

PSegNet: Simultaneous Semantic and Instance Segmentation for Point Clouds of Plants
- PMID: 35693119
- PMCID: PMC9157368
- DOI: 10.34133/2022/9787643
PSegNet: Simultaneous Semantic and Instance Segmentation for Point Clouds of Plants
Abstract
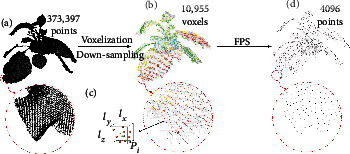
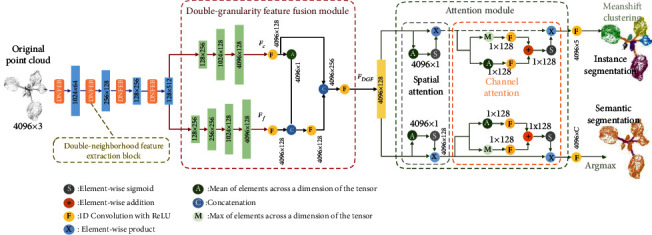
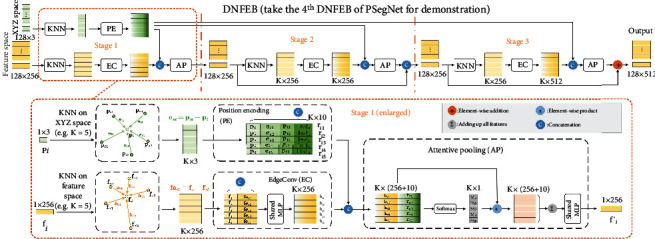
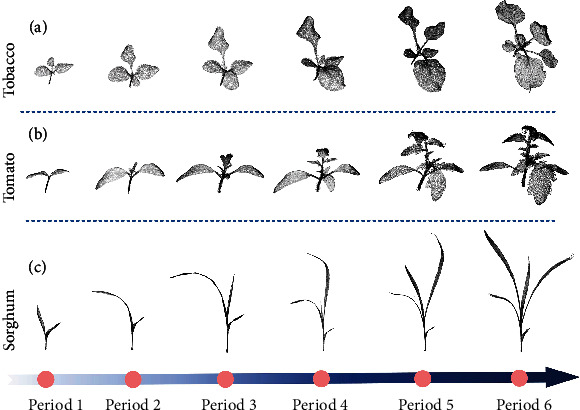
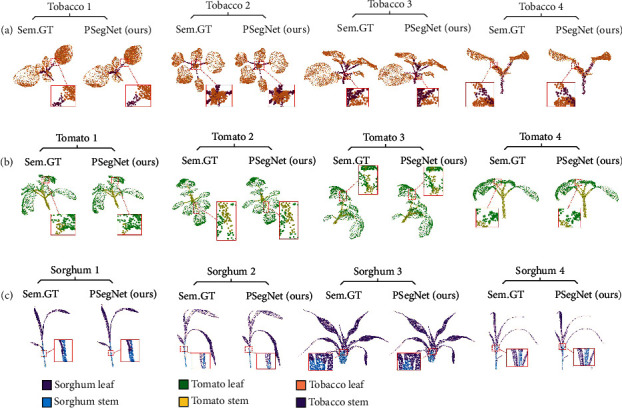
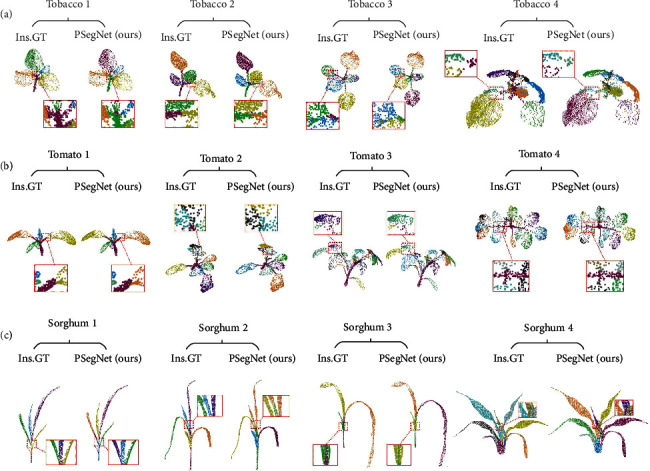
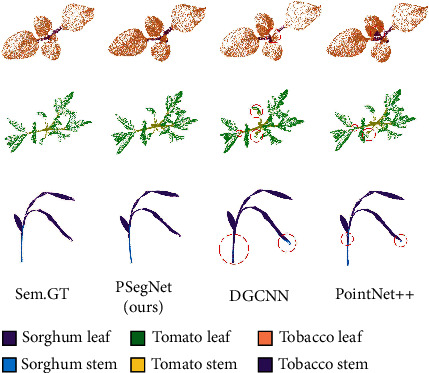
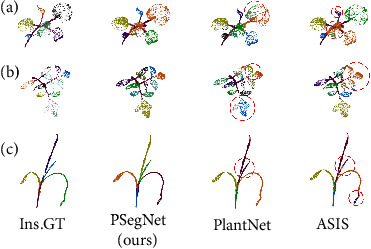
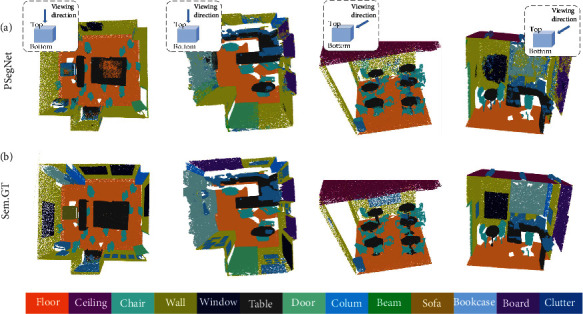
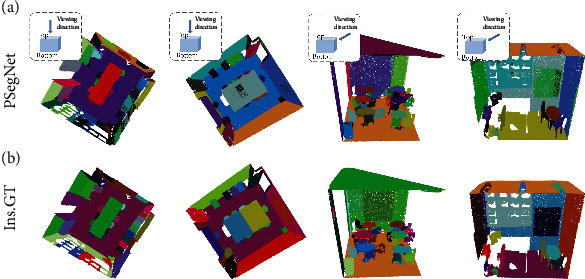
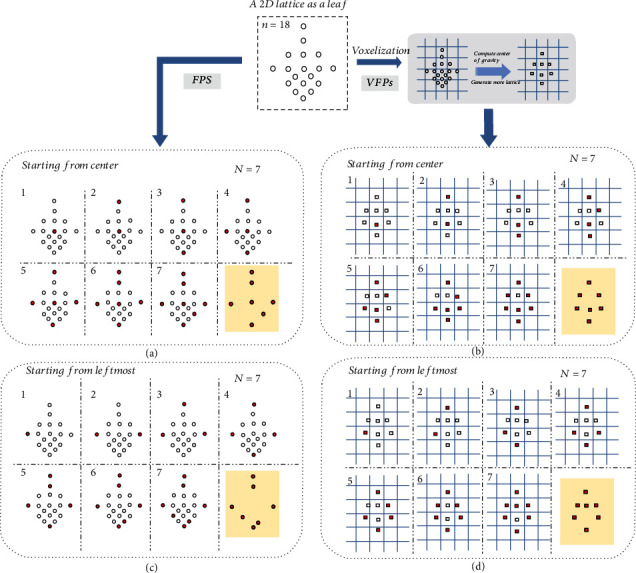
Phenotyping of plant growth improves the understanding of complex genetic traits and eventually expedites the development of modern breeding and intelligent agriculture. In phenotyping, segmentation of 3D point clouds of plant organs such as leaves and stems contributes to automatic growth monitoring and reflects the extent of stress received by the plant. In this work, we first proposed the Voxelized Farthest Point Sampling (VFPS), a novel point cloud downsampling strategy, to prepare our plant dataset for training of deep neural networks. Then, a deep learning network-PSegNet, was specially designed for segmenting point clouds of several species of