

Improving disaggregation models of malaria incidence by ensembling non-linear models of prevalence
- PMID: 35691633
- PMCID: PMC9205339
- DOI: 10.1016/j.sste.2020.100357
Improving disaggregation models of malaria incidence by ensembling non-linear models of prevalence
Abstract
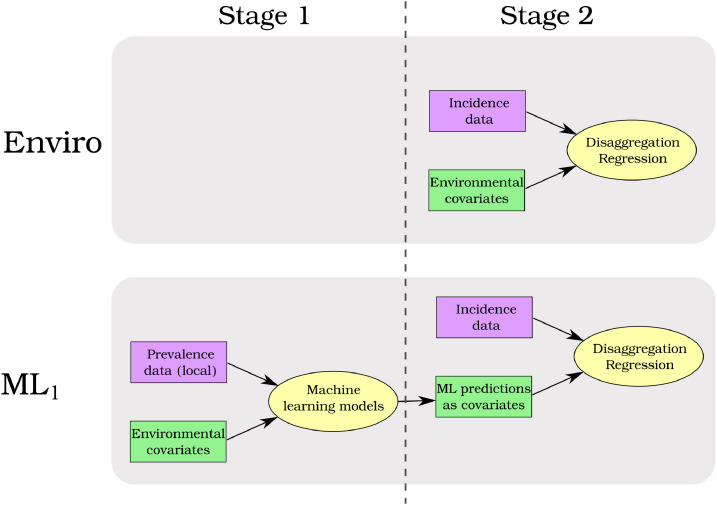
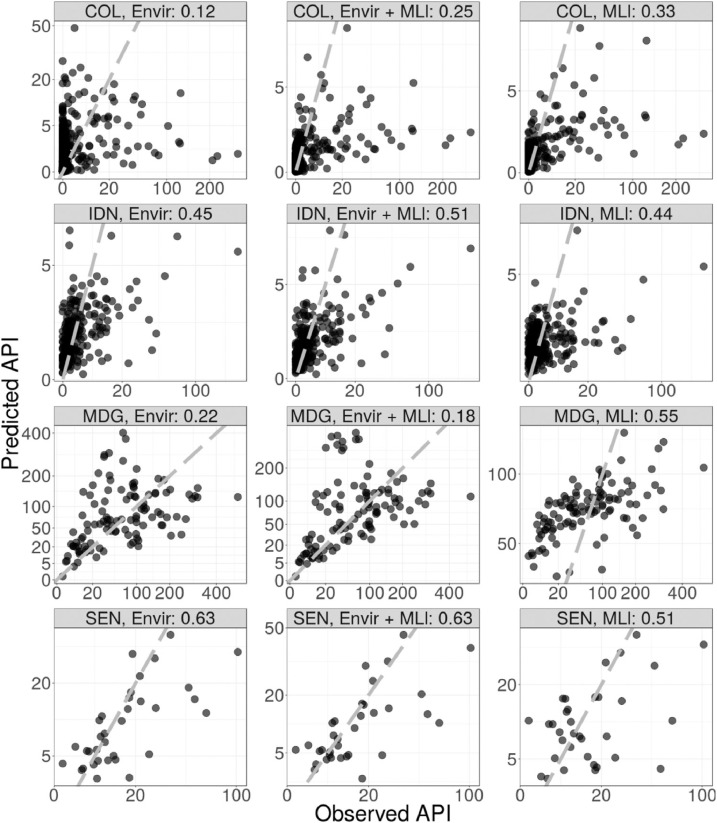
Maps of disease burden are a core tool needed for the control and elimination of malaria. Reliable routine surveillance data of malaria incidence, typically aggregated to administrative units, is becoming more widely available. Disaggregation regression is an important model framework for estimating high resolution risk maps from aggregated data. However, the aggregation of incidence over large, heterogeneous areas means that these data are underpowered for estimating complex, non-linear models. In contrast, prevalence point-surveys are directly linked to local environmental conditions but are not common in many areas of the world. Here, we train multiple non-linear, machine learning models on Plasmodium falciparum prevalence point-surveys. We then ensemble the predictions from these machine learning models with a disaggregation regression model that uses aggregated malaria incidences as response data. We find that using a disaggregation regression model to combine predictions from machine learning models improves model accuracy relative to a baseline model.
Keywords: Disaggregation regression; Spatial statistics; Stacking; Surveillance data.
Copyright © 2020 The Author(s). Published by Elsevier Ltd.. All rights reserved.
Figures


References
-
- Breiman L. Bagging predictors. Mach. Learn. 1996;24(2):123–140.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
