

Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery
- PMID: 35632096
- PMCID: PMC9147286
- DOI: 10.3390/s22103688
Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery
Abstract
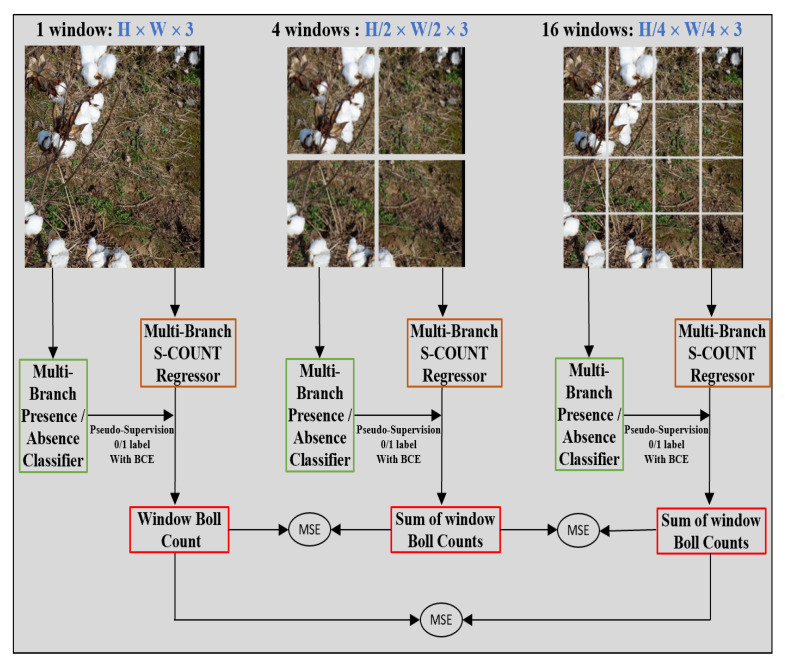
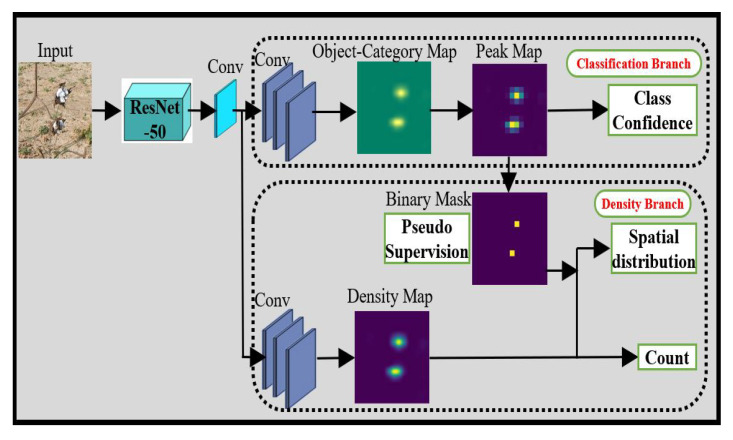
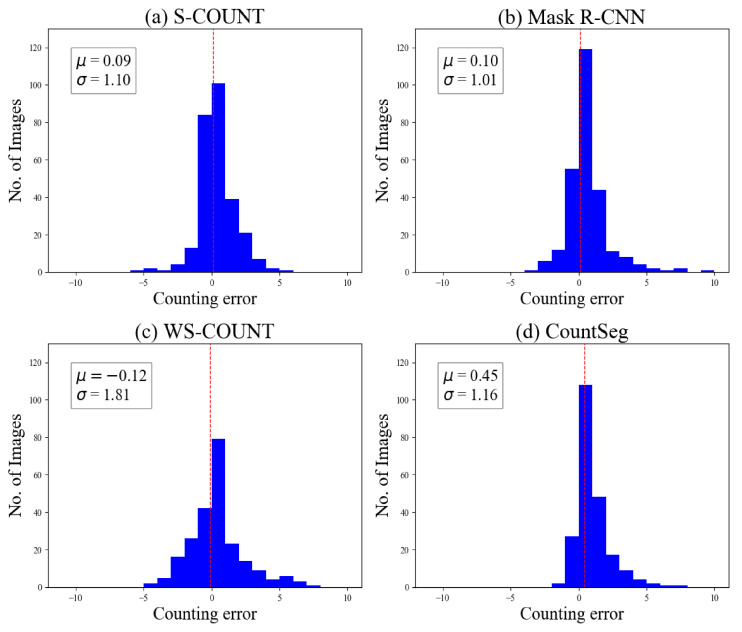
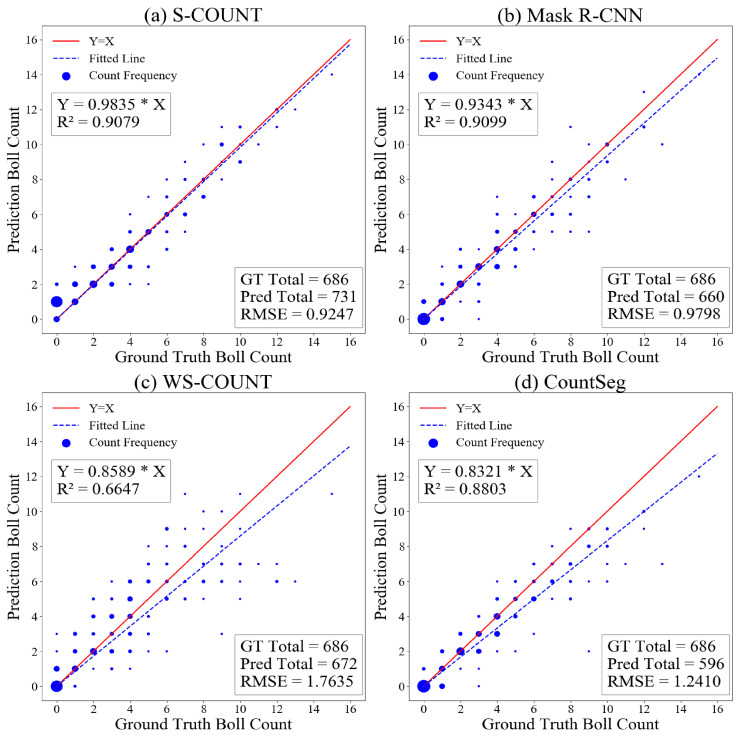
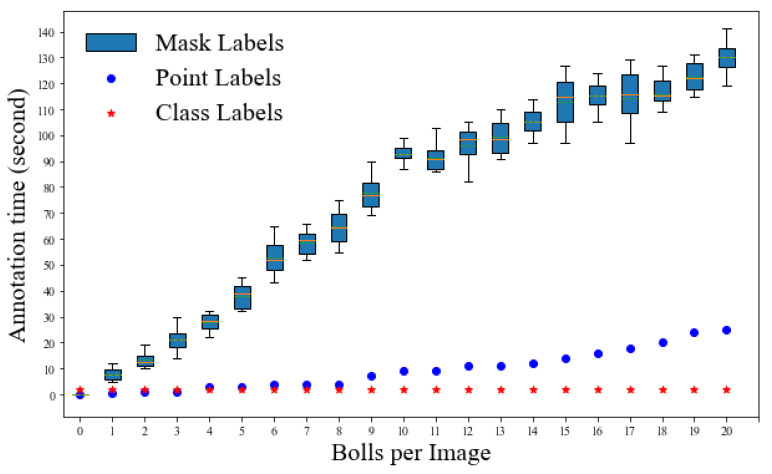
The total boll count from a plant is one of the most important phenotypic traits for cotton breeding and is also an important factor for growers to estimate the final yield. With the recent advances in deep learning, many supervised learning approaches have been implemented to perform phenotypic trait measurement from images for various crops, but few studies have been conducted to count cotton bolls from field images. Supervised learning models require a vast number of annotated images for training, which has become a bottleneck for machine learning model development. The goal of this study is to develop both fully supervised and weakly supervised deep learning models to segment and count cotton bolls from proximal imagery. A total of 290 RGB images of cotton plants from both potted (indoor and outdoor) and in-field settings were taken by consumer-grade cameras and the raw images were divided into 4350 image tiles for further model training and testing. Two supervised models (Mask R-CNN and S-Count) and two weakly supervised approaches (WS-Count and CountSeg) were compared in terms of boll count accuracy and annotation costs. The results revealed that the weakly supervised counting approaches performed well with RMSE values of 1.826 and 1.284 for WS-Count and CountSeg, respectively, whereas