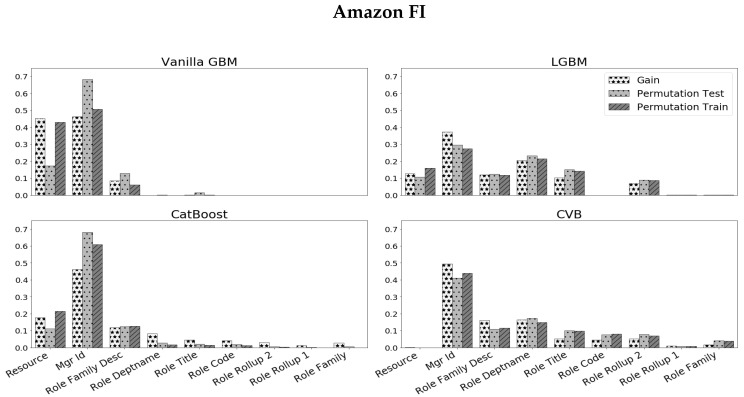
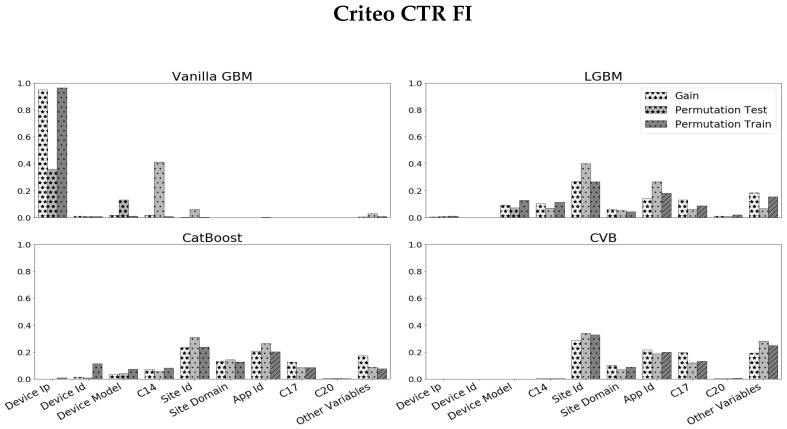
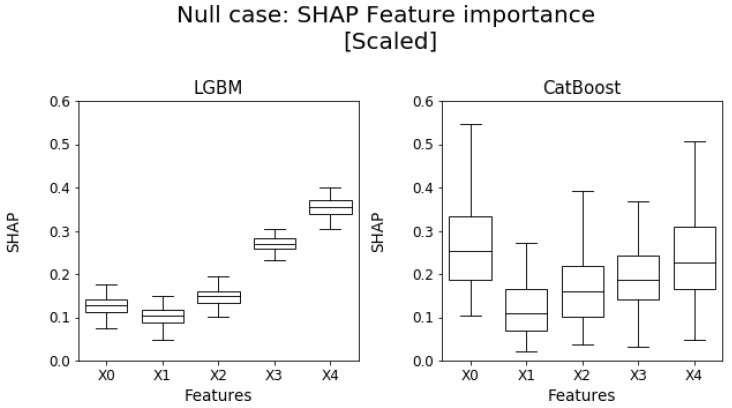
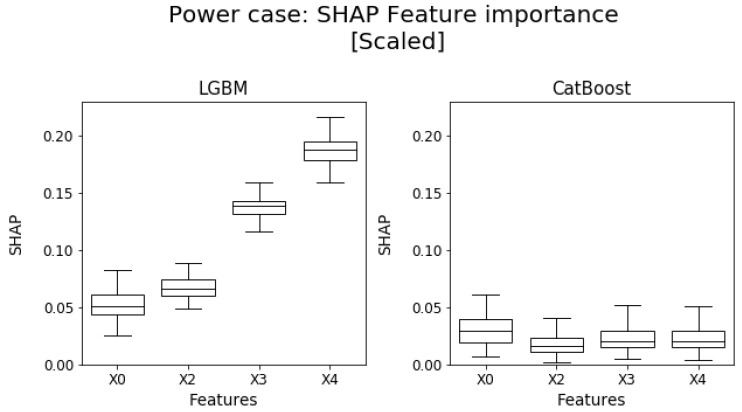
References
-
- Lundberg S.M., Nair B., Vavilala M.S., Horibe M., Eisses M.J., Adams T., Liston D.E., Low D.K.W., Newman S.F., Kim J., et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018;2:749–760. doi: 10.1038/s41551-018-0304-0. - DOI - PMC - PubMed
-
- Friedman J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001;29:1189–1232. doi: 10.1214/aos/1013203451. - DOI
-
- Breiman L., Friedman J., Stone C.J., Olshen R.A. Classification and Regression Trees. CRC Press; Boca Raton, FL, USA: 1984.
-
- Quinlan J.R. Induction of decision trees. Mach. Learn. 1986;1:81–106. doi: 10.1007/BF00116251. - DOI
-
- Richardson M., Dominowska E., Ragno R. Predicting clicks: Estimating the click-through rate for new ads; Proceedings of the 16th International Conference on World Wide Web; Banff, AB, Canada. 8–12 May 2007; pp. 521–530.
LinkOut - more resources
Full Text Sources
