

Trusting our machines: validating machine learning models for single-molecule transport experiments
- PMID: 35686581
- PMCID: PMC9377421
- DOI: 10.1039/d1cs00884f
Trusting our machines: validating machine learning models for single-molecule transport experiments
Abstract
In this tutorial review, we will describe crucial aspects related to the application of machine learning to help users avoid the most common pitfalls. The examples we present will be based on data from the field of molecular electronics, specifically single-molecule electron transport experiments, but the concepts and problems we explore will be sufficiently general for application in other fields with similar data. In the first part of the tutorial review, we will introduce the field of single-molecule transport, and provide an overview of the most common machine learning algorithms employed. In the second part of the tutorial review, we will show, through examples grounded in single-molecule transport, that the promises of machine learning can only be fulfilled by careful application. We will end the tutorial review with a discussion of where we, as a field, could go from here.
Conflict of interest statement
There are no conflicts to declare.
Figures



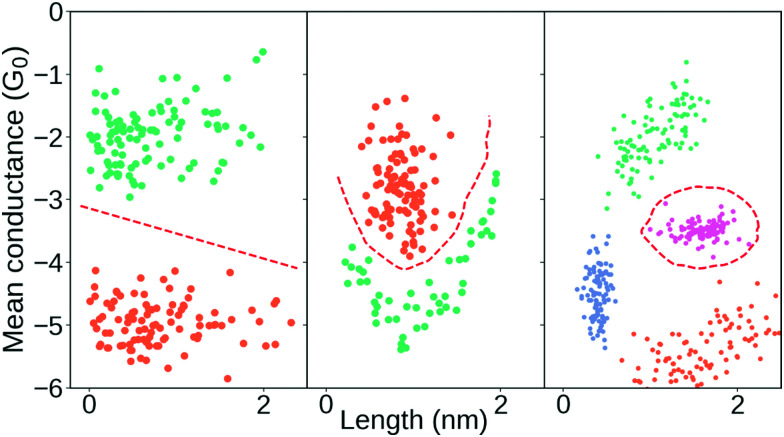






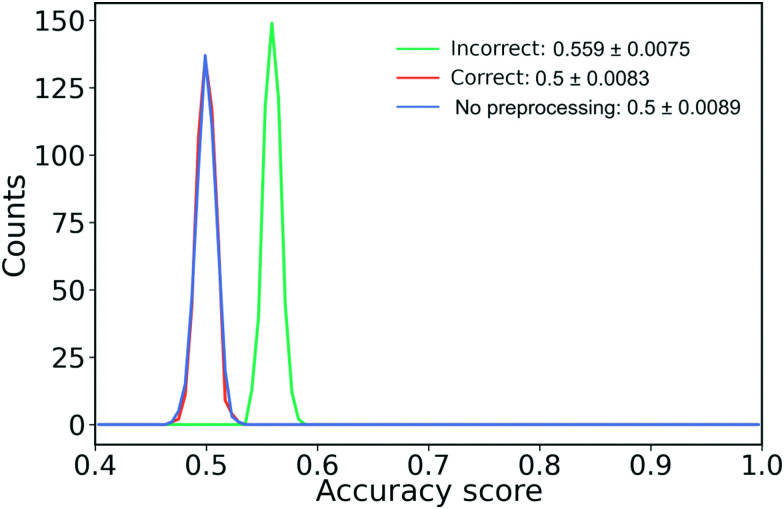
References
-
- Young T. Hazarika D. Poria S. Cambria E. IEEE Comput. Intell. Mag. 2018;13:55–75.
-
- Reed M. A. Zhou C. Muller C. J. Burgin T. P. Tour J. M. Science. 1997;278:252–254. doi: 10.1126/science.278.5336.252. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources