

Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN
- PMID: 35684807
- PMCID: PMC9185418
- DOI: 10.3390/s22114187
Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN
Abstract
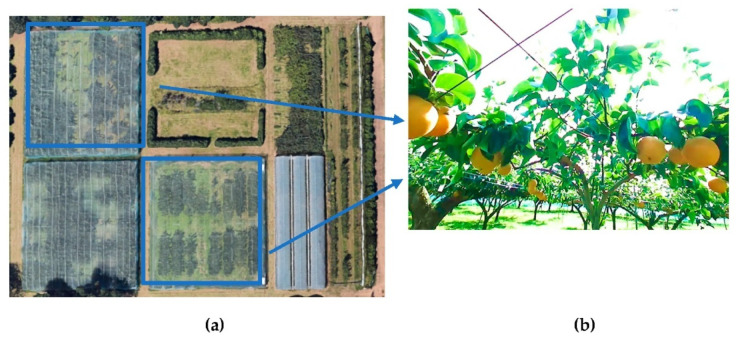
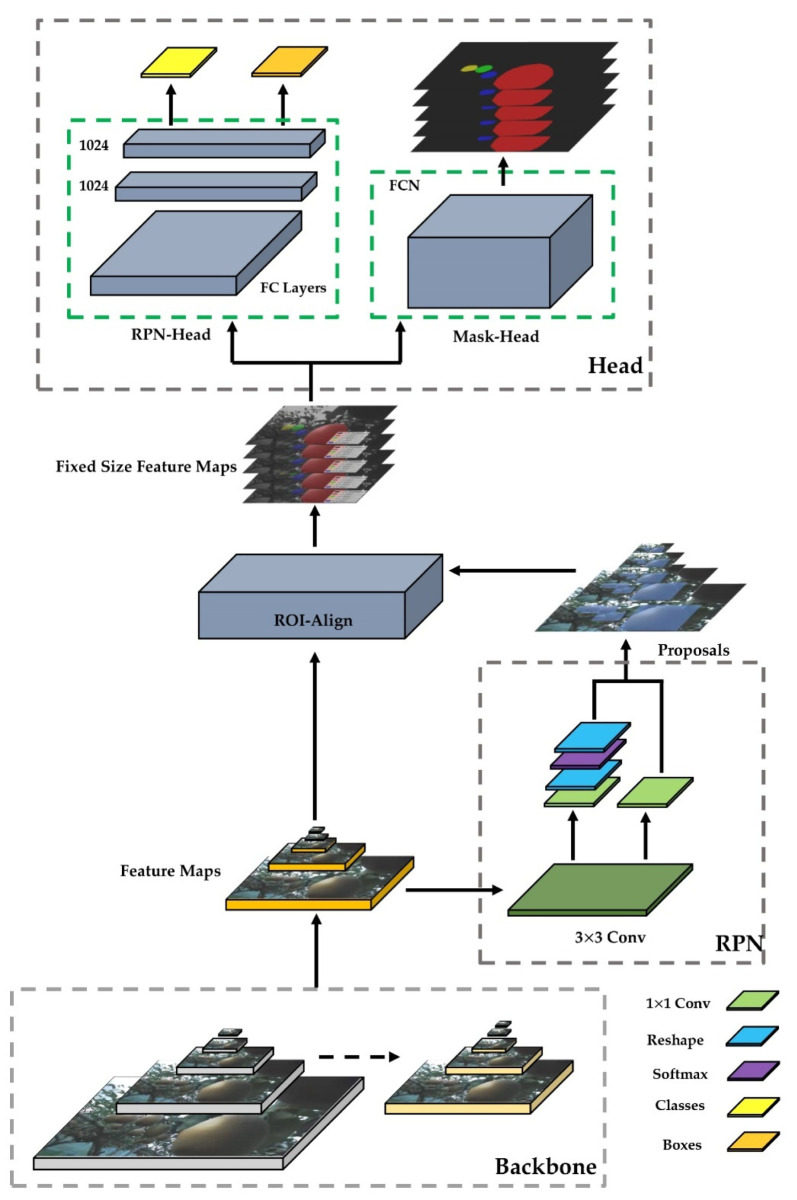
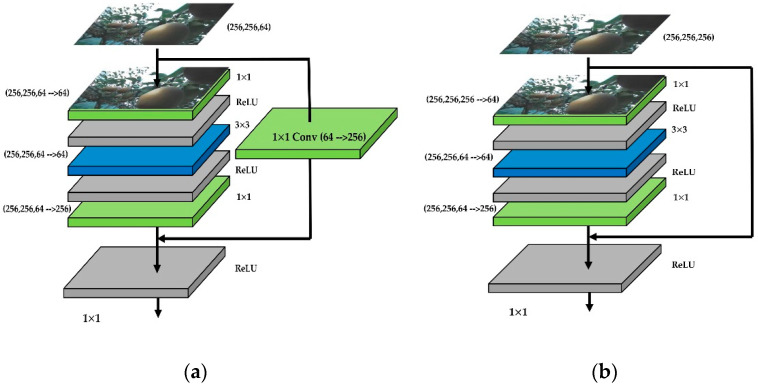
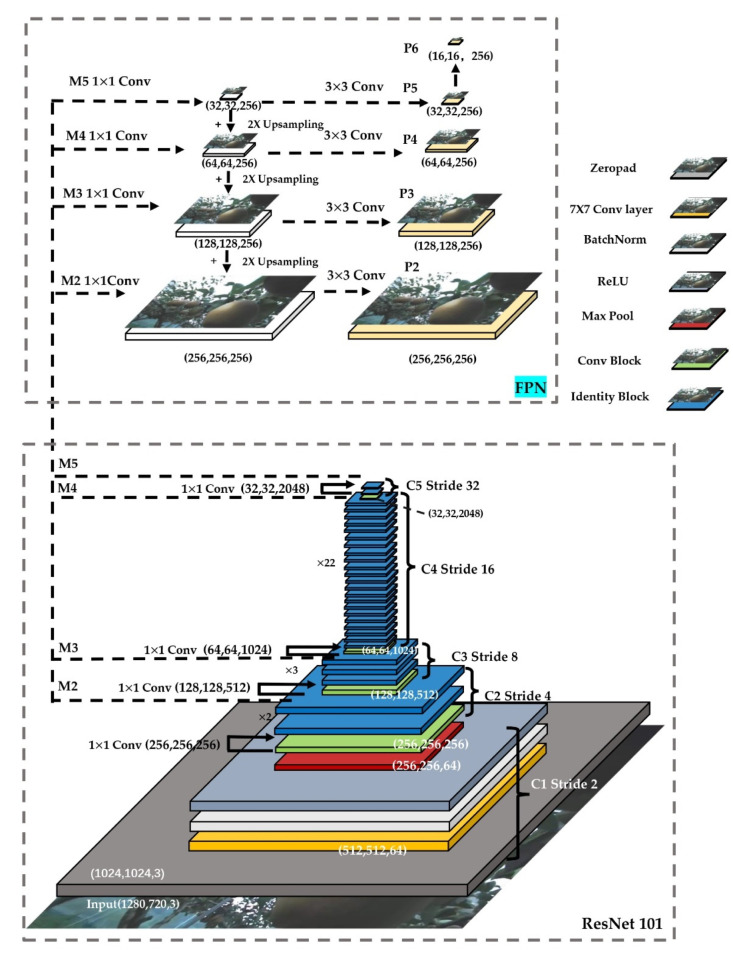
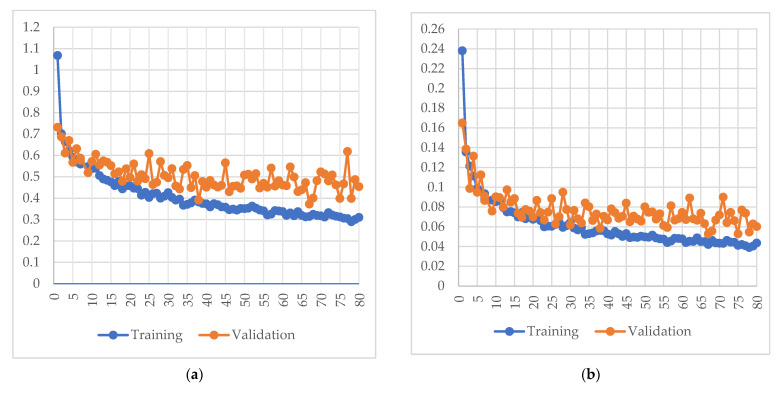
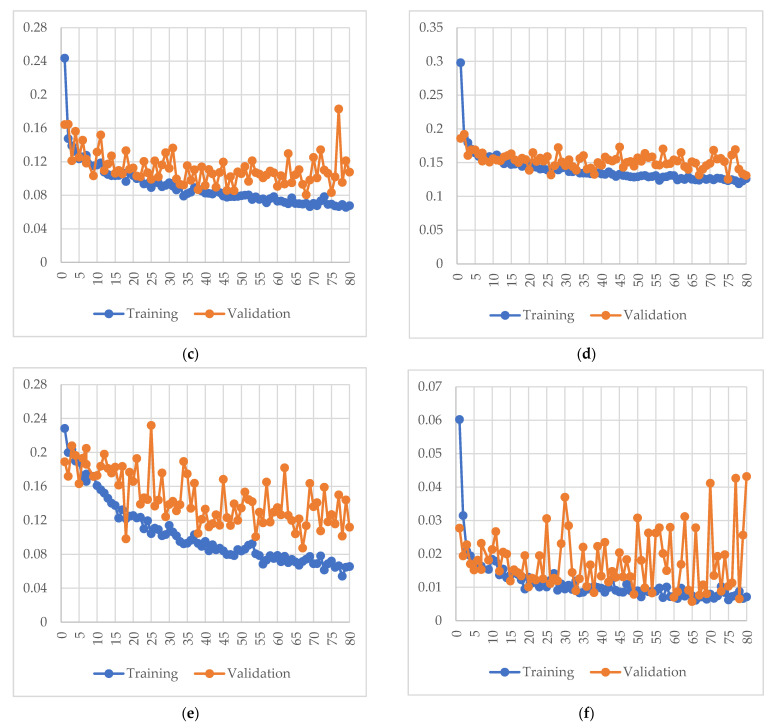
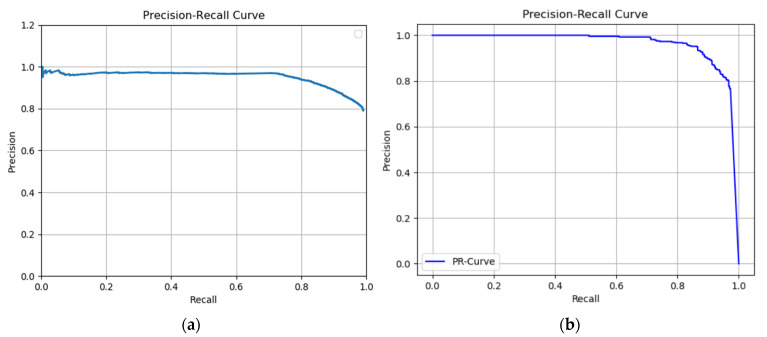
In orchard fruit picking systems for pears, the challenge is to identify the full shape of the soft fruit to avoid injuries while using robotic or automatic picking systems. Advancements in computer vision have brought the potential to train for different shapes and sizes of fruit using deep learning algorithms. In this research, a fruit recognition method for robotic systems was developed to identify pears in a complex orchard environment using a 3D stereo camera