

Bilinear pooling in video-QA: empirical challenges and motivational drift from neurological parallels
- PMID: 35721409
- PMCID: PMC9202627
- DOI: 10.7717/peerj-cs.974
Bilinear pooling in video-QA: empirical challenges and motivational drift from neurological parallels
Abstract
Bilinear pooling (BLP) refers to a family of operations recently developed for fusing features from different modalities predominantly for visual question answering (VQA) models. Successive BLP techniques have yielded higher performance with lower computational expense, yet at the same time they have drifted further from the original motivational justification of bilinear models, instead becoming empirically motivated by task performance. Furthermore, despite significant success in text-image fusion in VQA, BLP has not yet gained such notoriety in video question answering (video-QA). Though BLP methods have continued to perform well on video tasks when fusing vision and non-textual features, BLP has recently been overshadowed by other vision and textual feature fusion techniques in video-QA. We aim to add a new perspective to the empirical and motivational drift in BLP. We take a step back and discuss the motivational origins of BLP, highlighting the often-overlooked parallels to neurological theories (Dual Coding Theory and The Two-Stream Model of Vision). We seek to carefully and experimentally ascertain the empirical strengths and limitations of BLP as a multimodal text-vision fusion technique in video-QA using two models (TVQA baseline and heterogeneous-memory-enchanced 'HME' model) and four datasets (TVQA, TGif-QA, MSVD-QA, and EgoVQA). We examine the impact of both simply replacing feature concatenation in the existing models with BLP, and a modified version of the TVQA baseline to accommodate BLP that we name the 'dual-stream' model. We find that our relatively simple integration of BLP does not increase, and mostly harms, performance on these video-QA benchmarks. Using our insights on recent work in BLP for video-QA results and recently proposed theoretical multimodal fusion taxonomies, we offer insight into why BLP-driven performance gain for video-QA benchmarks may be more difficult to achieve than in earlier VQA models. We share our perspective on, and suggest solutions for, the key issues we identify with BLP techniques for multimodal fusion in video-QA. We look beyond the empirical justification of BLP techniques and propose both alternatives and improvements to multimodal fusion by drawing neurological inspiration from Dual Coding Theory and the Two-Stream Model of Vision. We qualitatively highlight the potential for neurological inspirations in video-QA by identifying the relative abundance of psycholinguistically 'concrete' words in the vocabularies for each of the text components (e.g., questions and answers) of the four video-QA datasets we experiment with.
Keywords: Bilinear pooling; Deep-CCA; Dual coding theory; Ego-VQA; MSVD-QA; Multimodal fusion; TGif-QA; TVQA; Two-stream model of vision; Video question answering.
©2022 Winterbottom et al.
Conflict of interest statement
Alistair McLean is employed at Carbon AI, Middlesbrough.
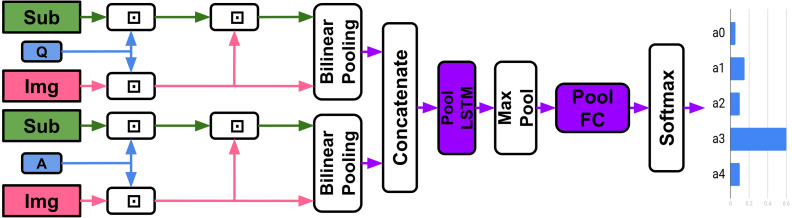
Figures











References
-
- Akaho S. A kernel method for canonical correlation analysis. Proceedings of the international meeting of the psychometric society (IMPS 2001); Osaka, volume 4; 2001. - DOI
-
- Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L. Bottom-up and top-down attention for image captioning and visual question answering. 2018 IEEE/CVF conference on computer vision and pattern recognition. 2018:6077–6086. doi: 10.48550/ARXIV.1707.07998. - DOI
-
- Andrew G, Arora R, Bilmes JA, Livescu K. Deep canonical correlation analysis. Proceedings of the 30th International Conference on Machine Learning, PMLR. 2013;28(3):1247–1255.
-
- Begg I. Recall of meaningful phrases. Journal of Verbal Learning and Verbal Behavior. 1972;11(4):431–439. doi: 10.1016/S0022-5371(72)80024-0. - DOI
LinkOut - more resources
Full Text Sources