

Shifting machine learning for healthcare from development to deployment and from models to data
- PMID: 35788685
- PMCID: PMC12063568
- DOI: 10.1038/s41551-022-00898-y
Shifting machine learning for healthcare from development to deployment and from models to data
Abstract
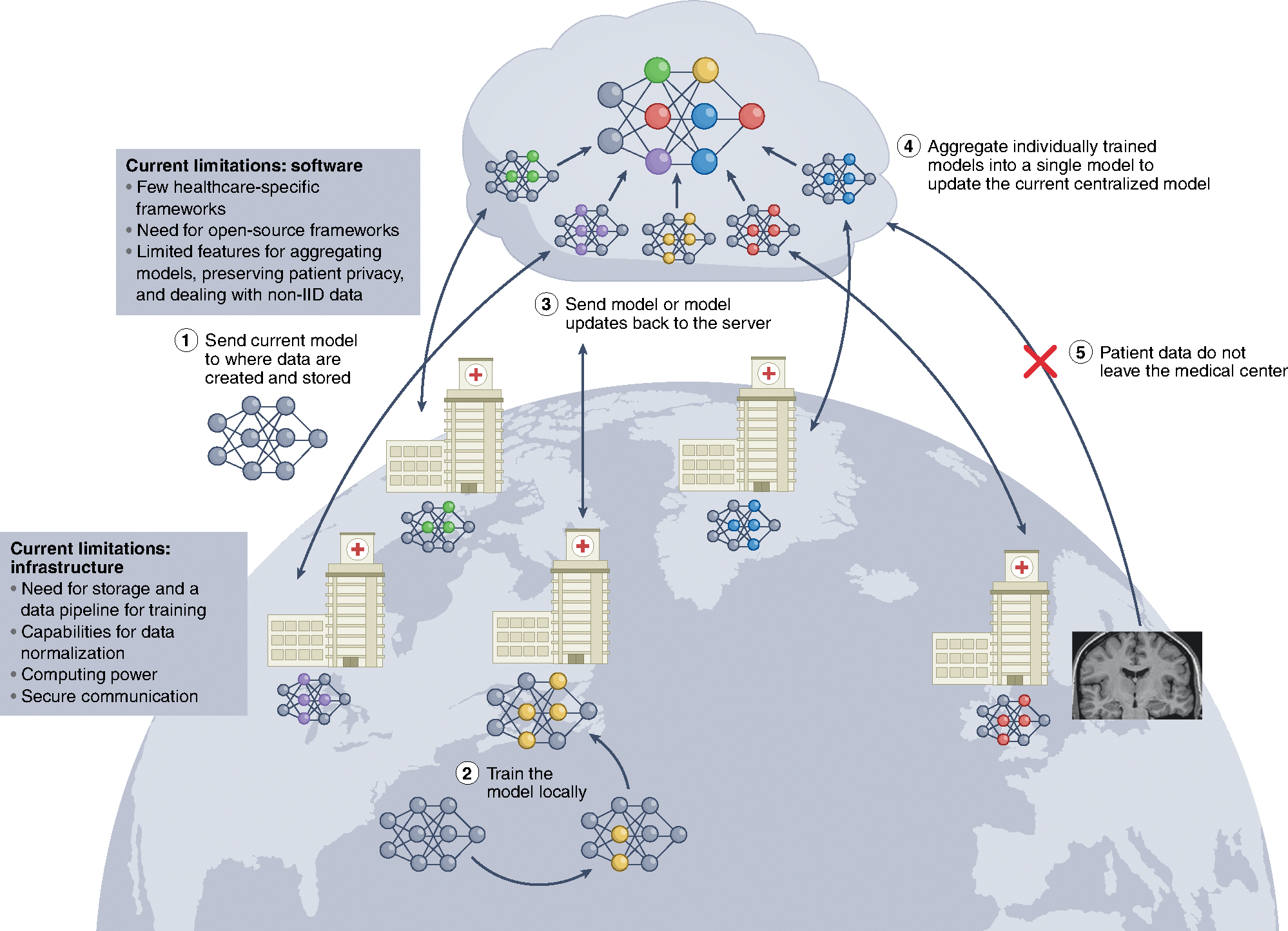
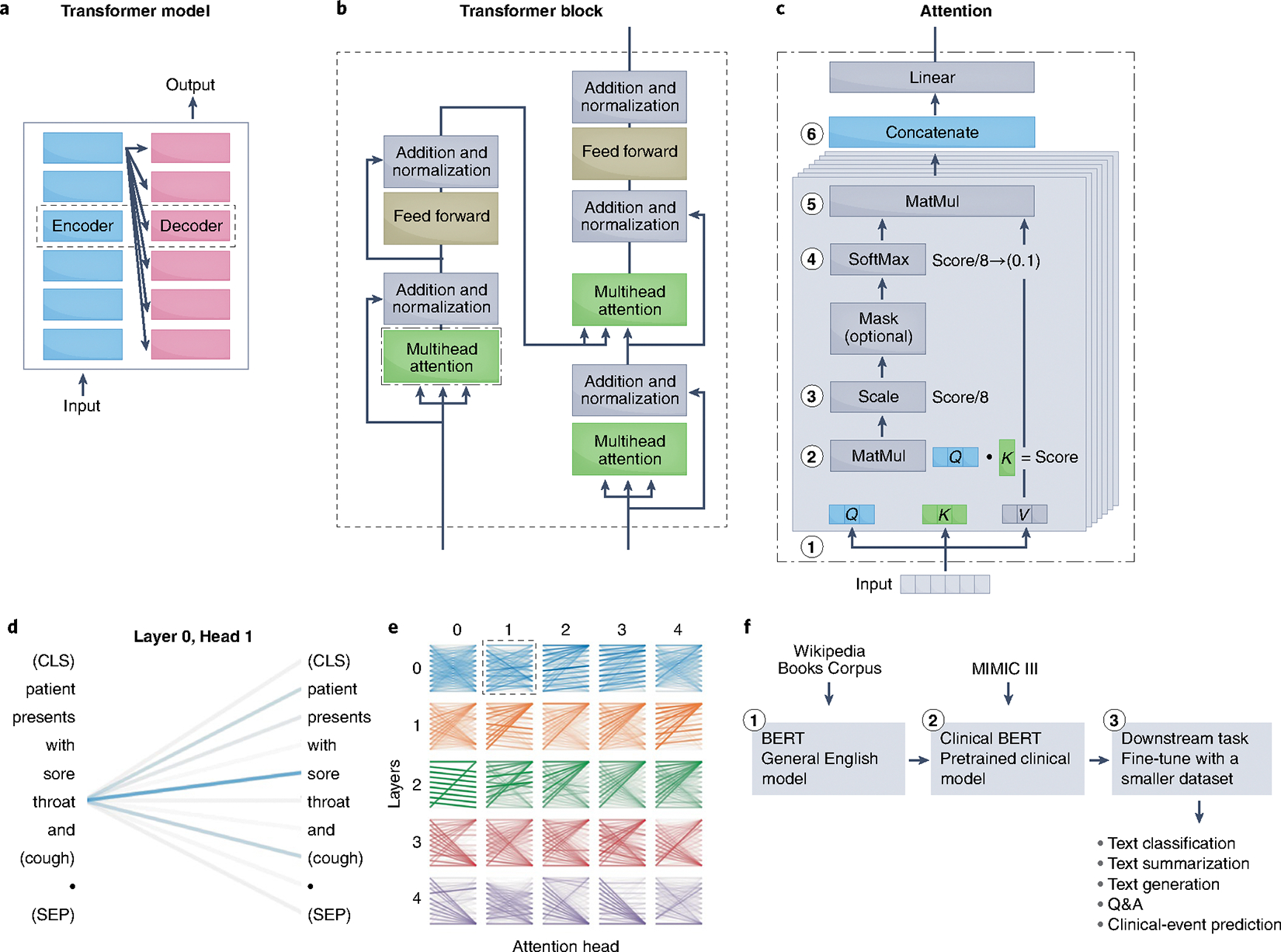
In the past decade, the application of machine learning (ML) to healthcare has helped drive the automation of physician tasks as well as enhancements in clinical capabilities and access to care. This progress has emphasized that, from model development to model deployment, data play central roles. In this Review, we provide a data-centric view of the innovations and challenges that are defining ML for healthcare. We discuss deep generative models and federated learning as strategies to augment datasets for improved model performance, as well as the use of the more recent transformer models for handling larger datasets and enhancing the modelling of clinical text. We also discuss data-focused problems in the deployment of ML, emphasizing the need to efficiently deliver data to ML models for timely clinical predictions and to account for natural data shifts that can deteriorate model performance.
© 2022. Springer Nature Limited.
Conflict of interest statement
Competing interests
J.C.W. is a co-founder and scientific advisory board member of Greenstone Biosciences. The other authors declare no competing interests.
Figures


References
-
- Topol EJ High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 25, 44–56 (2019). - PubMed
-
- Gulshan V et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316, 2402–2410 (2016). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
