

Comparing trained and untrained probabilistic ensemble forecasts of COVID-19 cases and deaths in the United States
- PMID: 35791416
- PMCID: PMC9247236
- DOI: 10.1016/j.ijforecast.2022.06.005
Comparing trained and untrained probabilistic ensemble forecasts of COVID-19 cases and deaths in the United States
Abstract
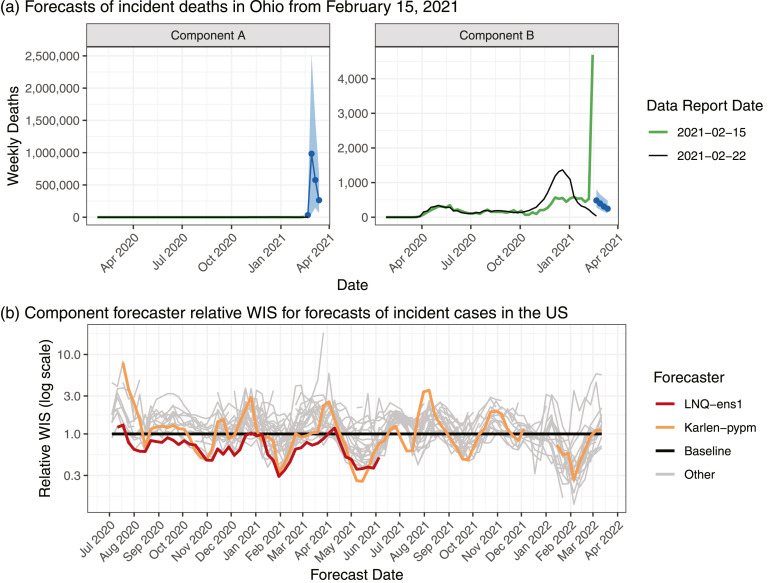
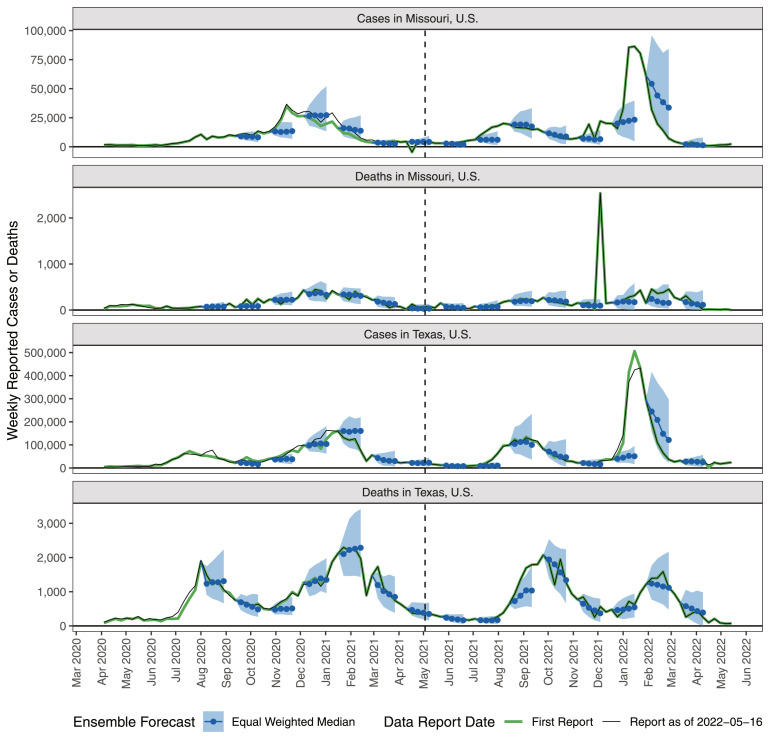
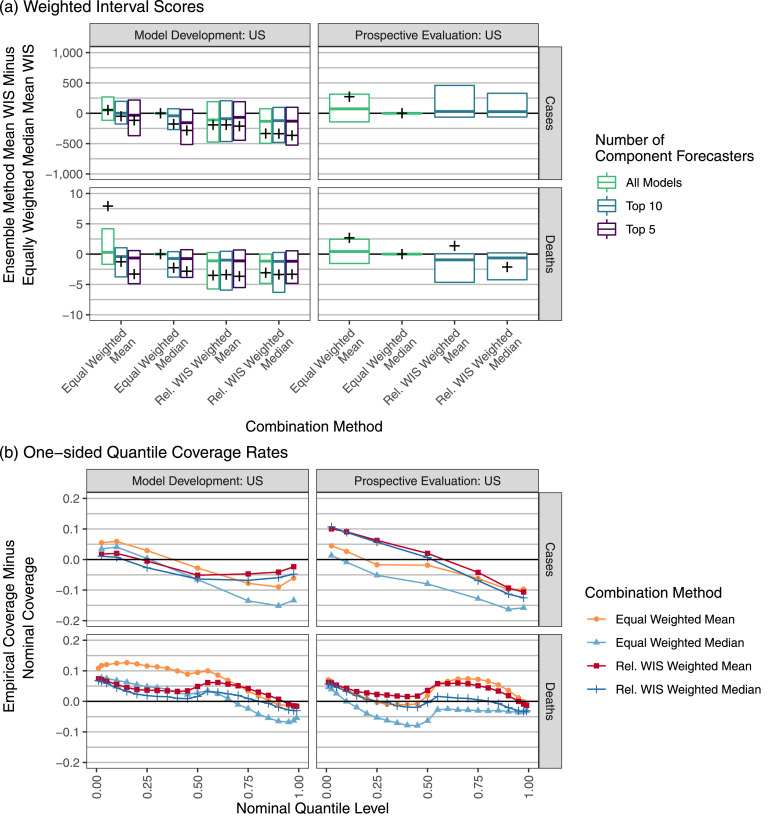
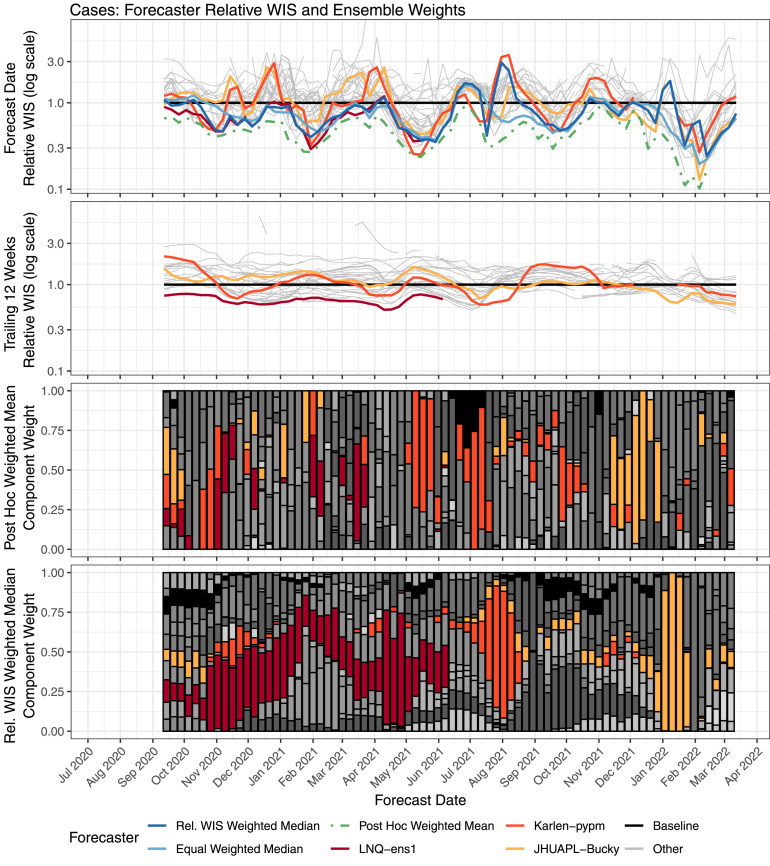
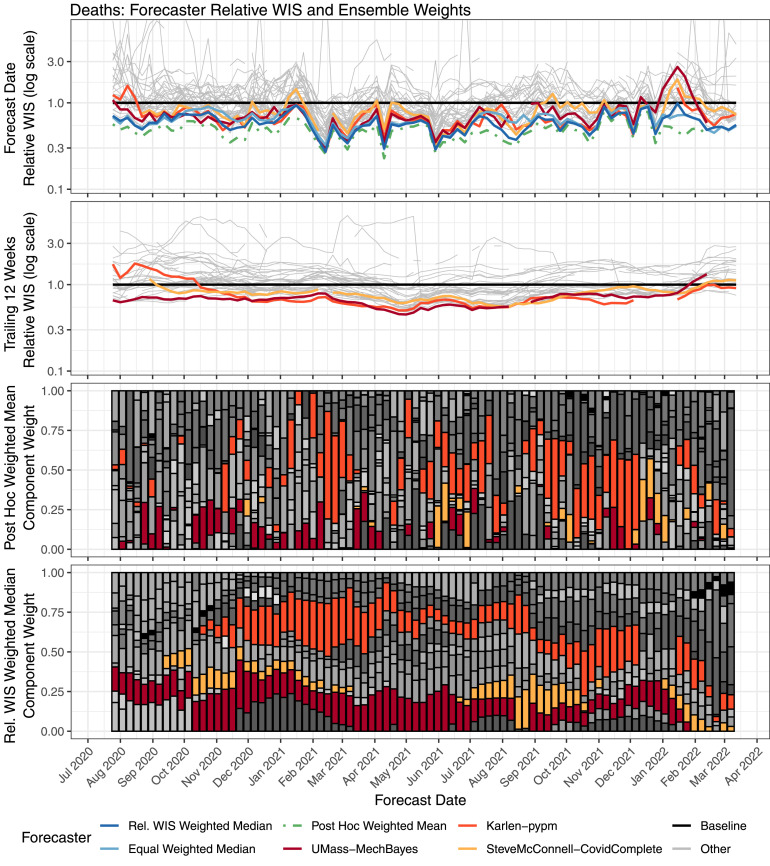
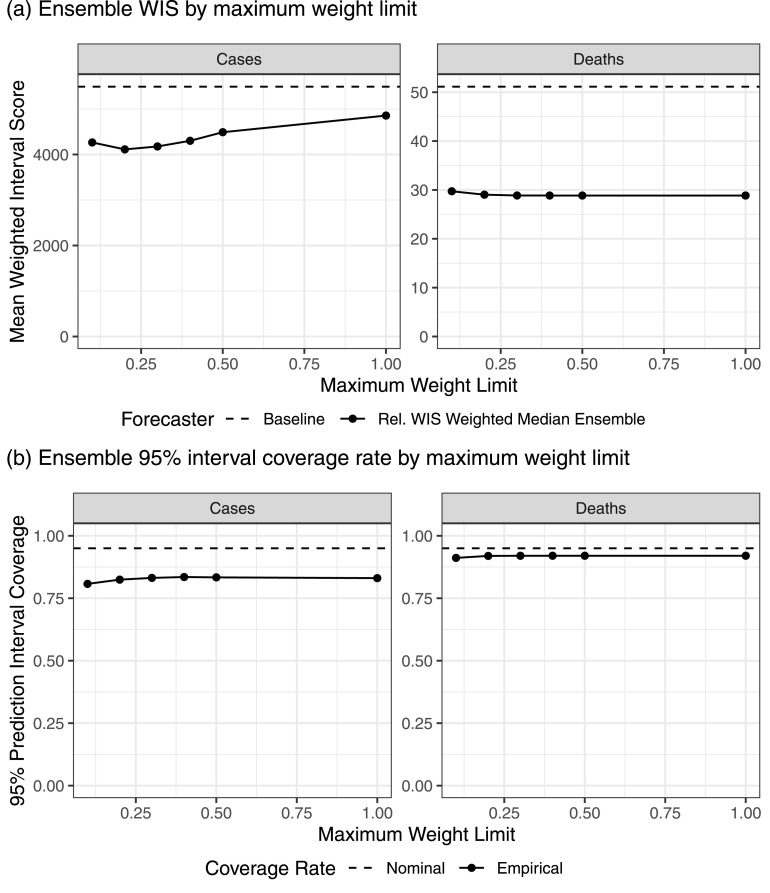
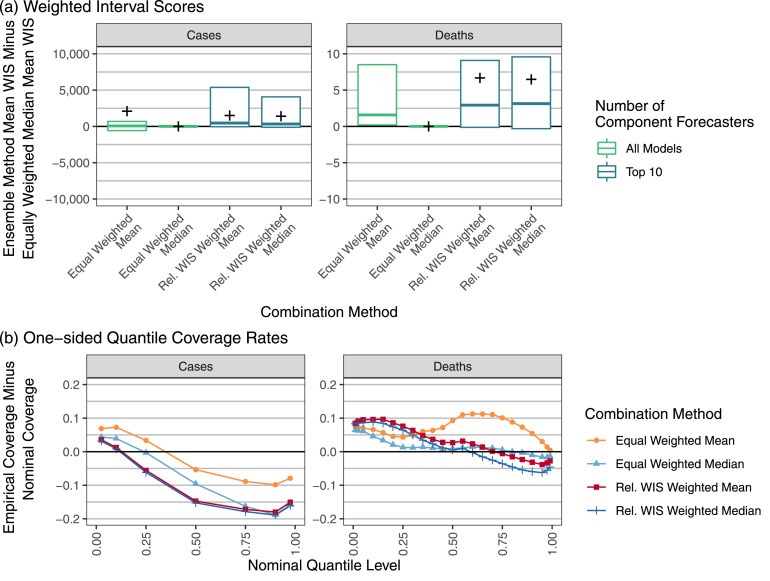
