

The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression
- PMID: 35686364
- PMCID: PMC9382395
- DOI: 10.1093/jamia/ocac093
The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression
Abstract
Objective: Methods to correct class imbalance (imbalance between the frequency of outcome events and nonevents) are receiving increasing interest for developing prediction models. We examined the effect of imbalance correction on the performance of logistic regression models.
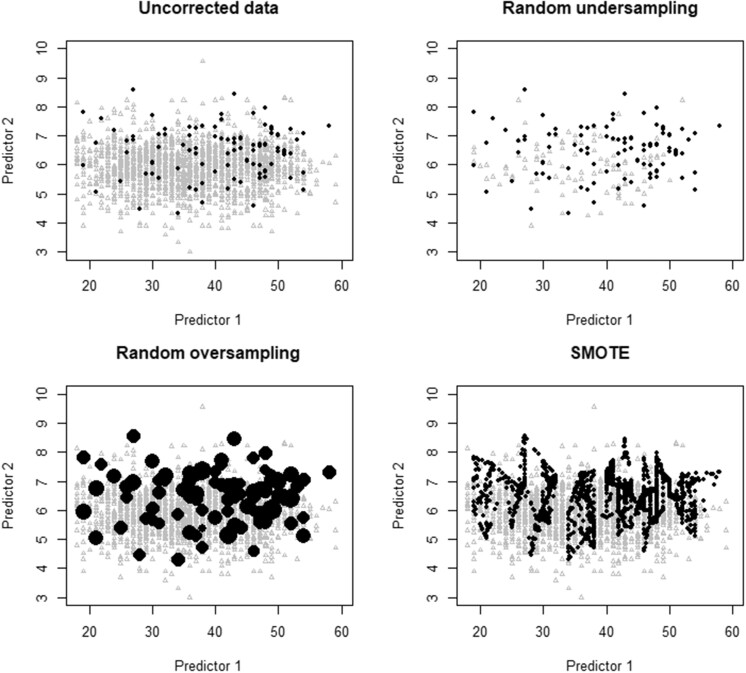
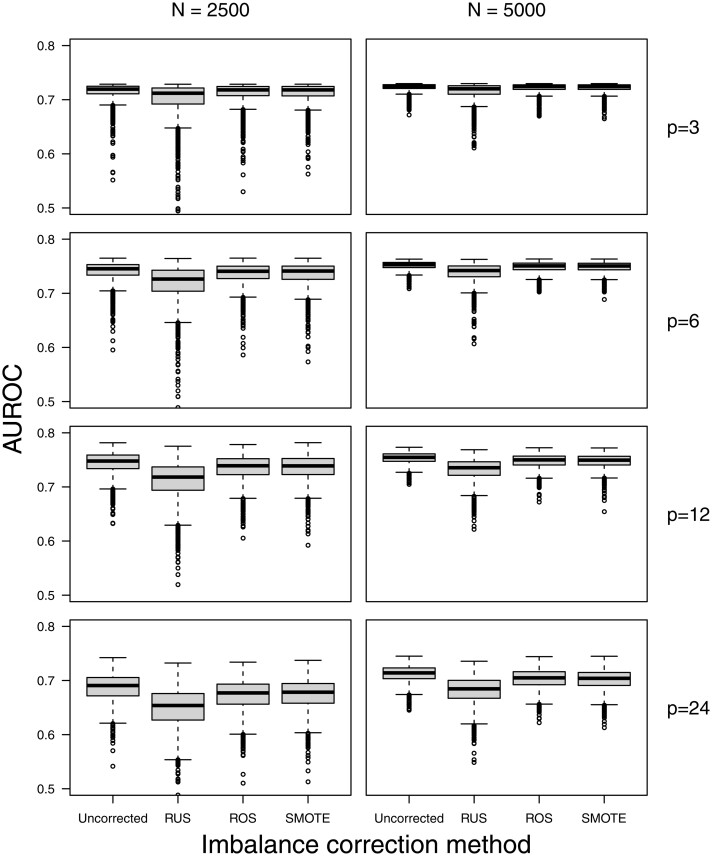
Material and methods: Prediction models were developed using standard and penalized (ridge) logistic regression under 4 methods to address class imbalance: no correction, random undersampling, random oversampling, and SMOTE. Model performance was evaluated in terms of discrimination, calibration, and classification. Using Monte Carlo simulations, we studied the impact of training set size, number of predictors, and the outcome event fraction. A case study on prediction modeling for ovarian cancer diagnosis is presented.
