

Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention-A Survey
- PMID: 35746103
- PMCID: PMC9228438
- DOI: 10.3390/s22124324
Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention-A Survey
Abstract
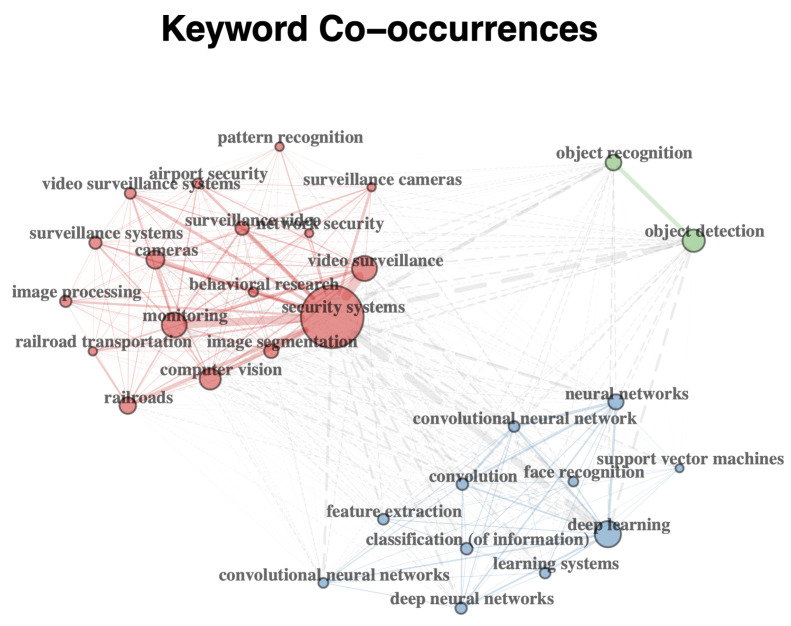
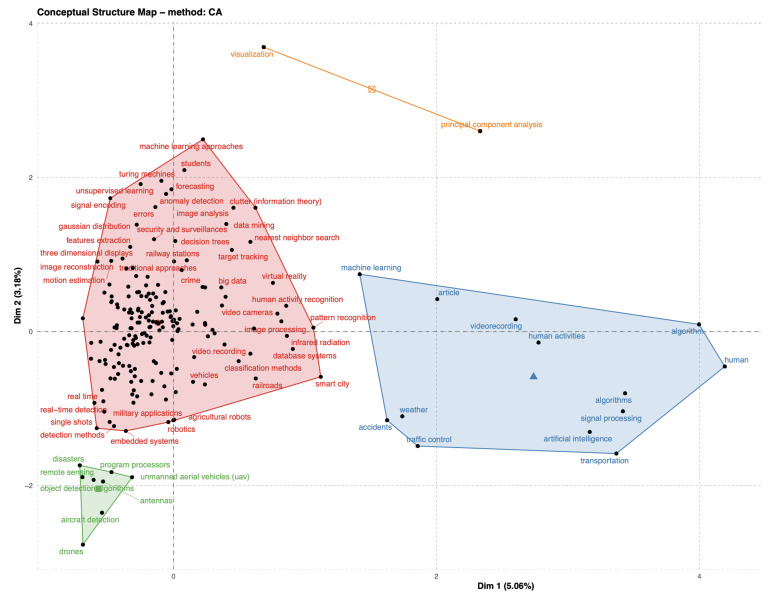
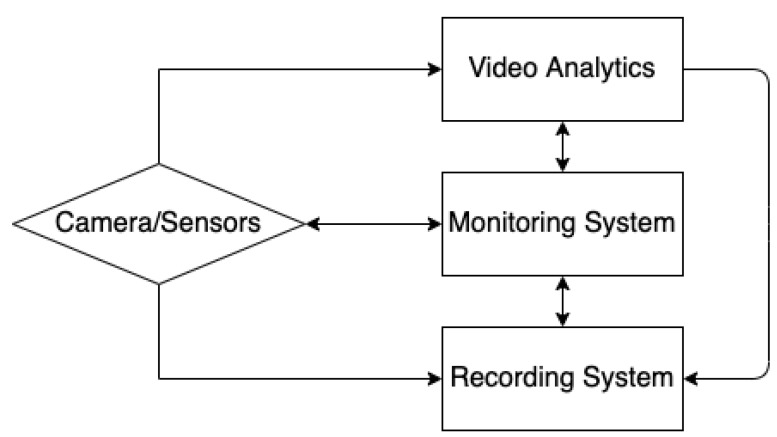
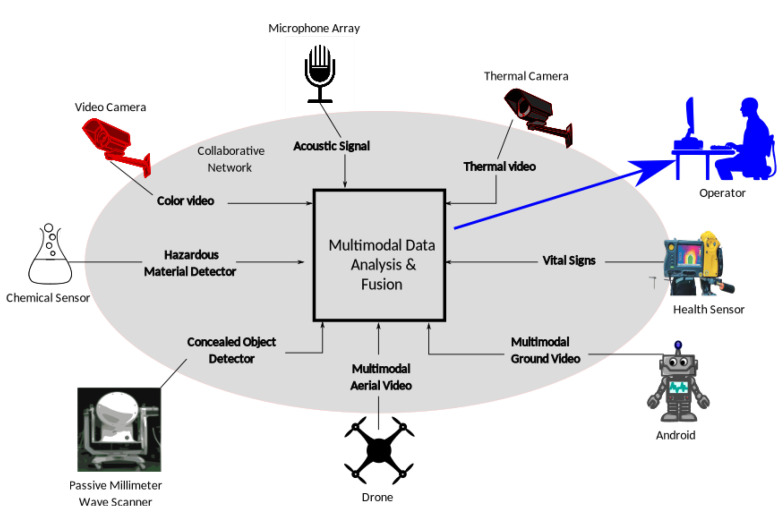
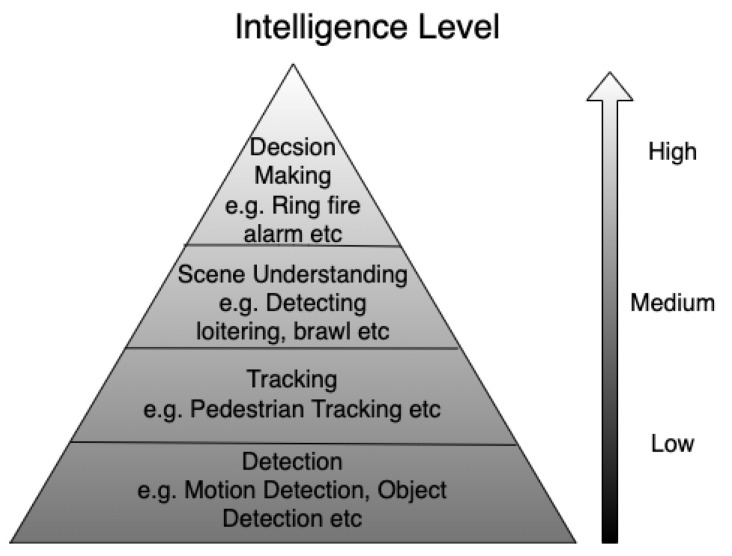
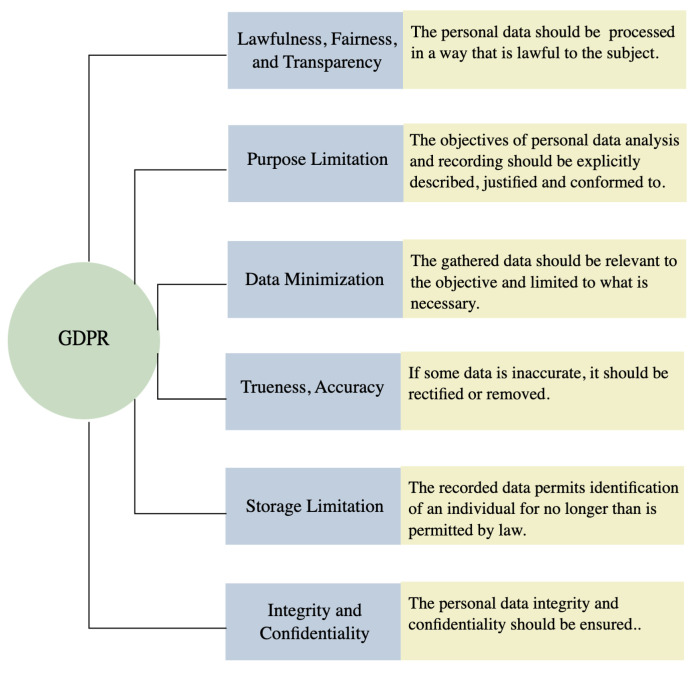
Railway networks systems are by design open and accessible to people, but this presents challenges in the prevention of events such as terrorism, trespass, and suicide fatalities. With the rapid advancement of machine learning, numerous computer vision methods have been developed in closed-circuit television (CCTV) surveillance systems for the purposes of managing public spaces. These methods are built based on multiple types of sensors and are designed to automatically detect static objects and unexpected events, monitor people, and prevent potential dangers. This survey focuses on recently developed CCTV surveillance methods for rail networks, discusses the challenges they face, their advantages and disadvantages and a vision for future railway surveillance systems. State-of-the-art methods for object detection and behaviour recognition applied to rail network surveillance systems are introduced, and the ethics of handling personal data and the use of automated systems are also considered.
Keywords: computer vision; image and video analytics; machine learning; rail network systems; sensors; surveillance; video anomaly detection.
Conflict of interest statement
The authors declare no conflict of interest.
Figures


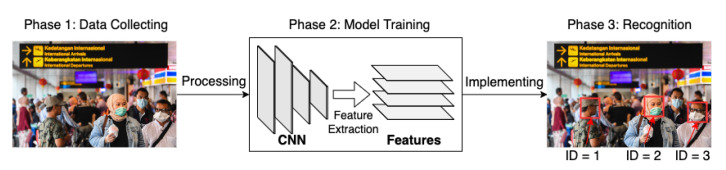
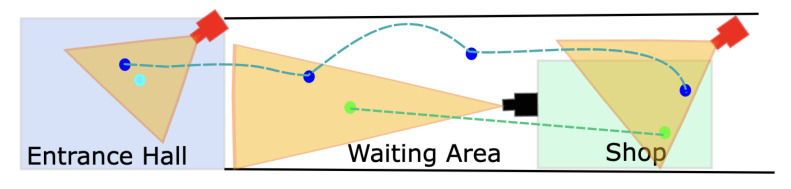
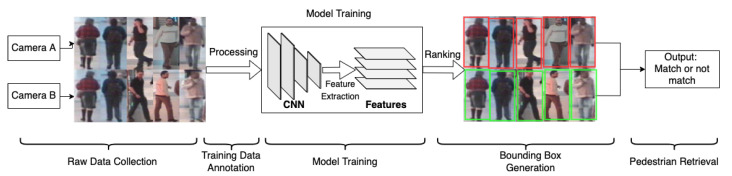
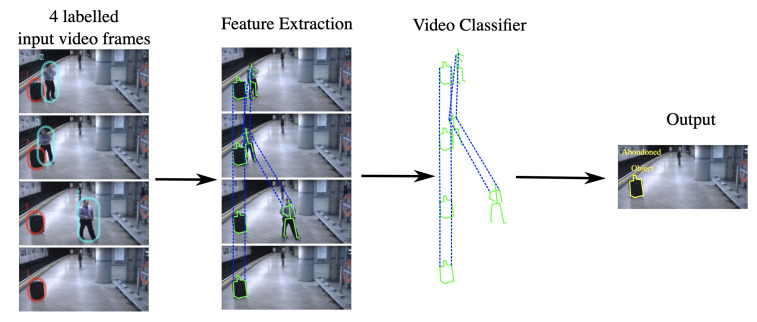
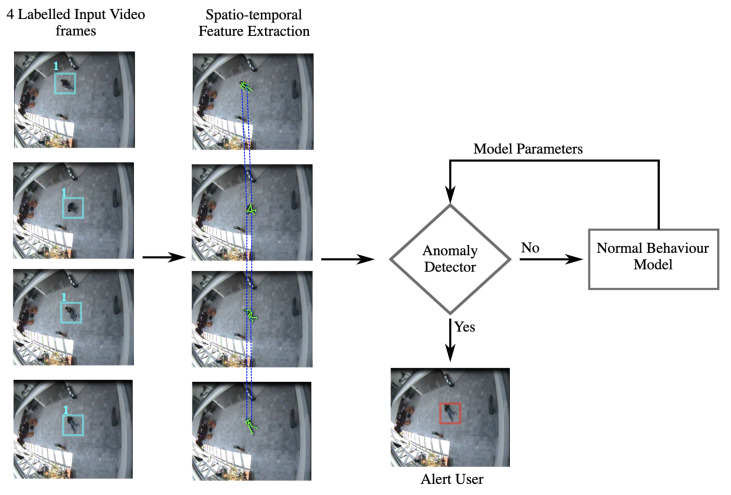
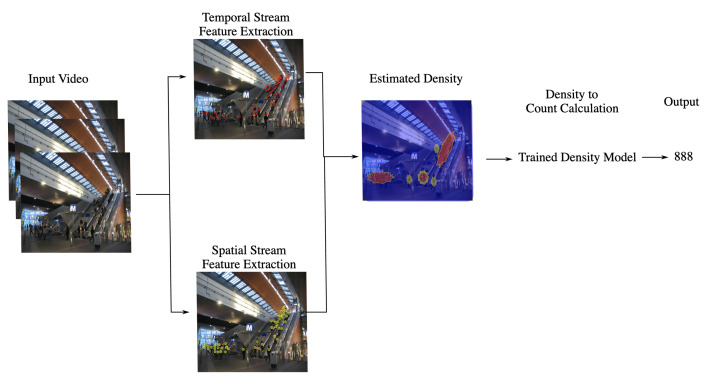
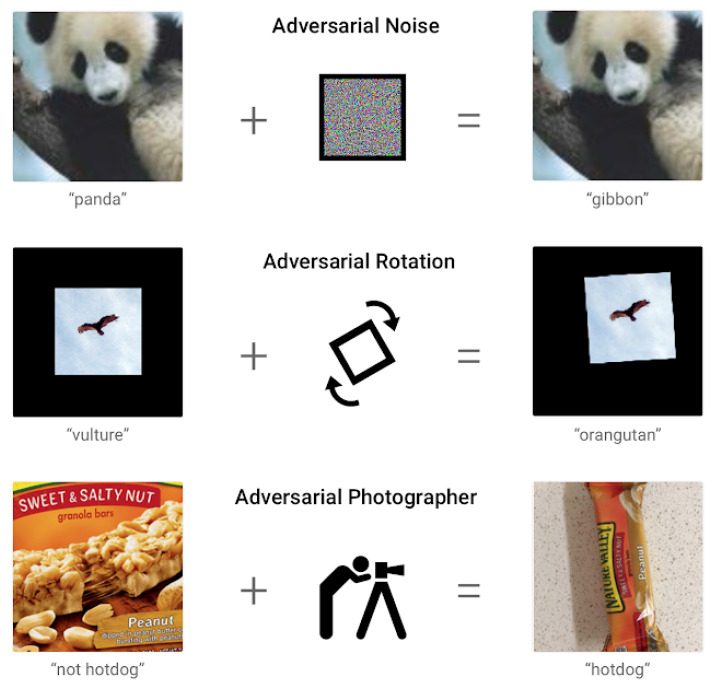

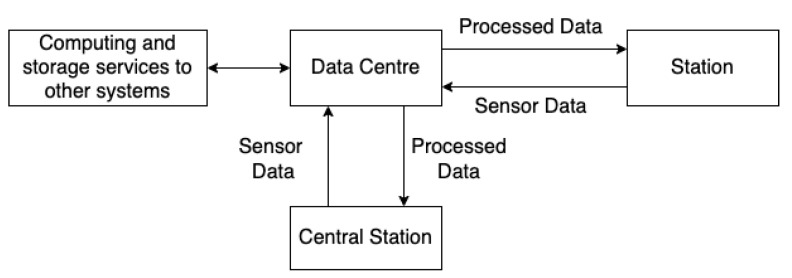
References
-
- Coaffee J., Moore C., Fletcher D., Bosher L. Resilient design for community safety and terror-resistant cities; Proceedings of the Institution of Civil Engineers-Municipal Engineer; London, UK. 1 June 2008; London, UK: Thomas Telford Ltd.; 2015. pp. 103–110.
-
- Media Guidelines for Reporting Suicide. 2019. [(accessed on 7 April 2022)]. Available online: https://media.samaritans.org/documents/Media_guidelines_-_Rail_suicides_....
-
- Suicide Prevention on the Railway—Network Rail. 2021. [(accessed on 7 April 2022)]. Available online: https://www.networkrail.co.uk/communities/safety-in-the-community/suicid...
-
- Kawamura A., Yoshimitsu Y., Kajitani K., Naito T., Fujimura K., Kamijo S. Smart camera network system for use in railway stations; Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics; Anchorage, AL, USA. 9–12 October 2011; pp. 85–90.
-
- Li Y., Qin Y., Xie Z., Cao Z., Jia L., Yu Z., Zheng J., Zhang E. Efficient SSD: A Real-Time Intrusion Object Detection Algorithm for Railway Surveillance; Proceedings of the 2020 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC); Beijing, China. 5–7 August 2020; pp. 391–395.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