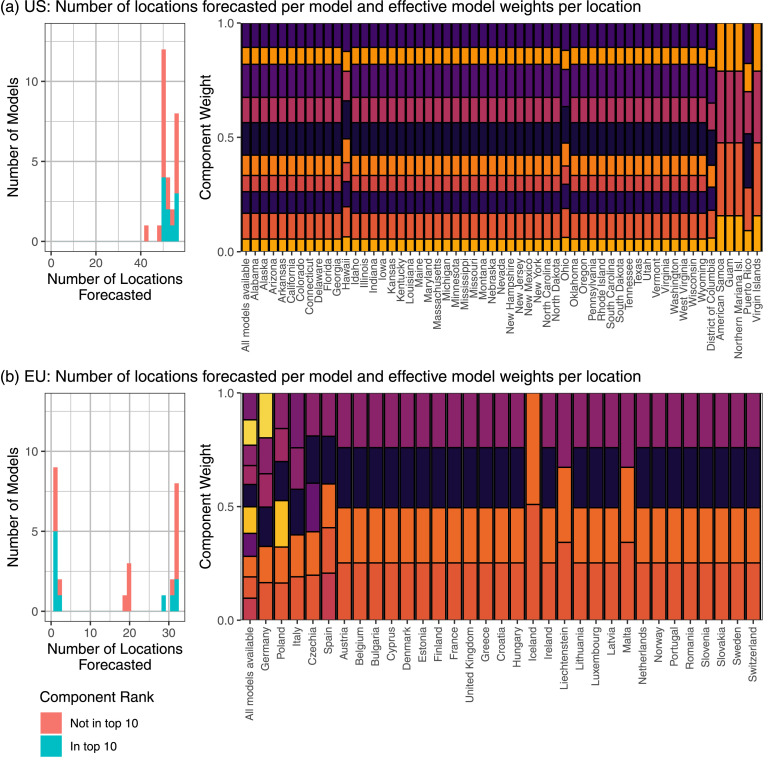
The U.S. COVID-19 Forecast Hub aggregates forecasts of the short-term burden of COVID-19 in the United States from many contributing teams. We study methods for building an ensemble that combines forecasts from these teams. These experiments have informed the ensemble methods used by the Hub. To be most useful to policymakers, ensemble forecasts must have stable performance in the presence of two key characteristics of the component forecasts: (1) occasional misalignment with the reported data, and (2) instability in the relative performance of component forecasters over time. Our results indicate that in the presence of these challenges, an untrained and robust approach to ensembling using an equally weighted median of all component forecasts is a good choice to support public health decision-makers. In settings where some contributing forecasters have a stable record of good performance, trained ensembles that give those forecasters higher weight can also be helpful.
Keywords: COVID-19; Ensemble; Epidemiology; Health forecasting; Quantile combination.
© 2022 The Authors.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
References
-
- Bengtsson H. 2020. Matrixstats: Functions that apply to rows and columns of matrices (and to vectors) R package version 0.57.0.
-
- Bracher J., Wolffram D., Deuschel J., Görgen K., Ketterer J.L., Ullrich A., Abbott S., Barbarossa M.V., Bertsimas D., Bhatia S., Bodych M., Bosse N.I., Burgard J.P., Castro L., Fairchild G., Fuhrmann J., Funk S., Gogolewski K., Gu Q.…Schienle M. A pre-registered short-term forecasting study of COVID-19 in Germany and Poland during the second wave. Nature Communications. 2021;12(1):5173. - PMC - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources