

Explaining deep reinforcement learning decisions in complex multiagent settings: towards enabling automation in air traffic flow management
- PMID: 35694685
- PMCID: PMC9169601
- DOI: 10.1007/s10489-022-03605-1
Explaining deep reinforcement learning decisions in complex multiagent settings: towards enabling automation in air traffic flow management
Abstract
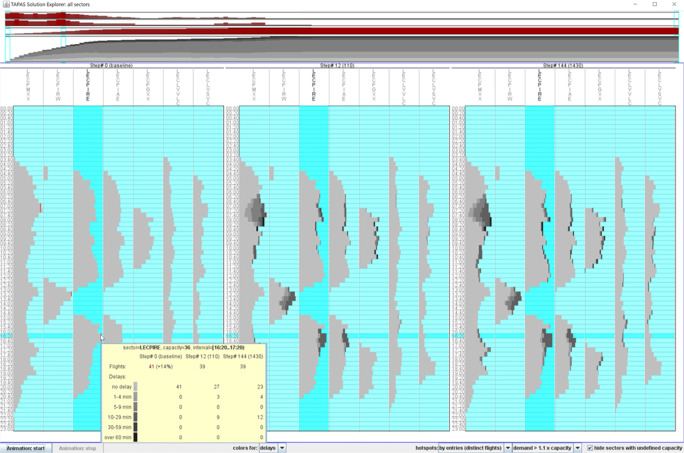
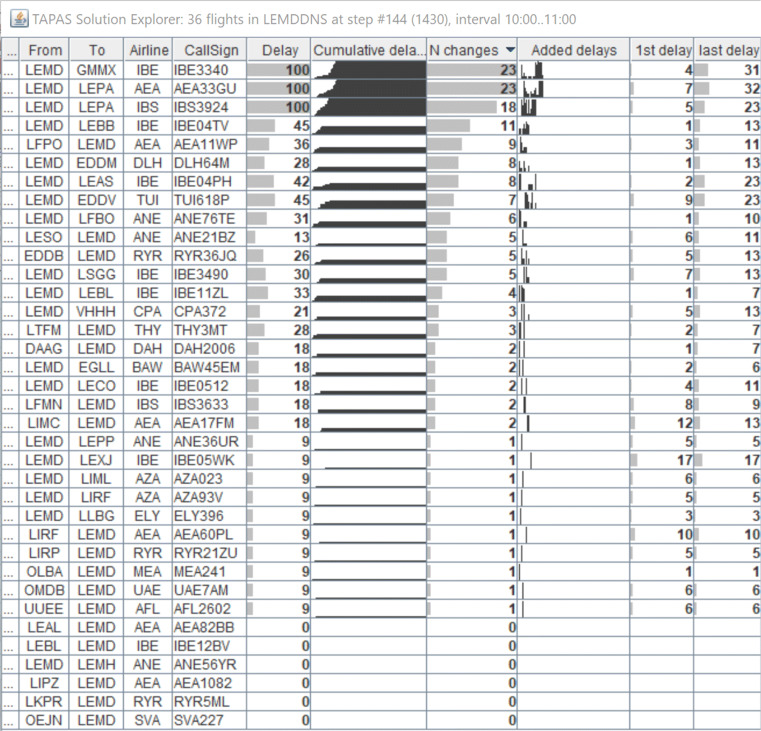
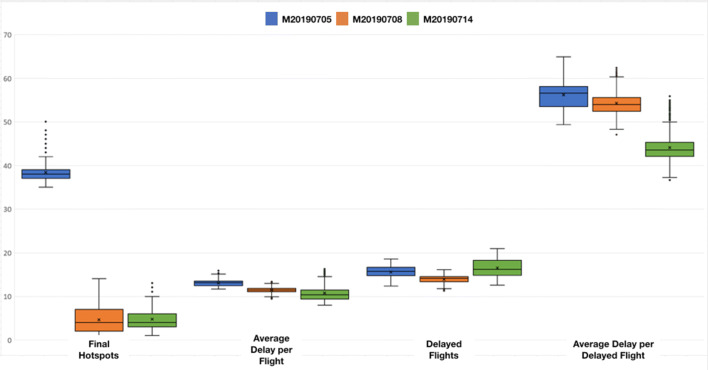
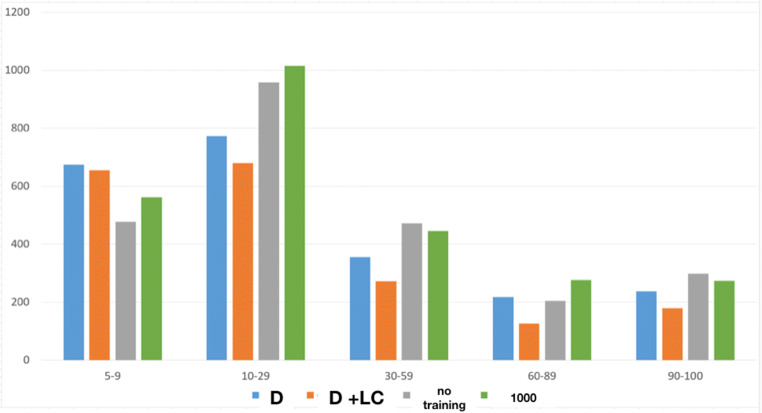
With the objective to enhance human performance and maximize engagement during the performance of tasks, we aim to advance automation for decision making in complex and large-scale multi-agent settings. Towards these goals, this paper presents a deep multi agent reinforcement learning method for resolving demand - capacity imbalances in real-world Air Traffic Management settings with thousands of agents. Agents comprising the system are able to jointly decide on the measures to be applied to resolve imbalances, while they provide explanations on their decisions: This information is rendered and explored via appropriate visual analytics tools. The paper presents how major challenges of scalability and complexity are addressed, and provides results from evaluation tests that show the abilities of models to provide high-quality solutions and high-fidelity explanations.
Keywords: Air traffic management; Explainability; Interpretability; Multi-agent deep reinforcement learning; Stochastic decision trees; Visualization.
© The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature 2022.
Figures











References
-
- Agogino AK, Tumer K. A multiagent approach to managing air traffic flow. Auton Agents Multiagent Syst. 2012;24:1–25. doi: 10.1007/s10458-010-9142-5. - DOI
-
- Bazzan ALC. Opportunities for multiagent systems and multiagent reinforcement learning in traffic control. Auton Agent Multi-Agent Syst. 2009;18:342–375. doi: 10.1007/s10458-008-9062-9. - DOI
-
- Kuyer L, Whiteson S, Bakker B, Vlassis N (2008) Multiagent reinforcement learning for urban traffic control using coordination graphs. Mach Learn Knowl Discov Database:656–671
-
- Tumer K, Agogino A (2007) Distributed agent-based air traffic flow management. International Conference on Autonomous Agents and Multiagent Systems (AAMAS ’07)
-
- Walraven E, Spaan MTJ, B.Bakker Traffic flow optimization: A reinforcement learning approach. Eng Appl Artif Intell. 2016;52:203–212. doi: 10.1016/j.engappai.2016.01.001. - DOI
LinkOut - more resources
Full Text Sources