combined with Mask Region-Convolutional Neural Networks (Mask R-CNN) deep learning technology to obtain targets. This experiment used 9054 RGBA original images (3018 original images and 6036 augmented images) to create a dataset divided into a training, validation, and testing sets. Furthermore, we collected the dataset under different lighting conditions at different times which were high-light (9-10 am) and low-light (6-7 pm) conditions at JST, Tokyo Time, August 2021 (summertime) to prepare training, validation, and test datasets at a ratio of 6:3:1. All the images were taken by a 3D stereo camera which included PERFORMANCE, QUALITY, and ULTRA models. We used the PERFORMANCE model to capture images to make the datasets; the camera on the left generated depth images and the camera on the right generated the original images. In this research, we also compared the performance of different types with the R-CNN model (Mask R-CNN and Faster R-CNN); the mean Average Precisions (mAP) of Mask R-CNN and Faster R-CNN were compared in the same datasets with the same ratio. Each epoch in Mask R-CNN was set at 500 steps with total 80 epochs. And Faster R-CNN was set at 40,000 steps for training. For the recognition of pears, the Mask R-CNN, had the mAPs of 95.22% for validation set and 99.45% was observed for the testing set. On the other hand, mAPs were observed 87.9% in the validation set and 87.52% in the testing set using Faster R-CNN. The different models using the same dataset had differences in performance in gathering clustered pears and individual pear situations. Mask R-CNN outperformed Faster R-CNN when the pears are densely clustered at the complex orchard. Therefore, the 3D stereo camera-based dataset combined with the Mask R-CNN vision algorithm had high accuracy in detecting the individual pears from gathered pears in a complex orchard environment.
