

Pretrained Transformer Language Models Versus Pretrained Word Embeddings for the Detection of Accurate Health Information on Arabic Social Media: Comparative Study
- PMID: 35767322
- PMCID: PMC9280463
- DOI: 10.2196/34834
Pretrained Transformer Language Models Versus Pretrained Word Embeddings for the Detection of Accurate Health Information on Arabic Social Media: Comparative Study
Abstract
Background: In recent years, social media has become a major channel for health-related information in Saudi Arabia. Prior health informatics studies have suggested that a large proportion of health-related posts on social media are inaccurate. Given the subject matter and the scale of dissemination of such information, it is important to be able to automatically discriminate between accurate and inaccurate health-related posts in Arabic.
Objective: The first aim of this study is to generate a data set of generic health-related tweets in Arabic, labeled as either accurate or inaccurate health information. The second aim is to leverage this data set to train a state-of-the-art deep learning model for detecting the accuracy of health-related tweets in Arabic. In particular, this study aims to train and compare the performance of multiple deep learning models that use pretrained word embeddings and transformer language models.
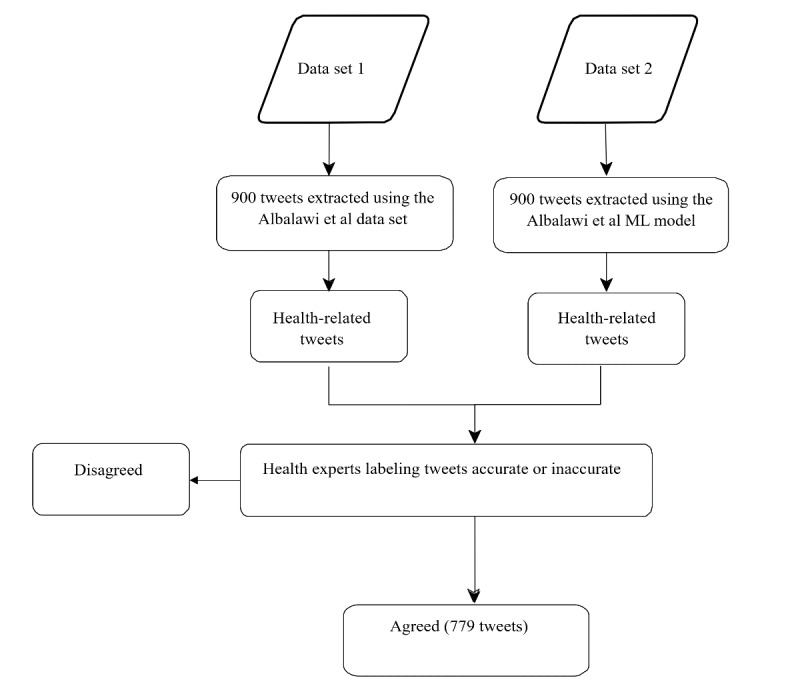
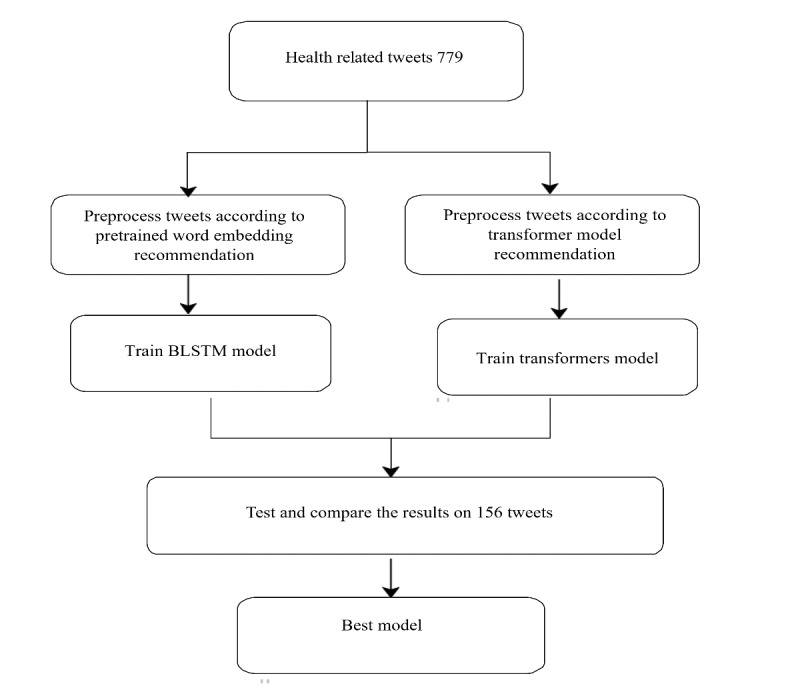
Methods: We used 900 health-related tweets from a previously published data set extracted between July 15, 2019, and August 31, 2019. Furthermore, we applied a pretrained model to extract an additional 900 health-related tweets from a second data set collected specifically for this study between March 1, 2019, and April 15, 2019. The 1800 tweets were labeled by 2 physicians as accurate, inaccurate, or unsure. The physicians agreed on 43.3% (779/1800) of tweets, which were thus labeled as accurate or inaccurate. A total of 9 variations of the pretrained transformer language models were then trained and validated on 79.9% (623/779 tweets) of the data set and tested on 20% (156/779 tweets) of the data set. For comparison, we also trained a bidirectional long short-term memory model with 7 different pretrained word embeddings as the input layer on the same data set. The models were compared in terms of their accuracy, precision, recall, F1 score, and macroaverage of the F1 score.
Results: We constructed a data set of labeled tweets, 38% (296/779) of which were labeled as inaccurate health information, and 62% (483/779) of which were labeled as accurate health information. We suggest that this was highly efficacious as we did not include any tweets in which the physician annotators were unsure or in disagreement. Among the investigated deep learning models, the Transformer-based Model for Arabic Language Understanding version 0.2 (AraBERTv0.2)-large model was the most accurate, with an F1 score of 87%, followed by AraBERT version 2-large and AraBERTv0.2-base.
Conclusions: Our results indicate that the pretrained language model AraBERTv0.2 is the best model for classifying tweets as carrying either inaccurate or accurate health information. Future studies should consider applying ensemble learning to combine the best models as it may produce better results.
Keywords: BERT; bidirectional encoder representations from transformers; deep learning; health informatics; health information; infodemiology; language model; machine learning; misinformation; pretrained language models; social media; tweets.
©Yahya Albalawi, Nikola S Nikolov, Jim Buckley. Originally published in JMIR Formative Research (https://formative.jmir.org), 29.06.2022.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
Similar articles
-
Social Media Monitoring of the COVID-19 Pandemic and Influenza Epidemic With Adaptation for Informal Language in Arabic Twitter Data: Qualitative Study.JMIR Med Inform. 2021 Sep 17;9(9):e27670. doi: 10.2196/27670. JMIR Med Inform. 2021. PMID: 34346892 Free PMC article.
-
Comparison of pretrained transformer-based models for influenza and COVID-19 detection using social media text data in Saskatchewan, Canada.Front Digit Health. 2023 Jun 28;5:1203874. doi: 10.3389/fdgth.2023.1203874. eCollection 2023. Front Digit Health. 2023. PMID: 37448834 Free PMC article.
-
Investigating the impact of pre-processing techniques and pre-trained word embeddings in detecting Arabic health information on social media.J Big Data. 2021;8(1):95. doi: 10.1186/s40537-021-00488-w. Epub 2021 Jul 2. J Big Data. 2021. PMID: 34249602 Free PMC article.
-
AMMU: A survey of transformer-based biomedical pretrained language models.J Biomed Inform. 2022 Feb;126:103982. doi: 10.1016/j.jbi.2021.103982. Epub 2021 Dec 31. J Biomed Inform. 2022. PMID: 34974190 Review.
-
Evaluation of a prototype machine learning tool to semi-automate data extraction for systematic literature reviews.Syst Rev. 2023 Oct 6;12(1):187. doi: 10.1186/s13643-023-02351-w. Syst Rev. 2023. PMID: 37803451 Free PMC article.
Cited by
-
Task-Specific Transformer-Based Language Models in Health Care: Scoping Review.JMIR Med Inform. 2024 Nov 18;12:e49724. doi: 10.2196/49724. JMIR Med Inform. 2024. PMID: 39556827 Free PMC article.
References
-
- Ott BL. The age of Twitter: Donald J. Trump and the politics of debasement. Critical Stud Media Commun. 2016 Dec 23;34(1):59–68. doi: 10.1080/15295036.2016.1266686. - DOI
-
- Tang Y, Hew KF. Using Twitter for education: beneficial or simply a waste of time? Comput Educ. 2017 Mar;106:97–118. doi: 10.1016/j.compedu.2016.12.004. - DOI
-
- Justinia T, Alyami A, Al-Qahtani S, Bashanfar M, El-Khatib M, Yahya A, Zagzoog F. Social media and the orthopaedic surgeon: a mixed methods study. Acta Inform Med. 2019 Mar;27(1):23–8. doi: 10.5455/aim.2019.27.23-28. http://europepmc.org/abstract/MED/31213739 AIM-27-23 - DOI - PMC - PubMed
-
- Hamasha AA, Alghofaili N, Obaid A, Alhamdan M, Alotaibi A, Aleissa M, Alenazi M, Alshehri F, Geevarghese A. Social media utilization among dental practitioner in Riyadh, Saudi Arabia. Open Dentistry J. 2019 Feb 28;13(1):101–6. doi: 10.2174/1874210601913010101. - DOI
LinkOut - more resources
Full Text Sources
Miscellaneous