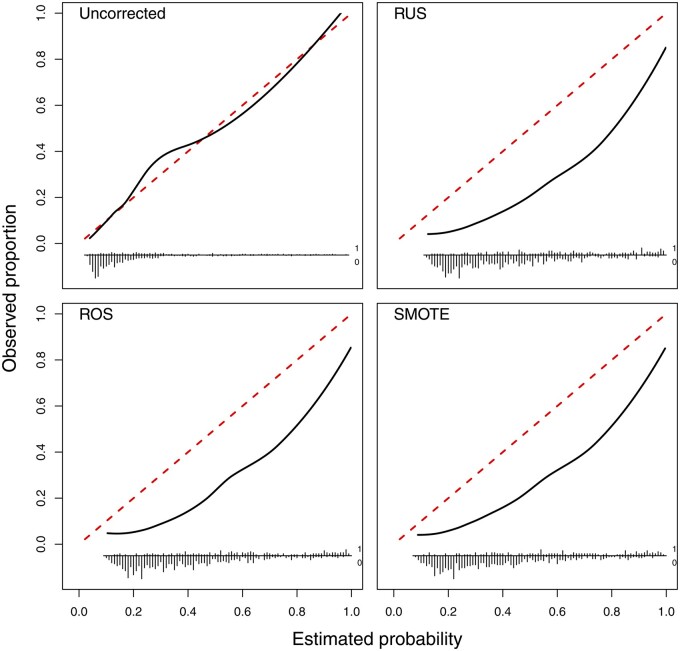
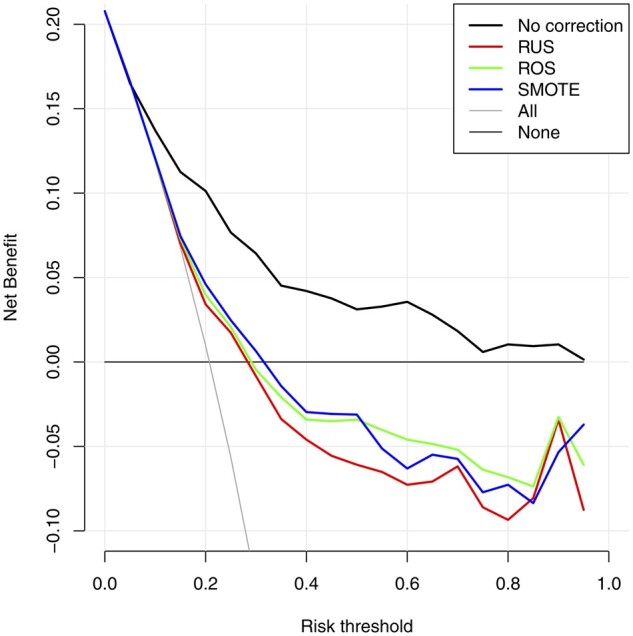
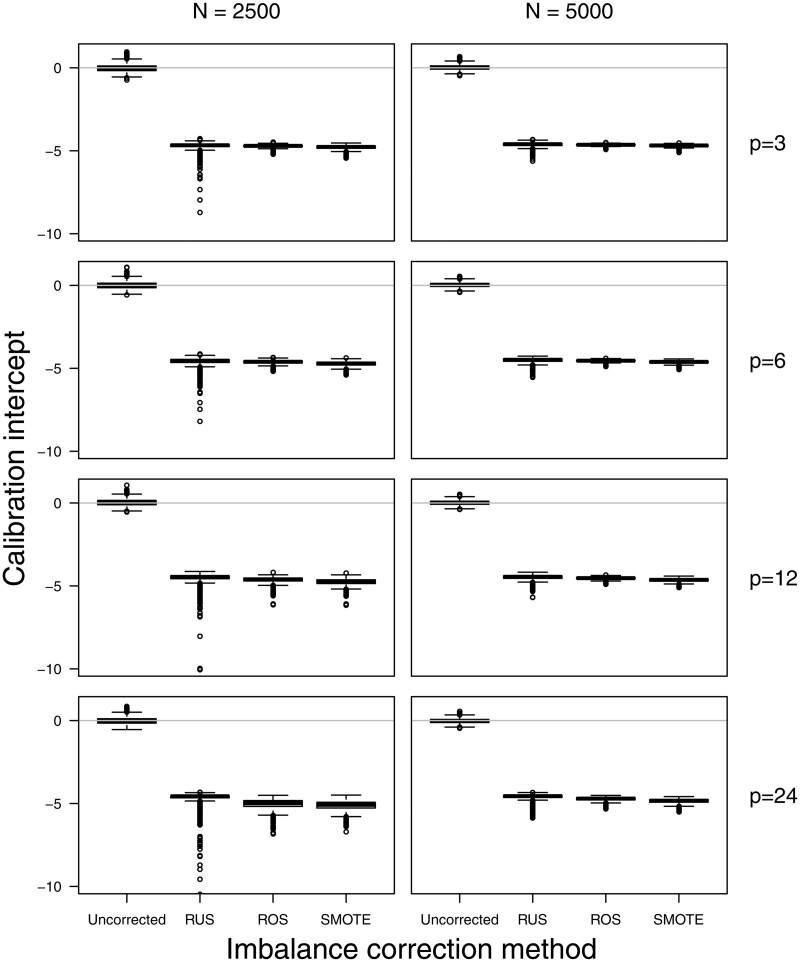
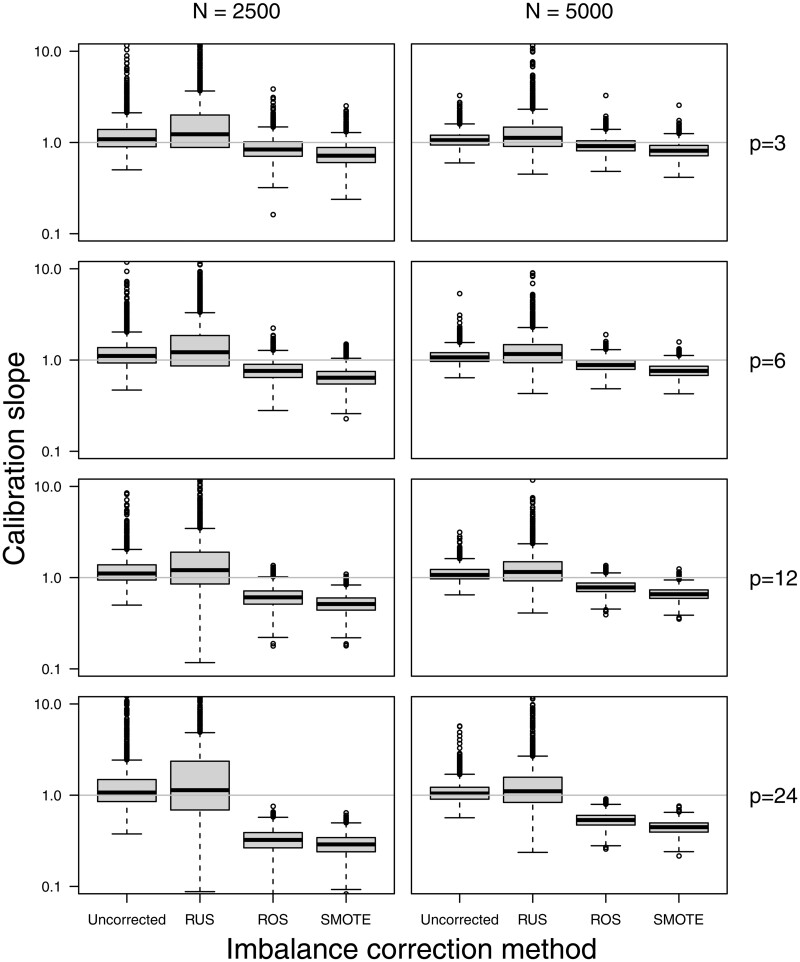
Results: The use of random undersampling, random oversampling, or SMOTE yielded poorly calibrated models: the probability to belong to the minority class was strongly overestimated. These methods did not result in higher areas under the ROC curve when compared with models developed without correction for class imbalance. Although imbalance correction improved the balance between sensitivity and specificity, similar results were obtained by shifting the probability threshold instead.
Discussion: Imbalance correction led to models with strong miscalibration without better ability to distinguish between patients with and without the outcome event. The inaccurate probability estimates reduce the clinical utility of the model, because decisions about treatment are ill-informed.
Conclusion: Outcome imbalance is not a problem in itself, imbalance correction may even worsen model performance.
Keywords: calibration; class imbalance; logistic regression; synthetic minority oversampling technique; undersampling.
© The Author(s) 2022. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures
References
-
- Megahed FM, Chen YJ, Megahed A, et al.The class imbalance problem. Nat Methods 2021; 18 (11): 1270–7. - PubMed
-
- He H, Garcia EA.. Learning from imbalanced data. IEEE Trans Knowl Data Eng 2009; 21: 1263–84.
-
- Fernández A, García S, Galar M, et al.Learning from Imbalanced Data Sets. Cham: Springer; 2018.
-
- Chawla N, Bowyer K, Hall L, et al.SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 2002; 16: 321–57.
-
- Fernández A, García S, Herrera F, et al.SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. J Artif Intell Res 2018; 61: 863–905.