Keywords: 3D stereo camera; Mask R-CNN; pear detection.
Conflict of interest statement
The authors declare no conflict of interest.
Figures

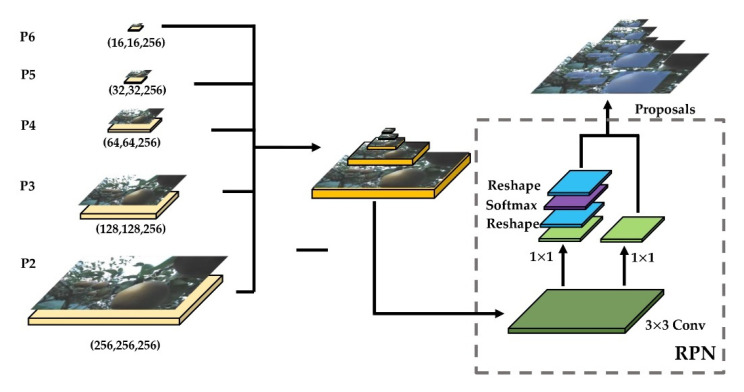
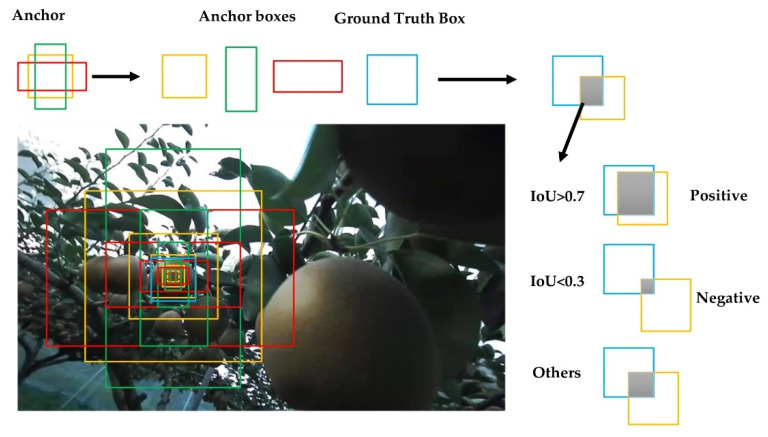
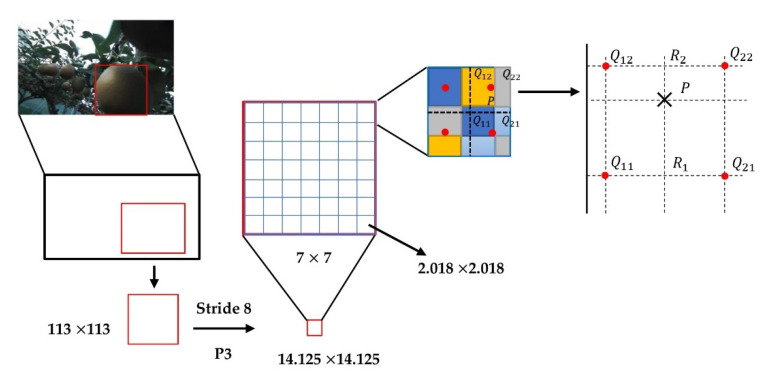
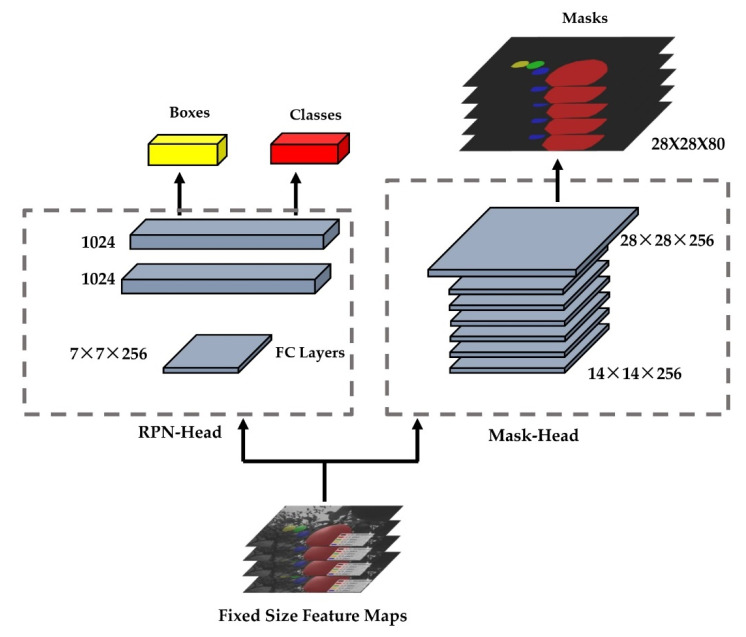





Similar articles
-
Tree Trunk Recognition in Orchard Autonomous Operations under Different Light Conditions Using a Thermal Camera and Faster R-CNN.Sensors (Basel). 2022 Mar 7;22(5):2065. doi: 10.3390/s22052065. Sensors (Basel). 2022. PMID: 35271214 Free PMC article.