plants. The effectiveness of PSegNet originates from three new modules including the Double-Neighborhood Feature Extraction Block (DNFEB), the Double-Granularity Feature Fusion Module (DGFFM), and the Attention Module (AM). After training on the plant dataset prepared with VFPS, the network can simultaneously realize the semantic segmentation and the leaf instance segmentation for three plant species. Comparing to several mainstream networks such as PointNet++, ASIS, SGPN, and PlantNet, the PSegNet obtained the best segmentation results quantitatively and qualitatively. In semantic segmentation, PSegNet achieved 95.23%, 93.85%, 94.52%, and 89.90% for the mean Prec, Rec, F1, and IoU, respectively. In instance segmentation, PSegNet achieved 88.13%, 79.28%, 83.35%, and 89.54% for the mPrec, mRec, mCov, and mWCov, respectively.
Copyright © 2022 Dawei Li et al.
Conflict of interest statement
The authors declare that there is no conflict of interest regarding the publication of this article.
Figures
References
-
- Li Z., Guo R., Li M., Chen Y., Li G. A review of computer vision technologies for plant phenotyping. Computers and Electronics in Agriculture . 2020;176, article 105672 doi: 10.1016/j.compag.2020.105672. - DOI
-
- Trivedi P. Advances in Plant Physiology . IK International Pvt Ltd; 2006.
LinkOut - more resources
Full Text Sources