the fully supervised models achieve RMSE values of 1.181 and 1.175 for S-Count and Mask R-CNN, respectively, when the number of bolls in an image patch is less than 10. In terms of data annotation costs, the weakly supervised approaches were at least 10 times more cost efficient than the supervised approach for boll counting. In the future, the deep learning models developed in this study can be extended to other plant organs, such as main stalks, nodes, and primary and secondary branches. Both the supervised and weakly supervised deep learning models for boll counting with low-cost RGB images can be used by cotton breeders, physiologists, and growers alike to improve crop breeding and yield estimation.
Keywords: boll counting; cotton phenotyping; mask R-CNN; supervised learning; weakly supervised learning.
Conflict of interest statement
The authors declare no conflict of interest.
Figures



References
-
- FAOSTAT . FAOSTAT Statistical Database. FAO (Food and Agriculture Organization of the United Nations); Rome, Italy: 2019.
-
- Pabuayon I.L.B., Kelly B.R., Mitchell-McCallister D., Coldren C.L., Ritchie G.L. Cotton boll distribution: A review. Agron. J. 2021;113:956–970. doi: 10.1002/agj2.20516. - DOI
-
- Normanly J. High-Throughput Phenotyping in Plants: Methods and Protocols. Springer; Berlin/Heidelberg, Germany: 2012.
-
- Pabuayon I.L.B., Yazhou S., Wenxuan G., Ritchie G.L. High-throughput phenotyping in cotton: A review. J. Cotton Res. 2019;2:1–9. doi: 10.1186/s42397-019-0035-0. - DOI
-
- Uddin M.S., Bansal J.C. Computer Vision and Machine Learning in Agriculture. Springer; Berlin/Heidelberg, Germany: 2021.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