-
Application of Mask R-CNN for automatic recognition of teeth and caries in cone-beam computerized tomography.BMC Oral Health. 2025 Jun 6;25(1):927. doi: 10.1186/s12903-025-06293-8. BMC Oral Health. 2025. PMID: 40481434 Free PMC article.
-
Recognition and Counting of Apples in a Dynamic State Using a 3D Camera and Deep Learning Algorithms for Robotic Harvesting Systems.Sensors (Basel). 2023 Apr 7;23(8):3810. doi: 10.3390/s23083810. Sensors (Basel). 2023. PMID: 37112151 Free PMC article.
-
A Comprehensive Review of Deep Learning in Computer Vision for Monitoring Apple Tree Growth and Fruit Production.Sensors (Basel). 2025 Apr 12;25(8):2433. doi: 10.3390/s25082433. Sensors (Basel). 2025. PMID: 40285123 Free PMC article. Review.
-
Research progress and prospect of key technologies of fruit target recognition for robotic fruit picking.Front Plant Sci. 2024 Dec 6;15:1423338. doi: 10.3389/fpls.2024.1423338. eCollection 2024. Front Plant Sci. 2024. PMID: 39711588 Free PMC article.
Cited by
-
GreenFruitDetector: Lightweight green fruit detector in orchard environment.PLoS One. 2024 Nov 14;19(11):e0312164. doi: 10.1371/journal.pone.0312164. eCollection 2024. PLoS One. 2024. PMID: 39541312 Free PMC article.
-
A novel hand-eye calibration method of picking robot based on TOF camera.Front Plant Sci. 2023 Jan 17;13:1099033. doi: 10.3389/fpls.2022.1099033. eCollection 2022. Front Plant Sci. 2023. PMID: 36733593 Free PMC article.
-
High-precision object detection network for automate pear picking.Sci Rep. 2024 Jun 28;14(1):14965. doi: 10.1038/s41598-024-65750-6. Sci Rep. 2024. PMID: 38942940 Free PMC article.
-
Intrarow Uncut Weed Detection Using You-Only-Look-Once Instance Segmentation for Orchard Plantations.Sensors (Basel). 2024 Jan 30;24(3):893. doi: 10.3390/s24030893. Sensors (Basel). 2024. PMID: 38339611 Free PMC article.
-
Development of a Deep Learning Model for the Analysis of Dorsal Root Ganglion Chromatolysis in Rat Spinal Stenosis.J Pain Res. 2024 Apr 6;17:1369-1380. doi: 10.2147/JPR.S444055. eCollection 2024. J Pain Res. 2024. PMID: 38600989 Free PMC article.
References
-
- Barua S. Understanding Coronanomics: The Economic Implications of the Coronavirus (COVID-19) Pandemic. [(accessed on 1 April 2020)]. Available online: https://ssrn.com/abstract=3566477.
-
- Schrder C. Employment in European Agriculture: Labour Costs, Flexibility and Contractual Aspects. 2014. [(accessed on 1 April 2020)]. Available online: agricultura.gencat.cat/web/.content/de_departament/de02_estadistiques_ob....
-
- Wei X., Jia K., Lan J., Li Y., Zeng Y., Wang C. Automatic method of fruit object extraction under complex agricultural background for vision system of fruit picking robot. Optik. 2004;125:5684–5689. doi: 10.1016/j.ijleo.2014.07.001. - DOI
-
- Bechar A., Vigneault C. Agricultural robots for field operations: Concepts and components. Biosyst. Eng. 2016;149:94–111. doi: 10.1016/j.biosystemseng.2016.06.014. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
