

Impact analysis of keyword extraction using contextual word embedding
- PMID: 35721401
- PMCID: PMC9202614
- DOI: 10.7717/peerj-cs.967
Impact analysis of keyword extraction using contextual word embedding
Abstract
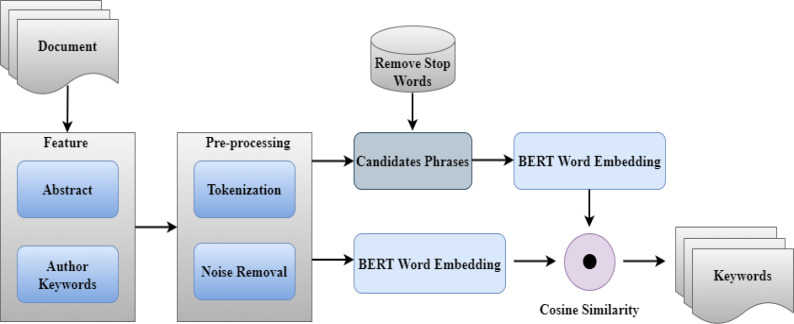
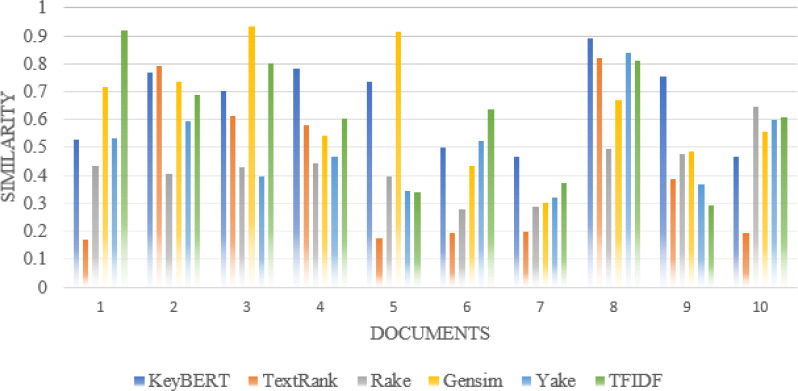
A document's keywords provide high-level descriptions of the content that summarize the document's central themes, concepts, ideas, or arguments. These descriptive phrases make it easier for algorithms to find relevant information quickly and efficiently. It plays a vital role in document processing, such as indexing, classification, clustering, and summarization. Traditional keyword extraction approaches rely on statistical distributions of key terms in a document for the most part. According to contemporary technological breakthroughs, contextual information is critical in deciding the semantics of the work at hand. Similarly, context-based features may be beneficial in the job of keyword extraction. For example, simply indicating the previous or next word of the phrase of interest might be used to describe the context of a phrase. This research presents several experiments to validate that context-based key extraction is significant compared to traditional methods. Additionally, the KeyBERT proposed methodology also results in improved results. The proposed work relies on identifying a group of important words or phrases from the document's content that can reflect the authors' main ideas, concepts, or arguments. It also uses contextual word embedding to extract keywords. Finally, the findings are compared to those obtained using older approaches such as Text Rank, Rake, Gensim, Yake, and TF-IDF. The Journals of Universal Computer (JUCS) dataset was employed in our research. Only data from abstracts were used to produce keywords for the research article, and the KeyBERT model outperformed traditional approaches in producing similar keywords to the authors' provided keywords. The average similarity of our approach with author-assigned keywords is 51%.
Keywords: Contextual Word Embedding; Keyword extraction; TF-IDF; Text Rank; Yake.
©2022 Khan et al.
Conflict of interest statement
The authors declare there are no competing interests.
Figures






References
-
- Aljuaid H, Iftikhar R, Ahmad S, Asif M, Afzal MT. Important citation identification using sentiment analysis of in-text citations. Telematics and Informatics. 2021;56:101492. doi: 10.1016/j.tele.2020.101492. - DOI
-
- Alzaidy R, Caragea C, Lee Giles C. Bi-LSTM-CRF sequence labeling for keyphrase extraction from scholarly documents. The world wide web conference; 2019. pp. 2551–2557.
-
- Basaldella M, Antolli E, Serra G, Tasso C. Bidirectional lstm recurrent neural network for keyphrase extraction. Italian research conference on digital libraries; Cham. 2018. pp. 180–187.
-
- Bennani-Smires K, Musat C, Hossmann A, Baeriswyl M, Jaggi M. Simple unsupervised keyphrase extraction using sentence embeddings. 2018. 1801.04470
-
- Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. Journal of Machine Learning Research. 2003;3(Jan):993–1022.
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous