

High-throughput total RNA sequencing in single cells using VASA-seq
- PMID: 35760914
- PMCID: PMC9750877
- DOI: 10.1038/s41587-022-01361-8
High-throughput total RNA sequencing in single cells using VASA-seq
Abstract
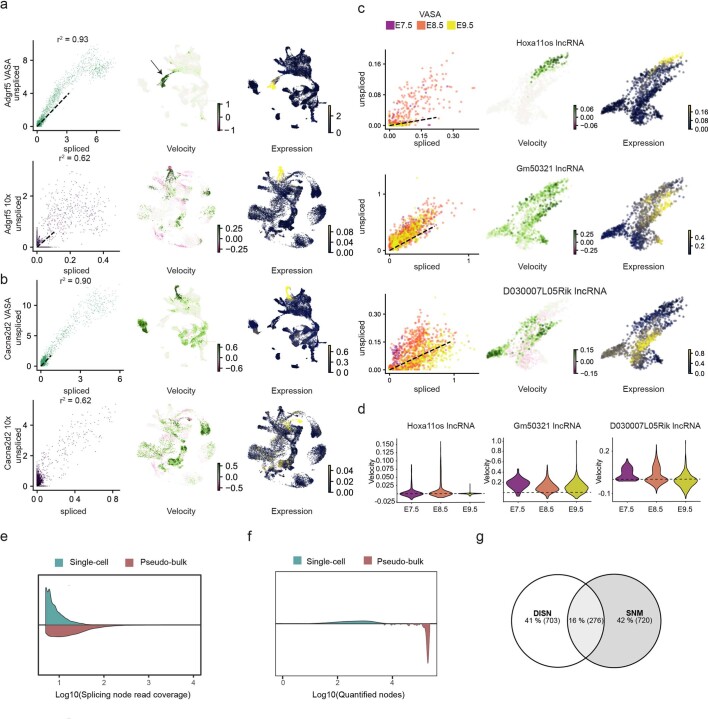
Most methods for single-cell transcriptome sequencing amplify the termini of polyadenylated transcripts, capturing only a small fraction of the total cellular transcriptome. This precludes the detection of many long non-coding, short non-coding and non-polyadenylated protein-coding transcripts and hinders alternative splicing analysis. We, therefore, developed VASA-seq to detect the total transcriptome in single cells, which is enabled by fragmenting and tailing all RNA molecules subsequent to cell lysis. The method is compatible with both plate-based formats and droplet microfluidics. We applied VASA-seq to more than 30,000 single cells in the developing mouse embryo during gastrulation and early organogenesis. Analyzing the dynamics of the total single-cell transcriptome, we discovered cell type markers, many based on non-coding RNA, and performed in vivo cell cycle analysis via detection of non-polyadenylated histone genes. RNA velocity characterization was improved, accurately retracing blood maturation trajectories. Moreover, our VASA-seq data provide a comprehensive analysis of alternative splicing during mammalian development, which highlighted substantial rearrangements during blood development and heart morphogenesis.
© 2022. The Author(s).
Conflict of interest statement
F.S., A.v.O., J.D.J., T.S.K. and F.H. are inventors on patent applications submitted by the Stichting Oncode Institute on behalf of Koninklijke Nederlandse Akademie Van Wetenschappen and the University of Cambridge (via its technology transfer office, Cambridge Enterprise). A.v.O. is a member of the advisory board of Single-Cell Discoveries.
Figures











Comment in
-
Towards a full picture of the total transcriptome.Nat Methods. 2022 Aug;19(8):922. doi: 10.1038/s41592-022-01581-5. Nat Methods. 2022. PMID: 35927479 No abstract available.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
